《大数据分析》专题
-
Python词干分析(使用数据帧)
我创建了一个数据框,其中包含要被词干化的句子。我想用雪球机来获得更高的分类算法精度。我该如何实现这一点?
-
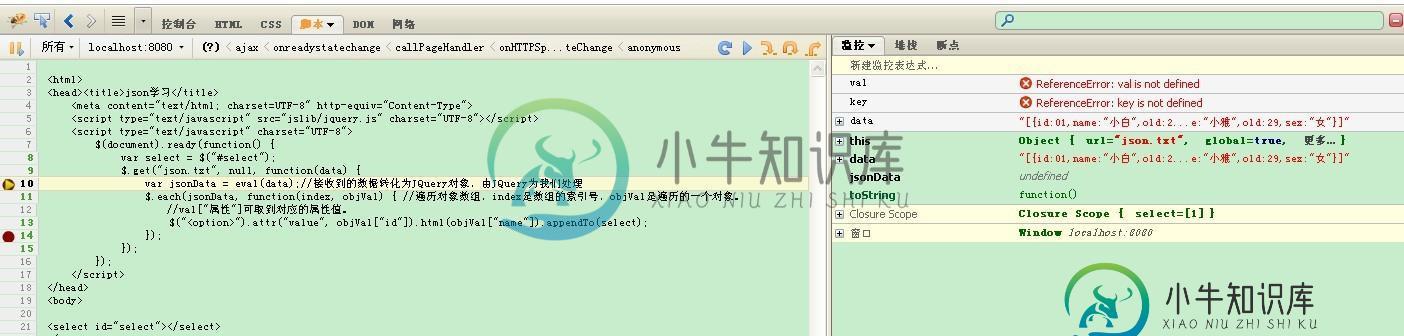 jQuery解析json数据实例分析
jQuery解析json数据实例分析本文向大家介绍jQuery解析json数据实例分析,包括了jQuery解析json数据实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了jQuery解析json数据的方法。分享给大家供大家参考,具体如下: 先来看看我们的Json数据格式: 为了消除乱码问题,我们设置一个过滤器(代码片段) 服务端我用Servlet生成json数据(代码片段)。 页面端JQuery代码: 之前为了省事,
-
python实现数据分析与建模
本文向大家介绍python实现数据分析与建模,包括了python实现数据分析与建模的使用技巧和注意事项,需要的朋友参考一下 前言 首先我们做数据分析,想要得出最科学,最真实的结论,必须要有好的数据。而实际上我们一般面对的的都是复杂,多变的数据,所以必须要有强大的数据处理能力,接下来,我从我们面临的最真实的情况,一步一步教会大家怎么做。 1.数据的读取 2. 数据的处理 2.1.异常值(空值)处理
-
使用Python Pandas进行数据分析
本文向大家介绍使用Python Pandas进行数据分析,包括了使用Python Pandas进行数据分析的使用技巧和注意事项,需要的朋友参考一下 在本教程中,我们将看到使用Python pandas库进行的数据分析。图书馆的熊猫都是用C语言编写的。因此,我们在速度上没有任何问题。它以数据分析而闻名。我们在熊猫中有两种类型的数据存储结构。它们是Series和DataFrame。让我们一一看。 1.
-
你是怎么做数据分析的?
本文向大家介绍你是怎么做数据分析的?相关面试题,主要包含被问及你是怎么做数据分析的?时的应答技巧和注意事项,需要的朋友参考一下 考察的是数据分析的能力。主要从以下4个维度回答,结合具体的数据分析来进行阐述: 明确数据分析的目的; 确定数据分析的方法以及获取所需要的数据; 对数据进行预处理,并进行分析; 输出数据分析报告,提出相应建议。
-
多部分WADO-RS dicom数据解析
我正在使用带有Content-Type: Application/dicom的WADO-RS。成功执行请求后,我得到了一个字节流,其中包含一些头信息和Multipart格式的DICOM数据。如何使用C代码从中解析实际的DICOM数据?
-
获取和分析USSD响应数据
我正在尝试解析运营商网络的USSD响应。找到一个链接https://github.com/alaasalman/ussdinterceptor,但它不支持4.2.2及以上版本。是否有任何api或方法可以达到此目的?
