《数据分析面试》专题
-
 OPPO 数据产品岗面试面经
OPPO 数据产品岗面试面经一面 1、自我介绍 2、介绍一下实习 3、深挖上一段实习,尤其针对其中的数据问题,会从几个维度出发 4、数据来源,如何处理,使用什么工具,处理后如何探索,得到什么结论,结论正确性,结论价值。如果数据源复杂度增加,怎么处理,如何分析。 5、扩展了一个上段实习的具体问题,数据维度增加,复杂性增强,后续如何预测? 二面 1、自我介绍 2、介绍一下实习,问了一些细节,但没做扩展和深挖 3、在上一段实习
-
如何拆分部分数据,但部分数据在MySQL、PSQL中保持不变
我将列的一些数据保存如下: 我需要的是所有的中文单词,我们不需要英文单词和'-',但不是所有的值都是带和英文单词的,所以我不能用SQL下面,有没有人知道怎么实现?
-
数据框架-连接/分组依据-聚集-分区
我可能对加入/组By-agg有一个天真的问题。在RDD的日子里,每当我想执行a. groupBy-agg时,我曾经说reduceByKey(PairRDDFunctions)带有可选的分区策略(带有分区数或分区程序)b.join(PairRDDFunctions)及其变体,我曾经有一种方法可以提供分区数量 在DataFrame中,如何指定此操作期间的分区数?我可以在事后使用repartition(
-
面向小数据集构建图像分类模型
文章信息 本文地址:http://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html 本文作者:Francois Chollet 概述 在本文中,我们将提供一些面向小数据集(几百张到几千张图片)构造高效、实用的图像分类器的方法。 本文将探讨如下几种方法: 从图片中直接训练一个
-
Apache Scala/Python Spark 2.4.4:按年份范围分组数据以生成/分析新特性
下面是我为特性工程生成的数据框架,现在为了驱动另一个特性,我试图创建列,其中我希望创建一个具有3年范围的列,并通过聚合值。 例如:对于项目编号7010032,我们将在新的列和列中有一个具有1995-1996-1997值的行,这些年的PurchaseRatio值将在相应的行中汇总。接下来,我将在接下来的3年中也这样做,即1996-1997-1998,1997-1998-1999等。 此外,该项目有一
-
分析Android L的数据失败。不支持的主要部分。次要版本51.0
在为Eclipse安装了ADT插件之后,我尝试制作了一个新的Hello world Android应用程序。 但我在尝试打开一个新的Android应用程序时遇到了以下错误。我正在使用JDK7.0和JRE7.0。我最初使用的是JDK6.0,但遇到了同样的错误,因此我卸载了它,安装了JDK7.0,并分别更改了路径设置。 错误显然是: 为Android L(预览版)加载数据遇到了问题。分析Android
-
PHP数组函数array_multisort()用法实例分析
本文向大家介绍PHP数组函数array_multisort()用法实例分析,包括了PHP数组函数array_multisort()用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了PHP数组函数array_multisort()用法。分享给大家供大家参考,具体如下: 有时候我们需要对二维数组的某个键的值进行排序,这里就是讨论这个问题。我们可以使用array_multisort()
-
