《数分》专题
-
PDF中的“分离”数字签名
我想实现PDF的“并行”签名过程,这样用户就可以不是“一个接一个”地进行数字签名,而是同时进行数字签名。为了实现这一点,我决定为所有用户创建初始文档的单独副本,并在它们上获得签名。最终,所有签名都应该连接到单个PDF中。 让我们假设,PDF在签名过程中没有变化,除了签名字段创建(所有acroForms、signaturecontainer、可视签名等都是在之前创建的,并且对所有这些都是相似的)。
-
属性的Spring数据Rest分页
我有两个使用分页和排序存储库定义的资源: 画廊/{id} 一般来说,这两种资源的分页都是根据使用的存储库类型提供的。 画廊本身包含一个图像列表 我现在可以通过 画廊/1/图片 是否也可以为这些子列表启用分页?或者,处理这些大列表的REST样式是什么。 事先谢谢你,圭多
-
APICall响应无法分析数据
我需要从这个URL解析数据https://newsapi.org/v1/articles?apiKey=6946d0c07a1c4555a4186bfcade76398 我尝试过将BASE_URL和Query更改为几个不同的选项,但没有任何帮助。也许是我的物体有问题,但我找不到错误。 *****更新*****:我像评论中所说的那样更改了我的对象,但仍然使用失败函数。 主要活动。JAVA 内特沃库提
-
jpa分页隐藏计数查询
我们正在使用Spring Data JPA Repository。对于分页,我们将Pageable对象传递给JPA Repository findBy Methods。 因为在我们的UI中,我们不显示记录的总计数,所以我们不希望触发计数查询。有没有办法抑制分页期间触发的计数查询?
-
为函数指针分配内存
我有一个func添加两个NO并返回(a+B)。然后我创建了一个指向func的func指针。希望为该函数指针的数组分配内存并访问它们。代码如下。 我的问题是使用malloc的下面一行: 编译时,sizeof(add_2nos*)和sizeof(add_2nos)没有任何区别。如果有什么区别??另外,如果类型转换是必要的,而我正在分配相同类型的内存…?
-
火花数据帧范围分区
[新加入Spark]语言-Scala 根据文档,RangePartitioner对元素进行排序并将其划分为块,然后将块分发到不同的机器。下面的例子说明了它是如何工作的。 假设我们有一个数据框,有两列,一列(比如“a”)的连续值从1到1000。还有另一个数据帧具有相同的模式,但对应的列只有4个值30、250、500、900。(可以是任意值,从1到1000中随机选择) 如果我使用RangePartit
-
Java流分组和计数占用
我有一个代表市场交易的对象列表。每一次交易都有一个开盘和收盘的时间,都有一个利润。我想按月份对它们进行分组,然后统计每个月中利润>0和<0的交易数量=创建一个具有以下结构的映射{“mm”={“Win”=numberOfWinTrades,“Loss”=numberOfLossTrades},“mm”...} 我想出了以下代码,但我无法将条件实现到其中:
-
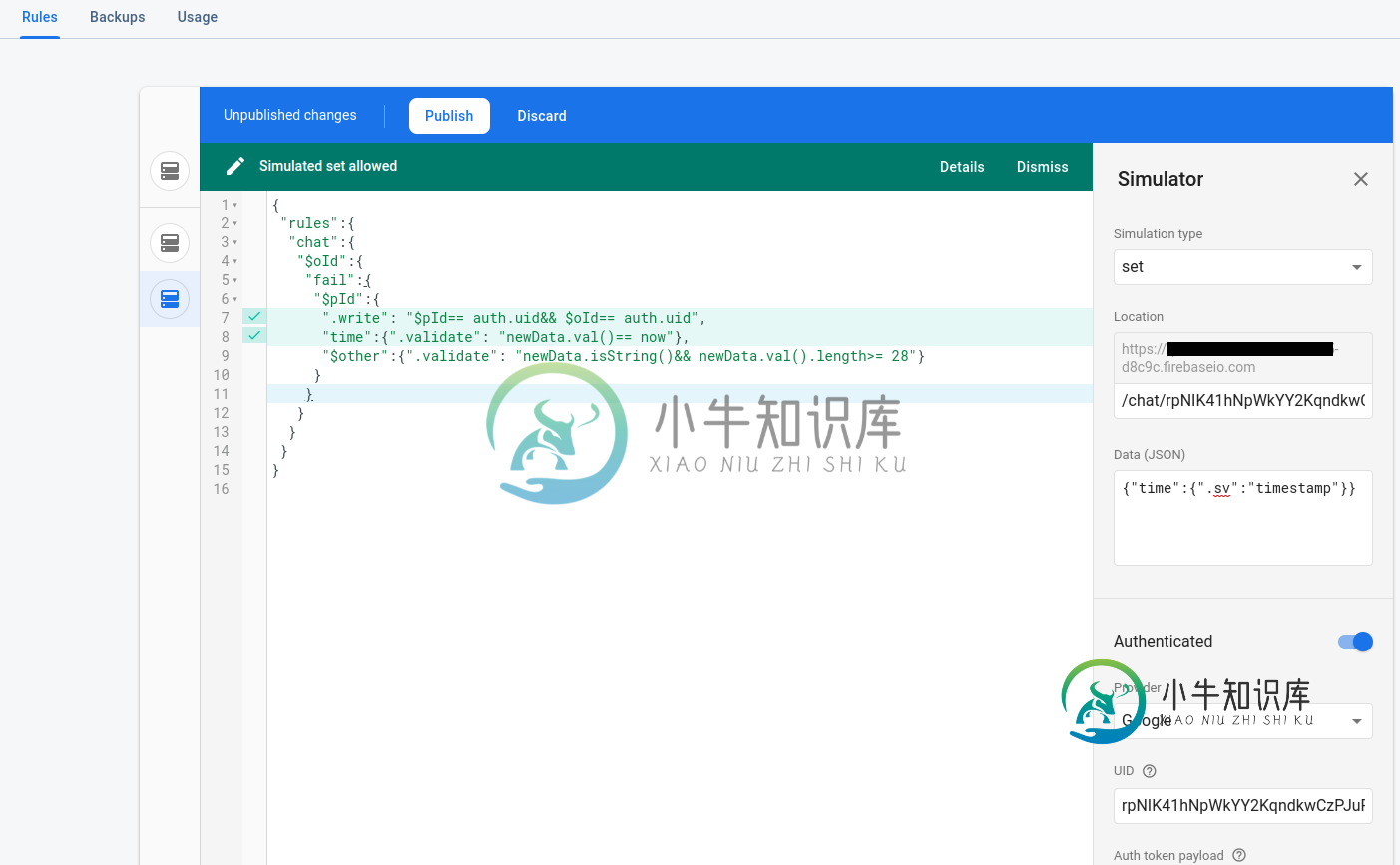 Firebase实时数据分片规则
Firebase实时数据分片规则更新2019-11-03:添加了错误的实时最小复制。在Chrome中加载链接后,点击ctrl shift i并选择控制台以查看输出。我已经尽力确保这正是我最初的项目代码所做的;我们看看情况是否如此,嗯?碎片的规则文件与下面的原始帖子相同。该源代码可在GitHub上获得。 原文: 这些规则在模拟器中工作,但在我真正的网络应用程序中不工作。模拟器路径和有效负载与下面数据库日志输出中显示的相同。 (将两