-
 YouTube分析与YouTube数据API差异
YouTube分析与YouTube数据API差异我一直在使用YouTube Analytics API(我正在使用Java库)来检索YouTube频道的分析数据-我一直在过滤对特定VideoID的API调用。 然而,当我在YouTube Analytics(网络界面)上查看时,同一日期范围的数据似乎有所不同。 有人对此有解释吗?
-
解析多部分/表单数据CakePHP3
我目前正在尝试解析我通过Chrome中的Postman插件发送的。然而,我得到的输出如下: 当我尝试调试时,会得到这个输出。当我尝试时,我得到一个空数组,所以我假设数据的格式不正确(只是一个字符串)。在我写我自己的算法之前,我想确定我没有用这个算法重新发明轮子。我做错什么了?或者,如果没有,是否存在一些CakePHP3函数来处理这个问题? 更新 我发现了代码中的错误,路由过程似乎以某种方式将pos
-
 蔚来数据分析实习面经
蔚来数据分析实习面经已拿到offer, 是自动驾驶云端部的数据平台的实习岗位; 整体蔚来的面试流程还是比较高效的,一共面了三轮,每轮间隔一天。 第一面 是直属mentor ,主要围绕简历深挖问了上段实习数据分析的case 和可视化的工作经历,并且问了对于BI的理解 。 做了一道SQL笔试, 中等难度,主要用了累计求和的窗口。 第二面 是leader面, 问了SQL优化以及数据平台的理解; 又做了SQL 。 两轮SQL
-
 【闪电快车数据分析实习】
【闪电快车数据分析实习】投递渠道:boss直聘 | 校招/实习流程:发笔试题- 一面(微信)- 二面 - 三面 刚面完就来写,攒攒人品吧,希望不凉 1. 简历深挖 介绍实习时做过的项目 2. 业务逻辑 五月的订单量相比于四月有所下降,怎么分析? 公司的用户大量流失,怎么分析? (这两个问题答得不好,不流畅也不太有逻辑,盲猜凉了....) 3. 费米问题 沈阳有多少辆出租车?(我从生产出租车的工厂答的)从人口方面怎么分析(
-
 小米-数据分析实习凉经
小米-数据分析实习凉经投完当天晚上8点收到电话,leader直接打来的,因为之前简历上涉及了ab实验,问了不了解时间片轮转(lz不了解)让我用一个晚上的时间调研上午的时候发给他。 发完迅速约了一面 面试官时间比较紧 只有10min 针对ab实验的分流提问 布置了一个笔试(lz没做对qwq)应该就凉了 #面经##实习面经##小米#
-
 猿辅导+数据分析师+一面
猿辅导+数据分析师+一面8月16日自主约面,8月20日一面,大概45分钟。面试官比较平易近人,面试总体感觉没有压力很大。 自我介绍 一个问题背景(两道sql,都和窗口函数相关,题目略有些绕) 简历挖掘了一些问题 开放问题(转化率异常怎么办,归因分析?) 反问环节(介绍了业务,询问了面试结果下周会出) 攒人品许愿早日拿到秋招offer! 欢迎xdm在评论区交流~ #猿辅导##数据分析##面经一面面经#
-
 经纬恒润 数据分析面经
经纬恒润 数据分析面经#校招# #面经# 攒攒人品许愿offer 8.19日投递 8.21约26号面试 时长40min 1. 自我介绍 2. 项目深挖(为啥最后改成降维了,xgb和rf为啥效果不好) 3. 说说决策树,随机森林,XGBoost 4. 说说随机森林的随机主要体现在什么方面?(回答主要是随机取样之类的,问还有吗,没了) 5. 已知学习率,n,随机森林取样取不到某个样的的极限是什么(不会) 6. 假设检验的流
-
 浪潮提前批 数据分析岗
浪潮提前批 数据分析岗浪潮 数据分析岗 3位面试官 1位主持自我介绍,1位负责sql,1位负责Python 上来先自我介绍 sql问题:用过什么 数据 库?sql的查询顺序? 简历问题:项目组遇到问题怎么解决? Python问题:iloc和loc区别?merge和append区别? 都很简单 很快的几分钟面完 #面经# #校招# #提前批# #秋招#