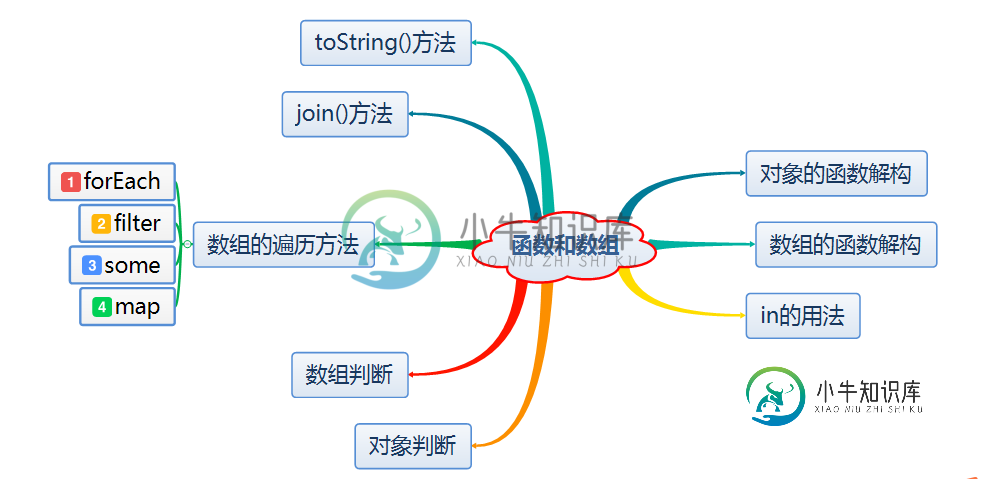 ES6函数和数组用法实例分析
ES6函数和数组用法实例分析本文向大家介绍ES6函数和数组用法实例分析,包括了ES6函数和数组用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了ES6函数和数组用法。分享给大家供大家参考,具体如下: 1.对象的函数解构 ES6为我们提供了这样的解构赋值使在前后端分离时,后端返回来JSON格式的数据,前端可以直接把这个JSON格式数据当作参数,传递到函数内部进行处理。比如: 结果为: 2.数组的函数解构 声
-
ES分析器,它也标记数字,数字
问题内容: 我正在使用Elasticsearch内置的简单分析器https://www.elastic.co/guide/en/elasticsearch/reference/1.7/analysis- simple- analyzer.html ,其中使用了小写标记器。和文本 Apple 8 IS Awesome 以以下格式标记。 您可以清楚地看到,它缺少对数字进行标记的功能,因此,如果现在仅使
-
按数据库分段Redis
问题内容: 默认情况下,Redis配置了16个数据库,编号为0-15。这仅仅是名称间隔的一种形式,还是按数据库隔离会对性能产生影响? 例如,如果我使用默认数据库(0),并且有1000万个键,则最佳实践建议使用 keys 命令按通配符模式查找键效率低下。但是,如果我存储我的主键,也许是8个段键的前4个段,结果导致在单独的数据库(例如数据库3)中的键子集要小得多。Redis是将它们视为较小的一组密钥,
-
MySql中的分层数据
问题内容: 我有一个与父子关系的表,我需要递归查询的帮助 表结构 我正在尝试进行递归查询,但是我无法做到这一点,建议我应该如何查询数据库 问题答案: 正如上面所指出的,这并不是真正的递归,但是如果您知道最大需要深入多少步,则可以沿以下方向使用某些方法(也许使用PHP生成查询): 我首先将父ID设置为NULL而不是0,但这是个人喜好。 ^^在这种情况下,您需要走多远。 [ 下一点没有严格意义 ] 然
-
7.4.5. 用户数据分区
7.4.5.用户数据分区 对开发者和用户来讲,用户数据分区才是最重要的。用户数据都储存在这里,下载的应用程序储存在这里,而且所有的应用程序数据也都储存在这里。 用户安装的应用程序都储存在/data/app目录,而开发者关心的数据文件都储存在/data/data目录。在这个目录之下,每个应用程序对应一个单独的子目录,按照Java package的名字作为标识。从这里可以再次看出Java packag
-
使用Spring数据分页
我有一个类,它返回一个<代码>列表 在我的存储库中,我有一个可分页对象,它应该从第0页开始每页返回2个项目。它具有以下属性: 然后我创建一个页面 ... 这就是回归的原因: 我通过
-
Spring数据JPA分页HHH000104
我得到了存储库代码: 当我在该查询上运行测试时,我得到了以下Hibernate警告:
-
计数列分组依据
问题内容: 我有如下的SQL: 并得到结果: 我想总结每个部门的学生人数,如下所示: 我该如何编写sql? 问题答案: 尽管您似乎并未显示所有表格,但我只能假设还有每位学生的实际入学表格 如果您想要与每个学生相关联的每个部门的总数(这没有意义),则可能必须这样做… 我对“姓名”列的解释是学生的姓名,而不是班级实际讲师的姓名,因此,我进行子选择/加入。否则,就像其他人一样,只需要使用COUNT(*)