《数据库开发工程师》专题
-
 快手-数据研发工程师-一面
快手-数据研发工程师-一面8.26 50min左右 首先自我介绍,然后问了许多项目的问题 然后问了mr的原理和运行流程 hive如何确定reduce的数量 Spark和mr的区别 数仓分层 数仓维度建模问题 什么是维度表和事实表 数据库的三范式 做题 首先是一个sql题,很简单,但是我只刷了大量的java题不会sql的呜呜呜以后一定多刷 然后写了一个归并排序 面试官人超好,特别有耐心 上天保佑让我一面过吧! #快手面试
-
 快手 数据研发工程师 面经
快手 数据研发工程师 面经一面:80min 1、自我介绍 2、介绍部门情况 3、介绍下部门的数仓建设情况 4、简述实习里的三个实习做的项目,聊背后的逻辑 聊了好久好久 5、聊聊在字节认为部门最厉害的技术是什么 6、聊聊自己的爱好 7、觉得自己有什么有优点 8、团队协作和个人工作区别是什么,各自的优点和缺点 9、一道sql题,有两个数组,展开数据,角标相对应的取出数据 10、sql的job和stage划分,窗口函数是否会sh
-
 百度 数据研发工程师 面经
百度 数据研发工程师 面经一面: 无自我介绍环节,直接开问 1、聊实习项目,很细,聊了好久 2、yarn任务提交流程 3、spark的stage切分原理 4、spark任务提交流程 5、对比mr和spark,为什么都用spark 6、谈谈对hudi的理解 7、kafka的负载均衡原理 8、两道算法题,字符串相关的 9、反问 ps.好多过程不记得了 二面: 三个模块 开发 大数据 算法 不想回忆了,直接自闭,一点都不会 但是
-
 美团 数据研发工程师 面经
美团 数据研发工程师 面经到店业务 有点久远一直忘了写,就记得这么多 一面: 1、自我介绍 2、比赛中遇到的难点 3、实习中做的项目,聊项目细节 (大部分时间都在问这个) 我好像很多面经都这么简略的写,这次写细点儿哈,里面涉及到的一些知识点,具体项目就不聊了 数仓模型设计方法 数据质量如何判断 如何保障下游查出时间 对于重要程度不同的任务如何合理分配资源 dwd层建模方法,考虑哪些东西 spark任务调参逻辑和常用参数 c
-
 久邦数码--iOS开发工程师--一面
久邦数码--iOS开发工程师--一面#久邦数码面经#久邦数码 -- iOS开发工程师 -- 一面 1. 请自我介绍一下 2. 请说一些你知道的数据结构 3. 说一下数组和链表吧, 他们有什么区别 4. 请讲一下快速排序 5. 讲一下单例模式 6. 在什么情况下会使用单例模式 7. 说一下进程和线程的区别吧 8. 进程间之间有哪些通信方式 9. 讲一下死锁 10. 网络中有哪几层 11. 说一下http和https的区别 12. 说一
-
数据库发现
定义 SHOW DB_DISCOVERY RULES [FROM schemaName] 说明 列 说明 name 规则名称 dataSourceNames 数据源名称列表 discoverType 数据库发现服务类型 discoverProps 数据库发现服务参数 示例 mysql> show db_discovery rules from database_dis
-
数据库发现
定义 CREATE DB_DISCOVERY RULE databaseDiscoveryRuleDefinition [, databaseDiscoveryRuleDefinition] ... ALTER DB_DISCOVERY RULE databaseDiscoveryRuleDefinition [, databaseDiscoveryRuleDefinition] ... DR
-
 美团数据仓库工程师一面 40min
