《数据分析面试》专题
-
 京东方大数据面试
京东方大数据面试7.22一面 spark的底层原理 spark yarn client和yarn cluster的区别 dataframe如何创建 数仓项目中用了几个节点,各个组件如何部署的 HA介绍一下 数仓分层介绍 hadoop的一些命令 hadoop如何更改文件所有者 kafka的监控 linux命令,vim编译器的命令 集群间节点是如何通信的 core-site文件一般配置什么内容 ranger权限管理的
-
数据库系统 - 面试题
MySQL有哪些日志,分别是什么用处? mysql日志一般分为5种 错误日志:-log-err (记录启动,运行,停止mysql时出现的信息) 二进制日志:-log-bin (记录所有更改数据的语句,还用于复制,恢复数据库用) 查询日志:-log (记录建立的客户端连接和执行的语句) 慢查询日志: -log-slow-queries (记录所有执行超过long_query_time秒的所有查询)
-
 美团数据产品面试
美团数据产品面试日常实习 一面 7.31 1 自我介绍 2 格力实习项目介绍(深挖) 3 个人负责了哪个功能点 4 所做模型的衡量指标是什么 5 团队协作情况 6 字节实习工作内容、考核指标 7 sql 查询语句执行顺序 8 窗口函数 9反问 二面8.2 1 自我介绍 2 个人求职方向规划 3 为什么不投本专业对口岗位(我是物流本硕) 4 怎么考虑去的格力那边实习 5 所做项目具体介绍 6 讲述所做的算法框架 7
-
python实现的分析并统计nginx日志数据功能示例
本文向大家介绍python实现的分析并统计nginx日志数据功能示例,包括了python实现的分析并统计nginx日志数据功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现的分析并统计nginx日志数据功能。分享给大家供大家参考,具体如下: 利用python脚本分析nginx日志内容,默认统计ip、访问url、状态,可以通过修改脚本统计分析其他字段。 一、脚本运行方式
-
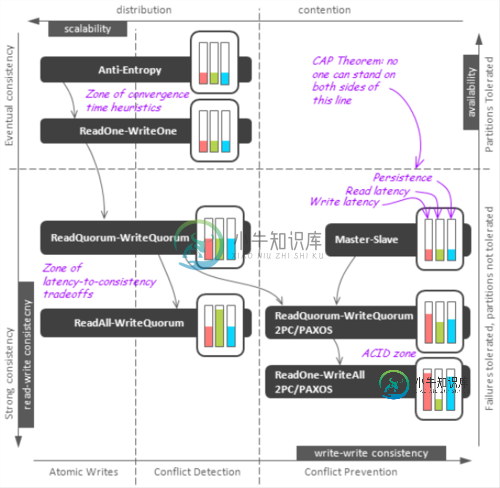 深入解析NoSQL数据库的分布式算法(图文详解)
深入解析NoSQL数据库的分布式算法(图文详解)本文向大家介绍深入解析NoSQL数据库的分布式算法(图文详解),包括了深入解析NoSQL数据库的分布式算法(图文详解)的使用技巧和注意事项,需要的朋友参考一下 尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践。在这篇文章里,我将针对NoSQL数据库的分布式特点进行一些系统化的描述。 系统的可扩展性是推动NoSQL运动发展的的主要
-
IC角色,用于创建物理表,分析SAP HANA中的数据
本文向大家介绍IC角色,用于创建物理表,分析SAP HANA中的数据,包括了IC角色,用于创建物理表,分析SAP HANA中的数据的使用技巧和注意事项,需要的朋友参考一下 要创建物理表,需要上传数据并创建信息视图IC_MODELER角色。如果仅为这些用户分配IC_PUBLIC角色,则他们可以查看其他用户创建的信息视图,但不能创建自己的视图。
-
将聚类分析结果转换为数据。R中的帧格式
这篇文章来自于这个主题,使用R对单词中的相同模式进行分类。解决方案很好,但是我需要数据帧格式。数据是相同的 我们来进行聚类分析 代码完成后,如何将结果转换为data.frame? 预期产出 s=as。数据(函数(…,row.names=NULL,check.rows=FALSE,check.names=TRUE)中的frame(拆分(文本,集群))错误:参数表示行数不同:7,1,2 所以理想的输出
