《大数据分析》专题
-
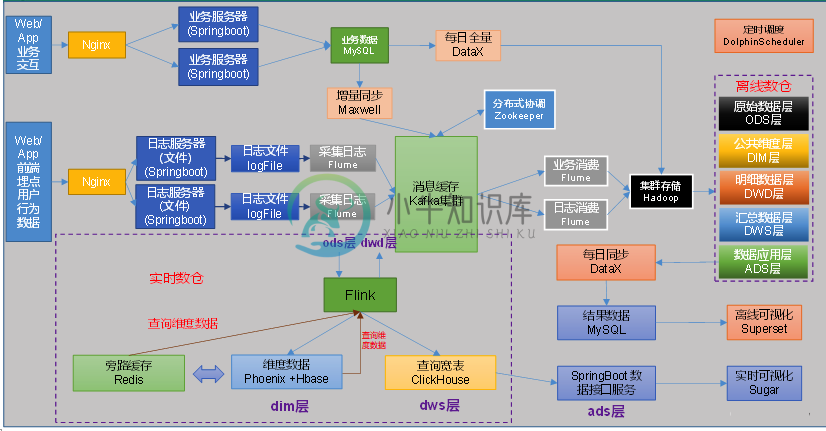 数据仓库建模过程分析
数据仓库建模过程分析主要内容:1.数据仓库概述,2.数据仓库建模概述,3.维度建模理论之事实表,4.维度建模理论之维度表,5.数据仓库设计1.数据仓库概述 1.1 数据仓库概念 数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。 1.2 数据仓库核心架构 2.数据仓库建模概述 2.1 数据仓库建模的意义 数据模型就是
-
 快手——数据分析,一面凉经
快手——数据分析,一面凉经自我介绍 五个sql题 两个概率论题 做完已经麻了。。 挖了一下简历,然后就凉了。。。
-
 PDD拼多多数据分析一面
PDD拼多多数据分析一面面试官很好,这是我秋招面的时间最长的一个面试,整整1个小时。 1.自我介绍 2.挖项目 3.五个sql手撕,不让切屏 4.python口述手撕 5.奥数题(如何估计一个房间有多少老鼠) 6.详细问经历,每个经历都问
-
 卡尔动力数据分析一面
卡尔动力数据分析一面一面30分钟,总体感觉面试官温和还挺好的 1.自我介绍 2.根据简历提问了一点问题 3.要是给你一个场景打标的任务,你会在路口场景怎么打标(回答红绿灯车道线什么的) 4.要是没有红绿灯车道线,也没有标志物,是无保护路口,怎么做 5.怎么捕捉cut in场景,你会用什么判断 6.混淆矩阵 7.sql熟练程度,口头说了一下 8.python写快排 9.linux知道多少,了解ros系统吗 10.反问
-
 拼多多数据分析师凉经
拼多多数据分析师凉经一面: 1.涉及过数据挖掘的项目讲一讲,这里分错的样本有没有研究一下为什么会分错。 2.讲一讲SVM、XGBOOST原理。 3.知不知道决策树剪枝,具体怎么做的,在哪一步做 4.知不知道LightGBM 5.深度学习有没有了解? 6.过拟合的L1范数和L2范数有什么区别? 7.mapreduce原理和过程 8.给key,value两列,找出每个key里第二大的值并输出。用python自己定义一个数
-
 蔚来——数据分析,二面经验
蔚来——数据分析,二面经验问题: 自我介绍 优缺点 别人怎么评价你 转向数据分析的契机 实习和竞赛哪个更印象深刻 实习中遇到的困难和解决的方法 对岗位的期待 反问 会不会影响学业 到岗时间 非常快,加起来20分钟
-
 面经|小红书数据分析师
面经|小红书数据分析师1.自我介绍 2.收入分析项目中的指标体系搭建思路 管理视角+分析视角指标拆解,维度细分 3.专员的主要工作内容是什么 外部能看到+内部业务场景细分 4.对于专员工作质量的评估 主观+客观(数量+质量) 5.对于专员的考核指标是什么呢 回答:从单价中拆出一定的比例进行激励+审核扣钱 改善:出勤、工作质量激励、绩效(以城市整体为参考线)、主观评价 6.专员的收入构成 回答:按工作量,干多少活算多少钱
-
 哈啰数据分析日常面经
哈啰数据分析日常面经#数据分析# 下午刚面完字节的产品,晚上哈啰突然通知电话面,数据分析的日常岗(感觉暑期已经招完啦) 本来通知6点面,结果面试官到7.30才打的电话,真的干等了一个半小时 先是深挖了下实习经历和项目经历,没这么给压力也没怎么提问,就是让我介绍一下,然后就是给了几个问题 1.如何估算一个城市的哈啰单车订单数量,考虑哪些指标,用什么模型 2.如何验证你的预测是否准确 3.现在有用户的全部数据,需要判断这
-
