《数据分析面试》专题
-
 昇维旭 失效分析工程师 一面
昇维旭 失效分析工程师 一面1)说一下数电、模电里主要讲了哪些内容 2)说说对CMOS管的了解(原理、特性) 3)说说使用的SEM的品牌,以及对SEM工作原理的了解 #昇维旭##一面##失效分析工程师#
-
 美团商业分析日常实习面经
美团商业分析日常实习面经一面25min 1、自我介绍 2、python项目介绍 3、随机森林优劣势,怎么判断模型优劣的 4、数据清洗做了哪些工作 缺失值填充依据 5、上课讲的关于gmv的计算 6、淘宝 拼多多京东分析 7、抖音淘宝拼多多京东四家五年后发展排序 及原因 6、如果双十一gmv没达到要求,会怎么反思原因 7、sql能力 问了很基础的左连接右连接区别(没答上来 8、到岗时间 实习时长 9、为什么不想在现在这家公司
-
 长鑫存储缺陷分析研发二面
长鑫存储缺陷分析研发二面本来投的工艺整合研发,调到了缺陷分析研发 9.24 武汉线下一面 当天晚上收到通知说通过,二面面试官没来武汉,等待线上二面通知 9.28二面通知,9.29下午面试 有人知道是技术面还是hr面呀 本来以为是技术面,但是确认面试的界面写着"hr座谈",所以想问一下有没有朋友也缺陷分析研发明天二面的😟 #秋招##校招##长鑫存储##长鑫存储面试#
-
 字节的测试开发岗位面试经验分析
字节的测试开发岗位面试经验分析字节的测试开发岗位面试经验分析 字节面试 蚂蚁面试 面试总结 2021年底到新加坡,歇了4个月开始找工作,分别投了字节跳动、蚂蚁金服2家。2家都是4轮面试,前3轮是技术面、最后一轮HR面试。幸运的通过了这2家的面试,分享一下面试经验。希望能帮助到有需要的人。 字节面试 测试开发面试4轮,前3轮都属于技术面试,每次70分钟左右,最后一轮HR面试(HR面试你只要不犯混就行)。直接贴上3轮面试问题: 1
-
Golang将JSON数组解析为数据结构
问题内容: 我正在尝试解析一个包含JSON数据的文件: 由于这是带有动态键的JSON数组,因此我认为我可以使用: 但是,我无法使用来解析文件: 将包含JSON数据的文件解析为Go结构的最简单方法是将数组(仅字符串类型转换为字符串类型)? 编辑: 要进一步详细说明可接受的答案-的确,我的JSON是地图数组。为了使我的代码正常工作,该文件应包含: 然后可以将其读入 问题答案: 这是因为您的json实际
-
列车\u测试\u拆分而不是拆分数据
有一个数据帧,它总共由14列组成,最后一列是整数值为0或1的目标标签。 我已经定义了- X=df。iloc[:,1:13]——由特征值组成 两者的长度相同,X是由13列组成的数据帧,shape(159880,13),y是具有shape(159880,)的数组类型 但是,当我在X,y上执行列车测试分割时,该功能无法正常工作。 下面是简单的代码- X_序列,y_序列,X_测试,y_测试=序列测试分割(
-
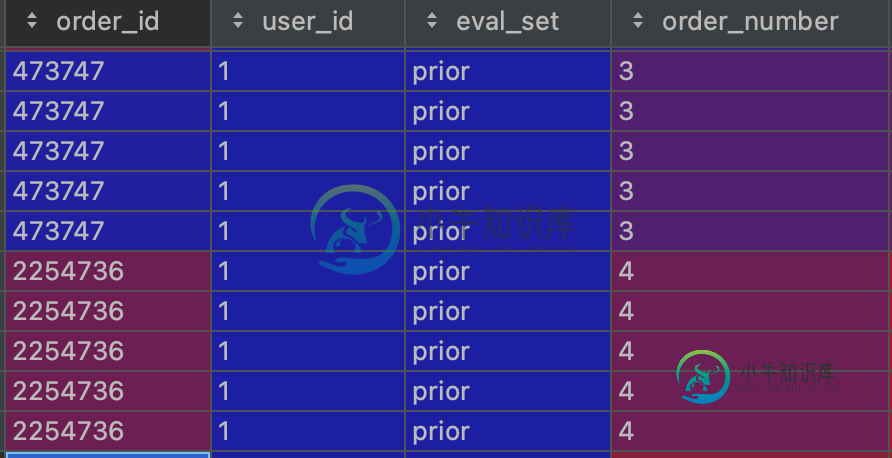 无环路分离数据帧
无环路分离数据帧我有一个包括客户篮子的数据集。我想用一个来分割每个用户篮。因此,我有一个列表,其中我应该使用一个循环来获得一个,以便在pandas矢量化中使用它,如下所示: 我使用函数而不是,但它确实很慢。 根据我的orders列表,它包括百万个元素,我应该使用orders列表的元素来获取用户的篮子。 实际上,我想通过来分割每个用户的篮子,而要这样做,我需要对大小为4000000的orders列表进行迭代,所以这
-
第三部分:衍生数据
