《大数据分析》专题
-
 快手数据分析24校招一面
快手数据分析24校招一面👥 面试题目 ➡️投递渠道:快手官网;整个面试时长70分钟,是我面过最长的 面完感觉元气散了一半 呼~ 一共四个大板块,下面附上详细面经: part1:基本情况了解: 深挖简历情况,例如第一段实习的收获,第二段实习中遇到的问题,我对第二段工作的了解情况 part2:编程技能考察 1.求次日留存率 2.统计朋友点赞,但是自己没点赞的内容 part3:数理统计考察 一道贝叶斯应用题 part4: 业
-
 人保健康 郑州 数据分析岗
人保健康 郑州 数据分析岗3V1 11.16 对人保健康有什么了解 对岗位的认识 你对岗位有什么优势 劣势是什么 你本科是几本院校 你专业对于岗位有什么优势,劣势
-
 百度提前批数据分析二面
百度提前批数据分析二面1.深挖简历 2.GMV拆解 异动分析 3.数据分析工具竞品对比 没手撕 体感一般 分享攒好运🍀
-
 淘天数据分析师二面面经
淘天数据分析师二面面经整体感觉面试难度和阿里系公司相当,属于中等难度,我个人给它打了三颗星。 面试过程: 自我介绍:首先,面试官让我做了一个简短的自我介绍,主要包括我的项目经验和实习经历。 模型约束:接着,面试官问我如何在模型中添加约束条件。 电商建模特点:然后,他询问了电商场景下有哪些特点可以用于建模。 双十一销量预判:面试官还问了我如何预判双十一大促期间的销量。 大促推荐策略:在大促期间,如何进行商品推荐也是一个重
-
 字节跳动-数据分析实习生
字节跳动-数据分析实习生二面(约35分钟) 1、自我介绍(在学校的课程上完了吗,可以实习多久等) 2、描述ABtest你所知道的全部内容 3、描述z统计量,t统计量,F统计量 4、z分布,t分布的区别是什么 5、两道SQL题目: (a)找到每个班的学生的数量 ;(b)每个班各科目平均成绩>80分的学生人数和比例 6、怎么分析抖音某个商品购买量下降 7、反问环节
-
 蔚来数据分析实习生面经
蔚来数据分析实习生面经接到电话第二天早上就要面试,用的飞书视频面。 因为时间原因没过,很荒谬啊,谁来告诉我大学生如何做到开学后还要五天全天线下实习的,,,好了,吐槽到此为止,面试官人很好,很温柔反正 1、自我介绍 2、介绍一个最有价值的项目经历 3、深度挖掘这个项目的一些提问 4、提问一个其他相关的项目经历 5、对公司产品的了解(我面试的是某项产品下面的数据分析岗位) 6、从数据的角度如何评价产品好坏,如何挖掘数据背后
-
 2023春招-面试-京东-数据分析
2023春招-面试-京东-数据分析公司:京东(京东物流) 岗位:数据分析 形式:视频面试 视频面试平台:JoyMeeting、手机 时长:30分钟 流程: 1、自我介绍 2、大学的专业是自己选的吗? 3、你在职业规划上最关注的三个方面。 4、假如我们现在的业务部门可能很多表格都需要手工收集,手工用Excel进行分析,花费的时间比较多,你会从哪些方面着手来实现数据体系的改善? 5、通过之前实习的了解后,你觉得在物流行业的数据应用方面
-
JavaScript支持的最大递归调用次数分析