区分大小写的SQL区分大小写
问题内容: 我正在尝试提出一个要求区分大小写的结果的请求。 例如在我的数据库中 该请求是 但我有3行作为结果,我只想要abcdef 我试图找到一个解决方案 但是我有这个错误: 未知归类:’Latin1_General_CS_AS’{“成功”:false,“错误”:“#1273-未知归类:’Latin1_General_CS_AS’”} 谢谢 问题答案: 感谢您的帮助,我找到了不是latin1 ut
-
为什么分报告中不同维度的数据相加会大于网站概况的数据
使用指南 - 疑难问题 - 数据矛盾问题 - 为什么分报告中不同维度的数据相加会大于网站概况的数据 每个报告的分析维度不同,因此去重逻辑也不同。网站概况,以及趋势报告中的数据是以整个站点为维度去重的,是了解站点整体流量和访问量的地方。 例如:访客 X 通过百度搜索进入网站后又通过直接访问进入网站,此时,“搜索引擎”报告和“直接访问”报告会各记录一个独立访客数据,但是网站概况中只会记录一个独立访客数
-
内存分布式缓存中的数据分区与数据持久化
null 假设我有100张唱片。缓存只能保存40条记录(最常用)和100条记录在磁盘文件(不在任何其他数据库中)。 所以,如果从这100条记录中请求任何东西,我就不必去实际的数据库(例如Sybase db)? 如果在100条记录中找到了密钥,但它不存在于内存缓存中(40条记录),则获取该密钥,放入内存缓存中,并使用驱逐策略将其他密钥交换到磁盘文件中(但在磁盘上,我总是有100条记录) 如果缓存和磁
-
 2022暑期实习-面试-顺丰科技-大数据挖掘与分析工程师
2022暑期实习-面试-顺丰科技-大数据挖掘与分析工程师公司:顺丰速运集团(顺丰科技) 岗位:大数据挖掘与分析工程师 形式:视频面试 视频面试平台:赛码 初试 面试官:所在组的大数据挖掘与分析高级工程师 时长:15分钟 流程: 0、面试官自我介绍 1、自我介绍 2、看到你简历上写了很多个项目,你觉得哪个项目对你能力提升比较大?可以详细描述一下吗?包括但不限于项目背景、分析过程、最终目标、结果展示等。 3、讲一下机器学习模型和数据挖掘方法在这些项目中的具
-
关键数据结构和相关函数分析
关键数据结构和相关函数分析 对于第一个问题的出现,在于实验二中有关内存的数据结构和相关操作都是直接针对实际存在的资源--物理内存空间的管理,没有从一般应用程序对内存的“需求”考虑,即需要有相关的数据结构和操作来体现一般应用程序对虚拟内存的“需求”。一般应用程序的对虚拟内存的“需求”与物理内存空间的“供给”没有直接的对应关系,ucore是通过page fault异常处理来间接完成这二者之间的衔接。
-
排序后的数据帧分区数?
spark如何在使用< code>orderBy后确定分区的数量?我一直以为生成的数据帧有< code > spark . SQL . shuffle . partitions ,但这似乎不是真的: 在这两种情况下,spark都< code >-Exchange range partitioning(I/n ASC NULLS FIRST,200),那么第二种情况下的分区数怎么会是2呢?
-
按子数组拆分子数组和大小Ruby
我有一个子阵列: 我想将每个子数组的元素放入另一个数组中,但子数组大小的总和必须小于或等于6。所以我想得到这样的东西 我现在的代码是 我被困在这里,因为我的代码只有两个前元素。原始数组有大约1000个子数组,我的代码没有以那种形式分割它。