美团数据仓库工程师一面 40min👥 面试题目 1.自我介绍,能不能从几个方面说一下项目 2.有什么收获 3.简历里面哪个技术学的最好 4.spark的client模式和集群模式 5.yarn 6.能够重分区的算子 7.为什么用rdd,不用df和ds,他们的区别 8.为什么spark比mapreduce更快(磁盘io和进程线程模型) 9.spark也会OOM和溢写磁盘啊,mapreduce也有缓冲区啊,都是内存计算,为什么更快(
-
MongoDB同步开发和生产数据库
我们有一个包含对象集合的开发服务器。这些对象的实际积累是一个持续的过程,在这个本地开发服务器上运行标签、验证等的整个过程。一旦这些对象准备好生产,它们就会被添加到生产数据库中,从那时起,生产数据库将在其计算中使用它们。 我正在寻找一种简单地将增量(新对象)添加到生产数据库中的方法,同时将所有其他集合和旧对象保留在同一个集合中。到目前为止,我们一直使用MySql,所以这个过程只涉及运行数据库结构和数
-
 好未来 数据仓库开发实习
好未来 数据仓库开发实习一面 项目深挖 数仓分几层,每一层的作用 事实表如何设计 维度表如何设计 数据域如何划分 业务总线矩阵的概念 如何设计完整的指标 开发中和上线后数据质量如何保证 如何设计调度,依据是什么 hive数据倾斜解决办法 hivesql常见优化手段 什么是spark宽窄依赖,起到什么作用 sql题:用户连续登录游戏的最大天数,允许间隔一天 反问 做什么业务 教培业务中的线下面授分析 网络问题迟到了一会,面
-
1.6.5 数据开发案例-电梯数据开发
数据开发-电梯数据开发举例 离线数据开发 实时数据开发 数据开发-电梯数据开发举例 更新时间:2018-02-01 21:17:58 假设电梯设备,每天都会定时上传数据,每台电梯每隔1分钟会上传一次数据,包括电梯id,运行状态(上行,下行,停止),门状态(打开,关闭),数据会进入离线表和实时的METAQ。 离线数据开发 业务需求:电梯利用率情况(某个单位的电梯在某个小时段内利用率,可以减少这个单位
-
 摩尔线程 C++开发工程师
摩尔线程 C++开发工程师10月9号一面技术面 1.5h 问了项目+一些八股 手撕两道: 1.生产者消费者 2.K个一组反转链表 要自己构造链表和打印链表 10月10号直接oc....这效率我都惊了 #C++工程师#
-
 携程 Java开发工程师 一面
携程 Java开发工程师 一面岗位:Java开发工程师 时间:9.20 题目 项目经历 介绍下比较熟的项目和其中的点 索引是怎么实现的 如果数据量比较大会不会引起性能变化 实习经历 RPC介绍一下 如果调用发现很慢怎么排查 slf4j优点 八股 MySQL与Redis区别,后者能不能替代前者 Redis为什么要分布式 进程和线程 怎么多线程,不用锁呢 算法 不含重复字符的最长子串的长度 总结 携程面试总体来说还是比较全面的,从
-
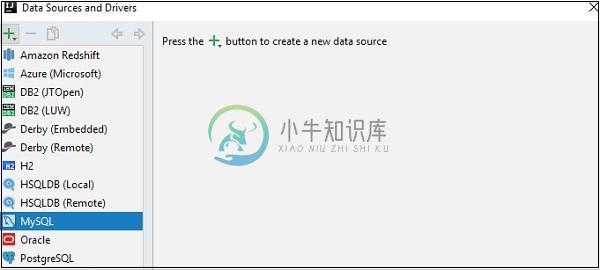 Pycharm数据库工具
Pycharm数据库工具主要内容:添加数据源PyCharm支持各种类型数据库的接口支持。 当用户授予对创建的数据库的访问权限,它就会使用提供代码完成的SQL编写工具提供数据库的模式图。 在本章中,我们将重点介绍MySQL数据库连接,其中涉及以下步骤。 添加数据源 请注意PyCharm支持各种数据库连接,这一点很重要。 第1步 打开数据库工具窗口:View -> Tool Windows -> Database,并打开名为数据源和对话框的对话
-
数据库工具类
数据库工具类提供了一些方法用于帮助你管理你的数据库。 初始化工具类 使用数据库工具类 获取数据库名称列表 判断一个数据库是否存在 优化表 修复表 优化数据库 将查询结果导出到 CSV 文档 将查询结果导出到 XML 文档 备份你的数据库 数据备份说明 使用示例 设置备份参数 备份参数说明 类参考 初始化工具类 重要 由于工具类依赖于数据库驱动器,为了初始化工具类,你的数据库驱动器必须已经运行。 加