本文向大家介绍JavaScript支持的最大递归调用次数分析,包括了JavaScript支持的最大递归调用次数分析的使用技巧和注意事项,需要的朋友参考一下 你对JavaScript引擎能进行多少次递归调用好奇吗? 多少次递归调用 下面的函数可以让你找到答案: (灵感来自Ben Alman的 gist) 三个结果: 这些数字代表什么?Aleph先生指出,在V8中,递归调用的数量取决于两个量:堆栈的大
-
休眠保存或更新大数据
问题内容: 我正在尝试使用Hibernate插入或更新大数据。我有一个包含350k对象的列表,当我使用Hibernate时,要花费数小时才能插入所有数据。 我正在使用以下代码进行此操作。我的开发环境是JDK1.4和Oracle数据库。 我正在使用批处理更新,还设置了属性50,但这并没有帮助。 我的对象与另一个对象具有一对一的关系,因此在这种情况下使用StatelessSession可能会出现问题。
-
标准化大熊猫中的数据
问题内容: 假设我有一个熊猫数据框: 我想计算数据框的列均值。 这很简单: 然后按列范围max(col)-min(col)。这又很容易: 现在,对于每个元素,我要减去其列的均值并除以其列的范围。我不确定该怎么做 任何帮助/指针将不胜感激。 问题答案:
-
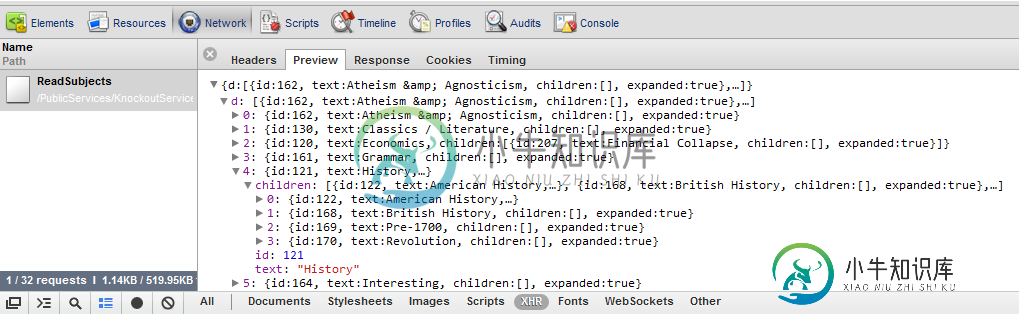 在Chrome中检查大型JSON数据
在Chrome中检查大型JSON数据问题内容: 我的网站上有一个页面,该页面使用jquery AJAX从PHP后端请求JSON数据。我想查看返回给浏览器的JSON,并尝试使用Chrome浏览器的开发人员工具(位于下)进行操作。 问题: 尽管我可以通过在其中选择XHR项来查看JSON数据,但是响应似乎在途中中断了。根据Chrome的说法,此JSON响应大小为300-400KB。我想知道网页是否接收到了完整的JSON响应而没有截断,如果
-
 滴普一面 大数据测试 10.13
滴普一面 大数据测试 10.13群面(轮流技术面,还好) (4候选者+1hr+1负责人+2技术面试官) 1.自我介绍 2.问测试项目(好久没看了,记不清。。。) 3.输入网址到出现页面的过程? 4.DNS 6.什么是合理的测试用例? 7.为什么想要做测试?未来的职业规划? #秋招##测试#
-
使用pandas的“大数据”工作流
几个月来,我在学习熊猫的过程中,一直在努力想出这个问题的答案。我在日常工作中使用SAS,它的核心支持很棒。然而,SAS作为一个软件是可怕的,还有许多其他原因。 有一天我希望用python和pandas取代我对SAS的使用,但我目前缺少一个用于大型数据集的非核心工作流。我说的不是需要分布式网络的“大数据”,而是大到内存放不下但小到硬盘驱动器放不下的文件。 我的第一个想法是使用在磁盘上保存大型数据集,
-
大数据技术栈思维导图
-
在SQL Server中查找最大数据
问题内容: 我有这种表,找到最大的标记 学生 外面应该是这样的 但我得到这种输出 我用SQL写这个 我该如何纠正sql? 问题答案: 在SQL Server中,您可以使用 尽管您也可以使用逻辑上等效的标准SQL