

HiPlot是一款轻巧的交互式可视化工具,可帮助AI研究人员使用并行绘图和其他图形方式来表示信息,从而发现高维数据中的相关性和模式。
HiPlot 支持两种模式:
- 作为 Web 服务运行 (如果你的数据是 CSV 格式)
- 作为 jupyter notebook 运行(用于对 Python 数据进行可视化)
pip install hiplot
如果你有 jupyter notebook, 可以使用如下方法快速上手:
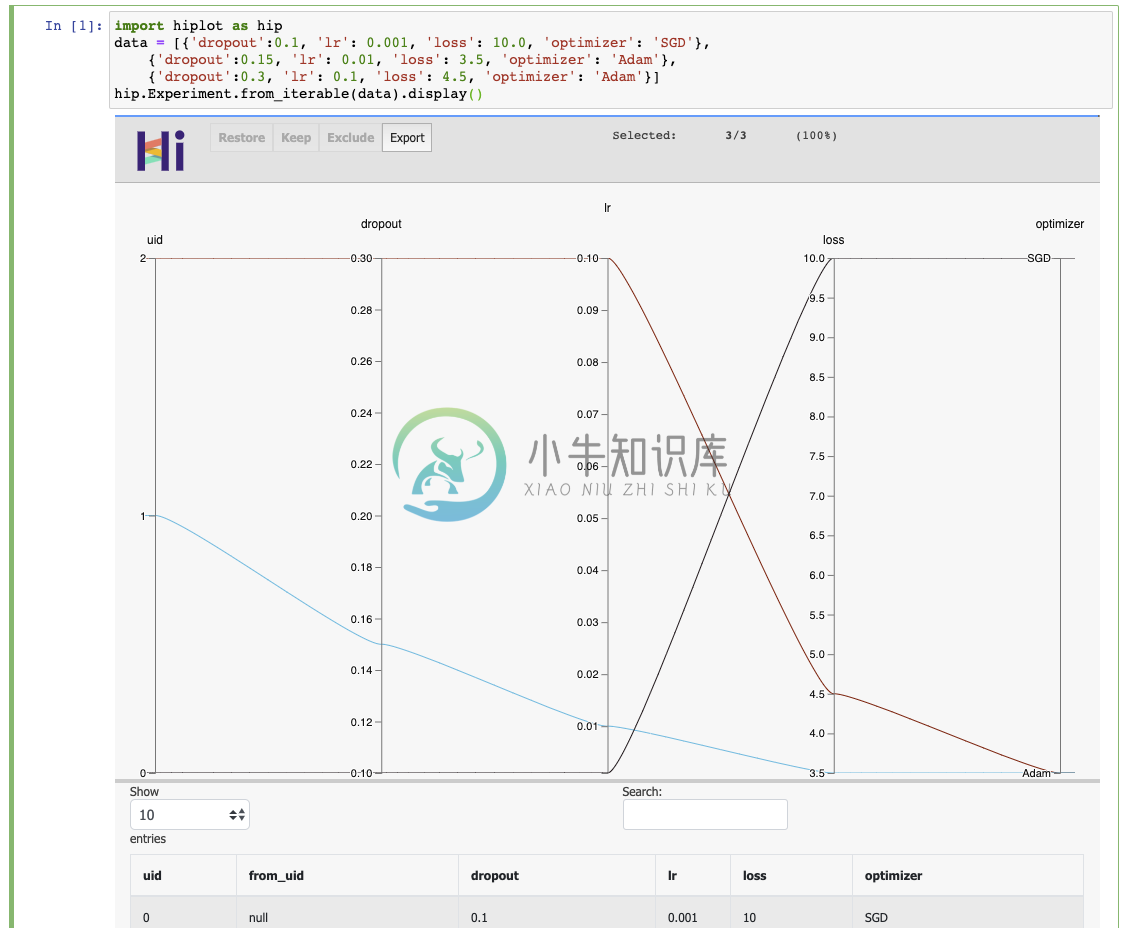
import hiplot as hip
data = [{'dropout':0.1, 'lr': 0.001, 'loss': 10.0, 'optimizer': 'SGD'},
{'dropout':0.15, 'lr': 0.01, 'loss': 3.5, 'optimizer': 'Adam'},
{'dropout':0.3, 'lr': 0.1, 'loss': 4.5, 'optimizer': 'Adam'}]
hip.Experiment.from_iterable(data).display()
实际运行效果
-
本文向大家介绍多维数据库,包括了多维数据库的使用技巧和注意事项,需要的朋友参考一下 多维数据库主要用于OLAP(在线分析处理)和数据仓库。它们可用于向用户显示多维数据。 多维数据库是从多个关系数据库创建的。关系数据库允许用户以查询形式访问数据,而多维数据库则允许用户提出与业务或市场趋势有关的分析性问题。 多维数据库使用MOLAP(多维在线分析处理)来访问其数据。它们允许用户通过相当快地生成和分析数
-
我们在OpenGL中大量使用缓冲来储存数据已经有很长时间了。操作缓冲其实还有更有意思的方式,而且使用纹理将大量数据传入着色器也有更有趣的方法。这一节中,我们将讨论一些更有意思的缓冲函数,以及我们该如何使用纹理对象来储存大量的数据(纹理的部分还没有完成)。 OpenGL中的缓冲只是一个管理特定内存块的对象,没有其它更多的功能了。在我们将它绑定到一个缓冲目标(Buffer Target)时,我们才赋予
-
问题内容: 我知道,常见的性能重构是用 我想问一下: 何时才真正使system.arraycopy变得有意义(考虑到这是本机方法调用)。复制小东西是否表示<32有什么好处? 是我的印象,还是不能简单地使用arraycopy复制(有效地)像这样的循环: } 问题答案: 可能是复制阵列最快的方法,但它不会进行深复制。 它还不能在第二个问题中做更复杂的示例。
-
问题内容: 我试图把我的头缠在三维阵列上。我知道它们是二维数组的数组,但是我正在阅读的书说的话使我感到困惑。 在我正在阅读的书的练习中,它要求我为全彩色图像制作三维阵列。它给出了一个小例子,说明了这一点: 如果我们决定选择三维数组,则可以通过以下方式声明数组: 但是,这样会更有效吗? 其中3是rgb值,0是红色,1是绿色,2是蓝色。对于后者,每个二维数组将存储行和列的颜色值,对吗?我只想确保我了解
-
问题内容: 我有一个像这样的JSON数组: 我想使用jQuery 能够返回每个数组值的值,但是我不确定如何访问它们。 到目前为止,我有以下jQuery代码: 我该如何使用jQuery? 问题答案: 的在JSON表示一个对象。对象的每个属性均以逗号分隔。像这样,可以通过使用句点运算符的键来访问属性值。的在JSON表示一个数组。数组值可以是任何对象,并且值以逗号分隔。要遍历数组,请使用带有索引的标准f
-
数据结构和算法是过去 50 年来最重要的发明之一,它们是软件工程师需要了解的基础工具。但是在我看来,这些话题的大部分书籍都过于理论,过于庞大,也是“自底向上”的