-
 数据分析2021秋招面经
数据分析2021秋招面经蒙牛-数字化管培生(2021秋招) 蒙牛一面(群面): 1.简单自我介绍 2.情景业务题(大致内容是推销即将上市的新品类牛奶,突出区别,你会采用什么方式推广,如何看收益回报) 3.面试官针对讨论过程问问题 4.无反问 蒙牛二面(一个主管,一个hr): 1.为什么选择蒙牛数字化管培生岗位 2.谈谈实习的产出 3.常规HR面(家在哪里,个人优势,还拿到了哪些offer,期望薪资) 海信-数据分析(20
-
 沐瞳科技数分一面(moba)
沐瞳科技数分一面(moba)总评:整体面试难度对我来说还是比较大的,主要是因为对于游戏业务不熟悉,之前接触的更多是广告变现和电商业务。问了很多moba相关游戏细节,关于用户体验方向,确实了解比较少,还得多弥补下。 一、简历深耕: 1. 关联规则挖掘项目的背景,结果详细说下? 算法支持度和置信度阈值如何设定的? 2. 建立用户转化分类模型怎么选取特征的?承接策略有哪些? 3. 选
-
 4399数据分析一面凉经
4399数据分析一面凉经#4399游戏23届秋招面试# 看了好久牛客的面经,轮到我秋招了我就回馈一下给朋友们吧。楼主广东某985硕,一段互联网数据分析实习经历。8月28号投的4399数据分析岗位,申请完之后8.31就发了面试邀请,9.1下午的面试,还准备了好一会。没想到是个hr面。 大致内容(不一定记得全): 1.自我介绍 2.最有成就感的事 3.最遗憾的事 4.作为一名数据分析师的核心竞争力?(之类的问题,记
-
 迅雷0919数据分析笔试~
迅雷0919数据分析笔试~今天的笔试感觉质量很高啊!做的是激情澎湃。 虽然最后时间所剩无几,但是还是想简答聊聊对这场笔试的看法! 首先,今天的这场笔试不同以往的很多公司发的都是行测知识,都做吐了。这才考的有点像数分笔试题啊!!! 这场笔试考分为选择题和问答题两种题型,设计的知识点主要是跟机器学习相关的知识点(都是些基础概念,不难); sql,excel,python的简单考察;还有一些行测考的规律题,数理统计方面的题也有,
-
 haluo数据分析面试记录
haluo数据分析面试记录hr先介绍工作内容-excel报表人,数据库无权限 确认最快入职事件,最长实习时间 自我介绍环节 提问:偏感性or理性,用实例佐证 反问环节
-
 滴滴-数据分析师-面经
滴滴-数据分析师-面经先来一波职位描述: 岗位职责(具体工作内容) 1、支持滴滴国际化信贷业务,协助参与底层数据梳理,中间层数据建设等 2、协助团队进行报表设计与搭建 3、协助团队进行模型搭建与迭代优化 4、协助团队对业务问题进行分析,包括但不限于异常数据排查、异动原因分析,专项测试分析等 任职资格(学历、目标院校、语言、技能、性格等要求) 1、统招本科及以上学历在读,数学、统计、计算机、金融背景优先 2、良好的数据分
-
 数分实习面经:PayPal一面
数分实习面经:PayPal一面#paypal# #数据分析# #外企# #实习# #面经# 岗位方向:风控 面试提问: 一面:2022.6.22 PP是我的第一份数据分析实习,但由于当时没有写面经,到现在很多细节都记不清了。但我还记得那一年,中国队勇夺大力。。oh不,面试主要分为两个部分: 一面之技术面部分: 1、手撕代码:两道SQL题,不是很难,题目记不清了;一道Python题,也不是很难。两个题目都是考察一些基础的利用