在本书的第一部分和第二部分中,我们自底向上地把所有关于分布式数据库的主要考量都过了一遍。从数据在磁盘上的布局,一直到出现故障时分布式系统一致性的局限。但所有的讨论都假定了应用中只用了一种数据库。 现实世界中的数据系统往往更为复杂。大型应用程序经常需要以多种方式访问和处理数据,没有一个数据库可以同时满足所有这些不同的需求。因此应用程序通常组合使用多种组件:数据存储,索引,缓存,分析系统,等等,并实现
-
分配pandas数据框列dtypes
问题内容: 我想在中设置多列的(我有一个文件,我不得不手动将其解析为列表列表,因为该文件不适合) 我懂了 我可以设置它们的唯一方法是循环遍历每个列变量并使用重铸。 有没有更好的办法? 问题答案: 从0.17开始,您必须使用显式转换: (如下所述,在0.17中已不再使用“魔术”了) 您可以将它们应用于要转换的每一列: 并确认dtype已更新。 适用于大熊猫0.12-0.16的旧/建议答案:您可以用来
-
按X列分组数据框
问题内容: 我有一个数据框,我想将一个函数应用于每2列(或3列,它是变量)。 例如,下面的示例,我想将均值函数应用于0-1、2-3、4-5,.... 28-29列 问题答案: 也可以使用,并且可以接受一系列的组标签。如果您的列在您的示例中那样是方便的范围,那么这很简单: (这是因为给出了。) 即使我们不是很幸运,我们仍然可以自己建立适当的小组:
-
 Python数据集切分实例
Python数据集切分实例本文向大家介绍Python数据集切分实例,包括了Python数据集切分实例的使用技巧和注意事项,需要的朋友参考一下 在处理数据过程中经常要把数据集切分为训练集和测试集,因此记录一下切分代码。 测试代码如下: 结果如下: 从上图可以看出,原数据集按照5:1被随机分为两部分。但是此种方法存在一个缺点–每次调用次函数切分同一个数据集切分出来的结果都不一样,因此常在np.random.permutatio
-
用elasticsearch分离数据访问
我刚刚开始了解弹性搜索,我想知道它是否适合我的情况: 考虑一个系统,公司(有多名员工)可以注册和管理他们的客户,并向他们的客户发送文件。 现在,我想让公司能够搜索他们的文档,但只搜索他们的文档,而不是其他公司的文档。换言之:如何分离这些公司的数据进行搜索?如何使用elasticsearch实现这一点? 这种分离是由elasticsearch本身处理的吗?一、 e.我的系统中的公司和elastics
-
按列值拆分数据帧
我有列。 如何根据值将其拆分为2? 第一个将包含
-
Kafka:主题与分区数据
通过Kafka文档和各种其他资源,我了解到Kafka中的消息被组织成主题。此外,主题可以分解为多个分区,每个分区可以托管在不同的服务器上。这提供了冗余和可伸缩性。 我不确定这里的“破碎”这个词是什么意思。这是否意味着,如果添加到主题的消息是,例如“1 2 3 4 5 6 7”,那么在将其分解为分区后,我们将有一个分区仅包含整个主题的子部分。就像一个分区有“1 2 3”,而另一个分区有“4 5 6”
-
Spring数据可分页性能
好吧,这很烦人,我真的不知道该怎么解决,所以事情是这样的。 获得了一个返回分页数据的应用程序,如下所示: 检索结果需要花费很长时间。 但是,如果我调用like(使用上面安装的相同可分页对象): 并且存储库上有: 而且,结果马上就会出现。 我假设,对于第一种永远需要的情况,Spring首先检索所有数据(不限制行),然后返回一个带有结果数量信息的页面。 不知道是否与注释有关。 我使用的是2.3.0。顺