-
用Java进化生物学库(JEBL)分析数据注释树节点
我使用JEBL和跌跌撞撞的API,因为我找不到非常清晰的留档或示例。 我想做的是在一棵树上阅读,树上的树枝标注了长度,节点也标注了长度。然后,我应该能够获取树叶并向上遍历树,同时检查节点的注释(使用JEBL遍历很容易,我的问题实际上是注释)。 它们是系统发育树,其中每个节点都是一个物种,注释将标记特定节点上是否存在某些基因,并且可能有足够少的基因,一个字符串就足够了(例如,如果有三个基因a、B和C
-
 上海招商银行信用卡中心数据分析岗避雷
上海招商银行信用卡中心数据分析岗避雷职位名为数据分析 看到职位要求的:excel,python,Java,爬虫,数据分析等硬性技能,还有一些项目管理这些 当时没有把项目管理这些放在心上 后来证明这是一个大坑 我就去面试了 到了地方 先花几分钟写了一个简历,然后做了半个小时的性格测试 性格测试120道题,选项在手机上,题干是语音播报的,需要自己听 个人评价:纯属浪费时间 工作人员引我去了一个小会议室,面试官在开会,等了10分钟面试官
-
 网易互娱大数据研发工程师面试经验分享
网易互娱大数据研发工程师面试经验分享本人社招,面试大数据研发工程师岗位,一共三轮面试。 1、一面(技术面),约40分钟,面试题如下: (0)自我介绍,别照着简历说,补充说些简历上没有的,比如哪里人、兴趣爱好、优势有哪些等。 (1)笔试,编程题,语言自选,题目:输入一个字符串,找出其中的整数,按升序排序后输出,多个相连的数字为一个整数,排序可用类库自带方法。 实现很简单,这里就不提供答案了。 (2)笔试,SQL编程,
-
1.3.4.3 行为分析分群
用户分群是一种用户运营和用户分析手段,通过对特定用户进行定向投放实现精细化运营,通过对某一个用户群体分析发现不同用户的特征以及偏好。HubbleData的分群区别于传统的标签体系,支持产品策划或者运营人员通过行为数据指定用户,具体使用场景包括: 策划,交互或者视觉同事,通过对比不同分群用户对产品的使用,发现用户特征以优化产品设计 运营通过用户分群定向投放,实现用户的精细化运营 HubbleData
-
1.5.3.2.13.3 选址分区分析
选址分区分析是为了确定一个或多个待建设施的最佳或最优位置,使得设施可以用一种最经济有效的方式为需求方提供服务或者商品。选址分区不仅仅是一个选址过程,还要将需求点的需求分配到相应的新建设施的服务区中,因此称之为选址与分区。 设置选址分区分析参数,包括交通网络分析通用参数、途径站点等。 //设置设施点的资源供给中心 var supplyCenterType_FIXEDCENTER = SuperMap
-
使用分配分析器
使用分配分析器工具来查找未被正确地垃圾收回收,并继续保留在内存中的对象。 分配分析器如何工作 allocation profiler(分配分析器)结合了堆分析器中快照的详细信息以及Timeline(时间轴)面板的增量更新以及追踪信息。与这些工具相似,追踪对象堆的分配过程包括开始记录,执行一系列操作,以及停止记录并分析。 分配分析器在记录中周期性生成快照(频率为每50毫秒),并且在记录最后停止时也会
-
用于有效连接Spark数据帧/数据集的分区数据
我需要根据一些共享的键列将许多数据帧连接在一起。对于键值RDD,可以指定一个分区程序,以便具有相同键的数据点被洗牌到相同的执行器,因此连接更有效(如果在之前有与洗牌相关的操作)。可以在火花数据帧或数据集上做同样的事情吗?
-
 华为机试:数据分类处理
华为机试:数据分类处理