《数据分析面试》专题
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
 大数据数仓高级面试题 4
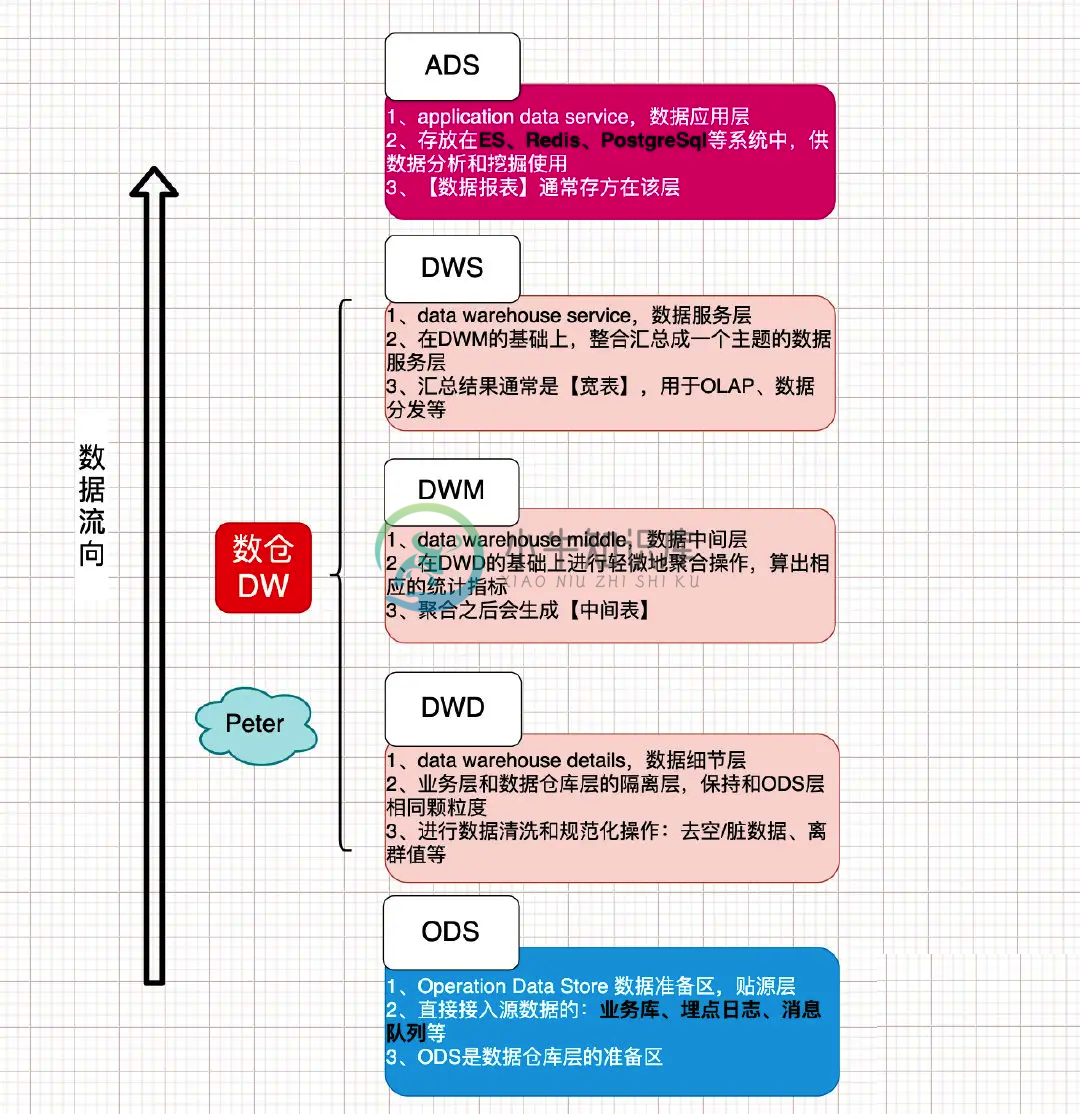
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
 大数据数仓高级面试题 2
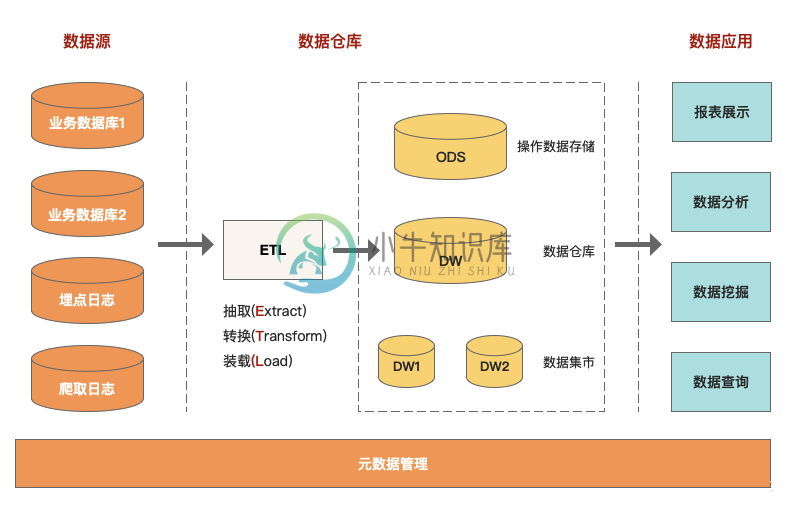
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
 兴业数金 数据工程师 综合面试(2面)
兴业数金 数据工程师 综合面试(2面)史无前例的快,整个面试流程,从进去会议室到结束,共计6分钟! 不知道是不是拿我刷KPI 简单记录下 自我介绍 为什么想来上海 自身的不足 有没有想过怎么去改变 有什么想问的?(问了两个问题) #兴业数金校招##面试流程#
-
JS解析XML实例分析
本文向大家介绍JS解析XML实例分析,包括了JS解析XML实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS解析XML的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的javascript程序设计有所帮助。
-
排序后的数据帧分区数?
