《大数据分析》专题
-
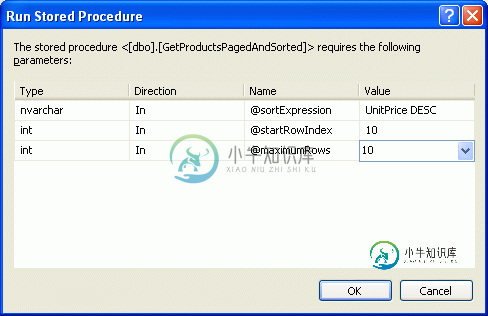 在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据
在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据本文向大家介绍在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据,包括了在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据的使用技巧和注意事项,需要的朋友参考一下 导言 和默认翻页方式相比,自定义分页能提高几个数量级的效率。当我们的需要对大量数据分页的时候就需要考虑自定义分页,然而实现自定义分页相比默认分页需要做更多工作。对于排序自定义分页数据也是这样,在本教程中我们就
-
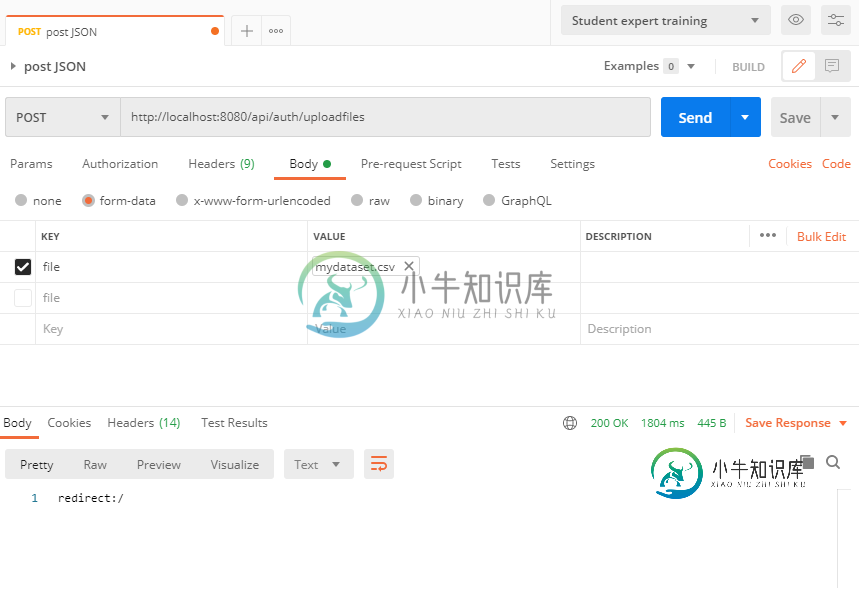 使用axios POST请求将JSON数据作为多部分/表单数据发送
使用axios POST请求将JSON数据作为多部分/表单数据发送以下API使用postman工作: Spring boot,后端代码: ReactJS,前端代码:我在中有对象数组。 触发功能的按钮: 我需要将我的前端(ReactJS)代码更改为,就像我使用postman发布请求一样。当前JS代码导致以下错误响应: Servlet。路径为[]的上下文中的servlet[dispatcherServlet]的service()引发了异常[请求处理失败;嵌套异常为o
-
将原始图像数据张贴为卷曲中的多部分/表单数据
我试图在PHP中使用multipart/form-data头发布一个带有cURL的图像,因为我发送到的API期望图像以多部分形式发送。 我没有问题与API与其他请求;只有张贴图像是一个问题。 我在客户端使用此表单: 请求头中的content-type现在显示正确了。但是图像似乎没有像API所期望的那样正确地发送。不幸的是,我无法访问API... 感谢您的帮助,谢谢
-
通过从配置单元表中读取数据创建的spark数据帧的分区数
我对spark数据帧的分区数量有疑问。 如果我有包含列(姓名、年龄、id、位置)的Hive表(雇员)。 如果雇员表有10个不同的位置。因此,在HDFS中将数据划分为10个分区。 如果我通过读取 Hive 表(员工)的整个数据来创建 Spark 数据帧(df)。 Spark 将为数据帧 (df) 创建多少个分区? df.rdd.partitions.size = ??
-
如何根据列表选择数据帧的一部分?[复制]
我有以下数据框: 我有以下一些位于美国的城市列表: 我想在数据框中只保留列表\u americ中国家的“名称”。因此,我尝试执行以下代码: 此代码产生以下错误: 我希望输出为:
-
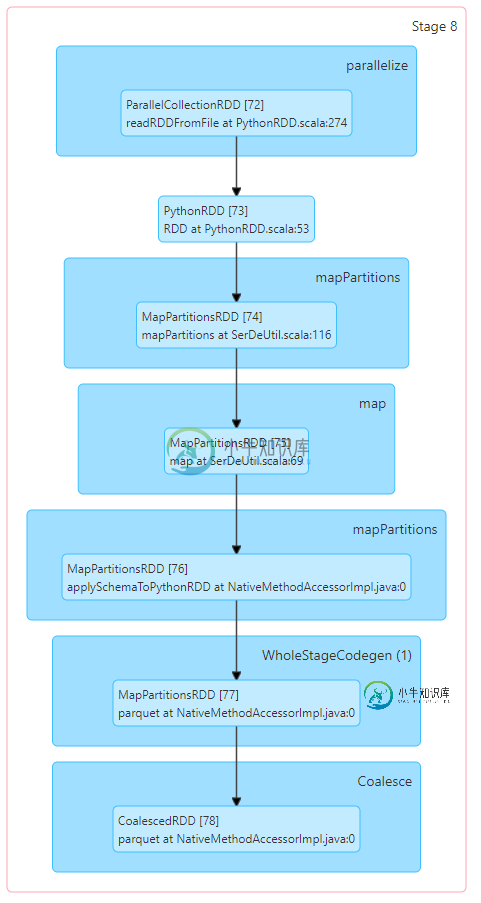 减少分区数量时,为什么spark数据帧重新分区比合并快?
