《大数据分析》专题
-
理解Kafka分区元数据
我正在NodeJs应用程序中使用kafka-node通过loadMetadataForTopics选项创建主题。我希望我的应用程序动态地了解可用分区的数量,以便它能够在这些分区上正确地分发消息。 在单个节点Kafka实例中,方法创建主题并返回元数据,如下所示: 但是,在三节点集群中,该方法会创建更多的条目: 在本例中,它创建了4个分区吗?在我看来是这样的--因为这只是最后一个案例场景(真的显式设置
-
 【工行深分】科技-数据
【工行深分】科技-数据#非技术2023笔面经# 1.介绍实习、校园实践、绩点、奖学金、干部等经历 2.(根据提前十分钟发的材料进行一个观点简述)pre 3.(简历深挖)页面搭建问题 4.(简历深挖)资源整合问题 5.(简历深挖)资源整合这件事情对你的结果影响最大的点是什么?就或者对你结果产生了怎么样的一个影响? 6.(简历深挖)你当时在设计页面的时候,你的需求方是谁? 7.你有没有用过我们工行的APP或者其他银行的?根
-
第三部分:数据结构
你正在以你的方式构建个人流程,它让你以有限的阻碍快速起步。拥有良好的起步流程,以及培养一种尽管去做的能力,就是创造力的基础。创造力是一种流动性和放松的心态。如果你的起步充满阻碍和沮丧,那么很难进入这个流程。学习“点击”你的大脑,使其进入具有创造力的、松散的 Hack 模式,可以帮助你使用创造力解决问题,并提高生产力。 如果你做的是垃圾,那就没有意义了。首先,是的,显然,你所做的绝大多数都是垃圾,但
-
语义分割和数据集
在前几节讨论的目标检测问题中,我们一直使用方形边界框来标注和预测图像中的目标。本节将探讨语义分割(semantic segmentation)问题,它关注如何将图像分割成属于不同语义类别的区域。值得一提的是,这些语义区域的标注和预测都是像素级的。图9.10展示了语义分割中图像有关狗、猫和背景的标签。可以看到,与目标检测相比,语义分割标注的像素级的边框显然更加精细。 图像分割和实例分割 计算机视觉领
-
数据表 - 分页和排序
分页 使用 limit 和 offset 来控制分页数据: limit 指定该请求返回的结果个数 offset 偏移量,指定该请求返回的结果的起始位置 默认 limit 为 20, offset 为 0,我们也可以手动指定 limit 和 offset 来控制。例如,每页展示 100 条数据,需要获取第五页的数据,将 limit 设置为 100、offset 设置为 400 即可。limit 最大
-
数据表 - 分页和排序
{% tabs first=”SDK 1.1.0 及以上版本”, second=”SDK 1.1.0 以下版本” %} {% content “first” %} SDK 1.1.0 及以上版本 分页 使用 limit 和 offset 来控制分页数据: limit 指定该请求返回的结果个数 offset 偏移量,指定该请求返回的结果的起始位置 默认 limit 为 20, offset 为 0,
-
从多个不同大小的数据集加载PyTorch数据
我有多个数据集,每个数据集中有不同数量的图像(和不同的图像维度)。在训练循环中,我想从所有数据集中随机加载一批图像,但每个批次只包含单个数据集中的图像。例如,我有数据集A、B、C、D,每个数据集都有图像01。jpg,02。jpg,…n.jpg(其中n取决于数据集),假设批量大小为3。例如,在第一个加载的批次中,我可能会在下一个批次[D/01.jpg,D/05.jpg,D/12.jpg]中获得图像[
-
您如何找出MySQL数据库中数据的总大小?
问题内容: 如何计算MySQL中数据库的总大小? PS总大小,以正在使用的磁盘空间为单位。 问题答案: 此链接有一个非常激烈的查询…将为您提供超出您所需的......:
-
用于大型数据文件和流媒体的数据库
我有一个“数据库选择”和体系结构问题。 用例: 客户端将上载大型。json文件(或其他格式,如.tsv,不相关),其中每一行都是关于其客户的数据(例如姓名、地址等) 我的要求: > 数据库应该有某种复制,因为我们不想丢失数据。 不需要索引,因为我们只是流数据。 对于这个问题,您对数据库有什么建议?我们尝试将其上传到Amazon S3并让他们处理缩放等问题,但存在读取/流式传输缓慢的问题。 谢了伊凡
-
我想根据数组大小对MongoDB数据进行排序
我有学生(弦)和老师(弦列表)。我想根据讲师人数按降序提取记录。讲师如下示例:[a、b、c]-3、[e、f]-2、[g、h、i、j]-4。 我要按4,3,2的顺序。 这取决于现场讲师阵列的大小。如何使用mongoTemplate或自定义mongodb查询或聚合进行查询??