spark如何在使用< code>orderBy后确定分区的数量?我一直以为生成的数据帧有< code > spark . SQL . shuffle . partitions ,但这似乎不是真的: 在这两种情况下,spark都< code >-Exchange range partitioning(I/n ASC NULLS FIRST,200),那么第二种情况下的分区数怎么会是2呢?
-
JS小数转换为整数的方法分析
本文向大家介绍JS小数转换为整数的方法分析,包括了JS小数转换为整数的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS小数转换为整数的方法。分享给大家供大家参考,具体如下: 一、小数转为整数 floor:下退 Math.floor(12.9999) = 12 ceil:上进 Math.ceil(12.1) = 13; round: 四舍五入 Math.round(12.5) =
-
旋转整数数组的递归方法分析
在LeetCode上解决数组旋转时,我编写了一个递归算法来解决这个问题: 给定一个数组,将数组向右旋转k步,其中k为非负。 例1: 输入: Nums=[1,2,3,4,5,6,7], k=3输出:[5,6,7,1,2,3,4]说明:向右旋转1步:[7,1,2,3,4,5,6]向右旋转2步:[6,7,1,2,3,4,5]旋转3步向右:[5,6,7,1,2,3,4] 例2: 输入:nums=[-1,-
-
 阿里暑期数分一面面经
阿里暑期数分一面面经自我介绍 深挖数分实习经历 因为自我介绍抛的是指标异动分析和sql,就着重被问了这些。 怎么做指标异动分析的? 讲述一个数据项目? 了解机器学习算法嘛?讲几个分类算法,介绍一下决策树和随机森林的原理? 我简历可是一个字都没写机器学习,勉强是把之前学过一些理论的模型说了俩,但根本聊不下去,反问的时候问说是看下深度,岗位也有偏业务分析的,模型基础好的会推荐到数开或数科,但偏好综合能力强的。 聊我天坑专
-
 微派秋招数分一面面经
微派秋招数分一面面经#数据分析# #秋招# 秋招第二个面试 武汉的一家公司,贪吃蛇大作战就是它们的产品,读高中的时候经常玩 1.深挖实习经历,没怎么问项目经历 2.数据埋点的一个问题,针对用户结束一局游戏如何定义对应的埋点事件(答的退出按钮触达) 3.针对用户结束一局游戏,可以考察哪些埋点指标 4.介绍假设检验、p值、两类错误 5.ab测试相关的一个问题,推出一个活动,考察次日留存与推出前相比是否有显著性差异,用什么
-
 快手数分秋招一面面经
快手数分秋招一面面经#秋招# #数据分析# 1.深挖实习经历,重点讲了一个数据埋点的,没怎么给压力,主要就问了下跟开发,业务对接时出现了哪些问题,然后怎么解决的 2.问了下实习中碰到的归因、异动分析,没啥这样的经历,所以很快跳过 3.短视频相关的异动分析,这个没啥,按着异动分析的逻辑来就行 4.留存率sql,这个也比较基础,很快过 5.时间序列和回归的区别,这个答的很烂,之前好像准备过差不多的,但是太久没准备面试了,
-
 美团-快驴商业分析-实习面经
美团-快驴商业分析-实习面经面试时长约一个钟 1. 面试官介绍部门及小组情况 2. 自我介绍 3. 讲项目(40min) 深挖 深挖 深挖 中间穿插着一些ab test/ 统计学基础 比如 ab sample size/ 一二类错误定义/ outlier怎么办 / matching怎么做(lz简历提到才问的) 4. sql *2 口述 我本来写在ipad上 但是虚拟背景 直接全糊上 4. 反问 白天上班已经上懵了 根本没时间
-
 滴滴商业分析日常实习面经
滴滴商业分析日常实习面经bg:一段数分实习+中台运营 一面(25min): 1.自我介绍 2.简历中提到用过XGB模型,介绍一下:特征选了什么,最后的重要因素是什么(结合落地性),准确率多少 复盘:下次介绍的时候可以先明确自变量和因变量分别是什么,当时以为自己star法则说的还挺清楚的,结果输出一通之后,面试官的第一个问题就是x和y是什么...... 3.case题:目前滴滴在上线阶段,如何做好用户回流,有什么分析思路
-
利用入口页面做新访客分析
使用指南 - 数据报告 - 访问分析 - 利用入口页面做新访客分析 访客都是通过入口页进入到网站,尤其对于新访客来说,入口页面网站的第一印象,新访客最多的入口页面值得重点分析。怎么分析访问入口报告里的新访客数据呢? 让我们先看下和新访客相关的指标有哪些: 访客数(UV):一天之内从该入口进入您网站的独立访客数(以Cookie为依据),一天内同一访客多次访问只计算1个。 新访客数:从该入口进入的独立