减少分区数量时,为什么spark数据帧重新分区比合并快?我有一个包含100个分区的df,在保存到HDFS之前,我想减少分区的数量,因为拼花文件太小了( 它可以工作,但将过程从每个文件 2-3 秒减慢到每个文件 10-20 秒。当我尝试重新分区时: 这个过程一点也不慢,每个文件2-3秒。 为什么?在减少分区数量时,合并不应该总是更快,因为它避免了完全洗牌吗? 背景: 我将文件从本地存储导入spark集群,并将生成的数据帧保存为拼花文件。每个文件大约100
-
程序参数 - 参数分析
匹配可以用来解析简单的参数: use std::env; fn increase(number: i32) { println!("{}", number + 1); } fn decrease(number: i32) { println!("{}", number - 1); } fn help() { println!("usage: match_args <stri
-
如何使用dplyr在R数据框中选择具有分组分组的变量的最小值或最大值的行?
本文向大家介绍如何使用dplyr在R数据框中选择具有分组分组的变量的最小值或最大值的行?,包括了如何使用dplyr在R数据框中选择具有分组分组的变量的最小值或最大值的行?的使用技巧和注意事项,需要的朋友参考一下 如果R数据帧包含具有许多组级别的组变量,则很难根据组级别找到离散变量或连续变量的最小值和最大值。但这可以通过dplyr包中的slice函数来完成。 考虑下面的数据帧,该数据帧具有一组变量,
-
数据库的已编译SQL语句高速缓存达到的最大大小
问题内容: 我的代码是 在Log Cat中显示警告 怎么解决呢? 问题答案: 在这里查看示例8-3和8-4 。 示例8-3 使用更新方法 以下是示例8-3中的一些代码亮点: 例8-4显示了如何使用execSQL方法。 示例8-4 使用execSQL方法 该消息要求您使参数使用sql变量而不是sql文字。 解析每个sql查询,生成计划,并将其存储在sql语句缓存中。 从缓存中获取具有相同文本的查询。
-
python获取一组数据里最大值max函数用法实例
本文向大家介绍python获取一组数据里最大值max函数用法实例,包括了python获取一组数据里最大值max函数用法实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python获取一组数据里最大值max函数用法。分享给大家供大家参考。具体如下: 希望本文所述对大家的Python程序设计有所帮助。
-
数据结构,以找到任意数下的下一个最大值
我试图在我的Java项目中找到一个数据结构。我试图做的是从一组数字中获得低于任意数字的下一个最大值,或者如果不存在这样的数字,则得到通知。 例1)我的任意数字是7.0。{3.1, 6.0, 7.13131313, 8.0}我需要从这个集合中得到的数字是6.0。 例2)我的任意数字是1.0。{2.0, 3.5555, 999.0}集合中不存在下一个最高的数字,所以我需要知道它不存在。 我能想到的最好
-
按最大行分割非常大的文本文件
问题内容: 我想将包含字符串的巨大文件拆分为一组新的(较小)文件,并尝试使用nio2。 我不想将整个文件加载到内存中,因此我尝试了BufferedReader。 较小的文本文件应受文本行数的限制。 该解决方案有效,但是我想问一问,是否有人知道使用usion java 8(也许是带有stream()-api的lamdas)和nio2具有更好的性能的解决方案: 问题答案: 注意/ 及其子类的直接使用与
-
拆分大摇大摆的文件到单独的集
我正在使用. net core的swagger,我想知道是否有可能拆分2套或更多通过不同网址访问的swagger文档。这里不讨论版本控制。 举个例子,如果我有一个用于移动应用程序、web应用程序和另一个客户端的API。我想将它们分别分开,并且只为移动和web api添加授权,而不是客户端。我有这样一个想法,将各自的api划分为多个区域,但我仍然不知道如何将其划分为多个区域。 我知道我能得到同样结果
-
Azure CosmosDB-分区密钥最大大小达到10 GB
-
无法分配具有形状和数据类型的数组
问题内容: 我在Ubuntu 18上在numpy中分配大型数组时遇到了一个问题,而在MacOS上却没有遇到同样的问题。 我想一个numpy的阵列形状分配内存 使用 当我在Ubuntu OS上遇到错误时 我在MacOS上没有得到它: 我读过某处不应该真正分配数组所需的全部内存,而只分配了非零元素。即使Ubuntu计算机具有64gb的内存,而我的MacBook Pro却只有16gb。 版本: PS:在