-
 【小红书4面已OC】大数据开发-数据平台
【小红书4面已OC】大数据开发-数据平台已OC,评论区有意向群大家可以加入交流 一面: 挺走流程的,项目+八股+性格 二面: 项目+做题+性格,题目是一个实时指标,一个离线指标,居然要求在web上写flink,然我选择用SQL写离线,题目是统计一个直播间的最大在线人数,感觉挺好的,但是说方向偏业务,问了我的意向,我没表达出兴趣。 三面: 1.自我介绍 2.项目介绍 3.Hudi项目难点 1).FlinkJob怎么配置采集表的个数:个数太
-
MySQL数据库表中的最大记录数
问题内容: MySQL数据库表的记录上限是多少?我想知道自动增量字段。如果我添加数百万条记录会怎样?如何处理这种情况?谢谢! 问题答案: mysql int类型可以做很多行:http : //dev.mysql.com/doc/refman/5.0/en/numeric- types.html 无符号的最大值是 无符号的最大值是
-
如何从PHP大数组中获取数据
我有一个包含玩家数据的数组。这个数组根据玩家的数量而变化。数组看起来像这样: 我只想从每个玩家的数组中获取玩家名。我该怎么做?输出应该是如下所示的字符串:我在Internet或YouTube上没有找到任何内容。答案当然简单明了,但我还没有找到。 Im使用PHP 8.0.13。
-
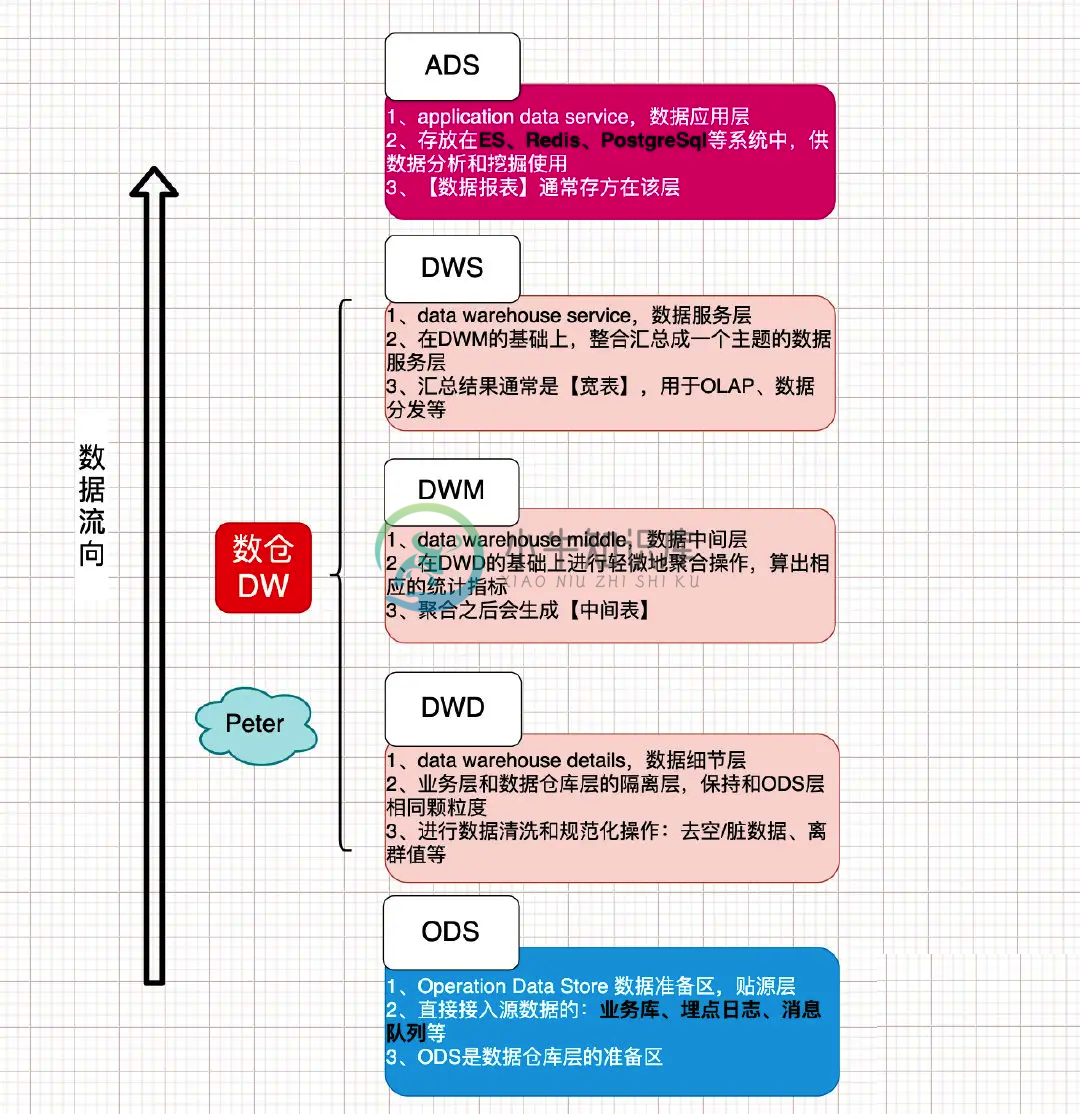 大数据数仓高级面试题【8道】
大数据数仓高级面试题【8道】主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
Pandas-根据日期将数据框拆分为多个数据框?
问题内容: 我有一个带有多个列以及一个日期列的数据框。日期格式为15年12月31日,我将其设置为日期时间对象。 我将datetime列设置为索引,并希望对数据框的每个月执行回归计算。 我相信实现此目的的方法是将数据框基于月份拆分为多个数据框,存储到数据框列表中,然后对列表中的每个数据框执行回归。 我使用过groupby可以按月成功拆分数据框,但是不确定如何正确地将groupby对象中的每个组转换为