
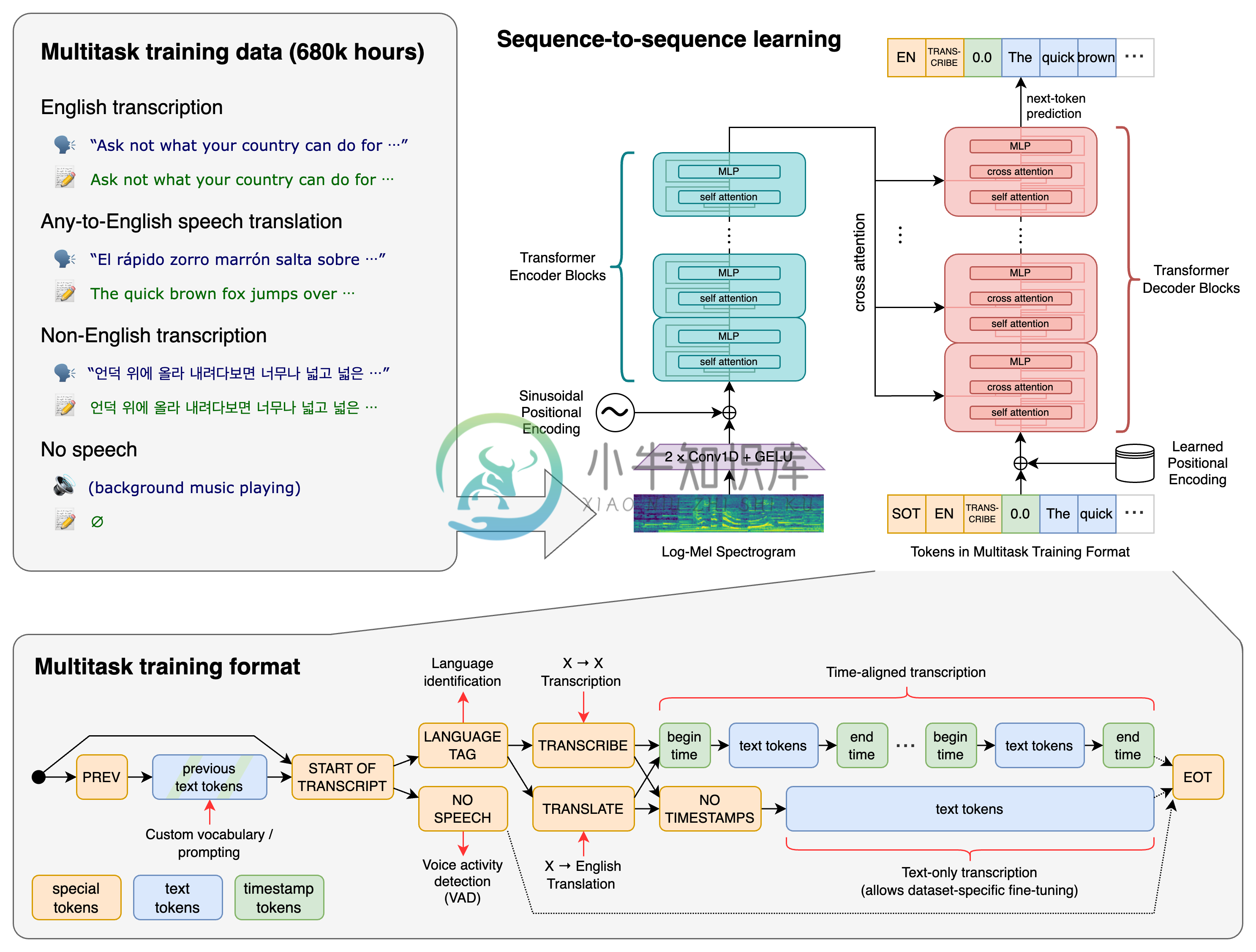
Whisper 是 OpenAI 开源的自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。
设置
我们使用 Python 3.9.9 和 PyTorch 1.10.1 来训练和测试我们的模型,但代码库预计将与 Python 3.7 或更高版本以及最新的 PyTorch 版本兼容。 代码库还依赖于一些 Python 包,以下命令将从该存储库中提取并安装最新提交及其 Python 依赖项
pip install git+https://github.com/openai/whisper.git
它还需要在你的系统上安装命令行工具 ffmpeg,大多数包管理器都可以使用:
# on Ubuntu or Debian sudo apt update && sudo apt install ffmpeg # on MacOS using Homebrew (https://brew.sh/) brew install ffmpeg # on Windows using Chocolatey (https://chocolatey.org/) choco install ffmpeg # on Windows using Scoop (https://scoop.sh/) scoop install ffmpeg
目前 Whisper 有 9 种模型(分为纯英文和多语言),其中四种只有英文版本,开发者可以根据需求在速度和准确性之间进行权衡,以下是现有模型的大小,及其内存要求和相对速度:
| 大小 | 参数 | 纯英文模型 | 多语言模型 | 所需显存 | 相对速度 |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
-
近期,OpenAI发布了Whisper语音识别模型,声称其在英语语音识别方面已接近人类水平的鲁棒性和准确性。出于对自动语音识别的兴趣,本人对此进行了一些尝试,看看它对中文语音识别的效果。 本内容仅供对语音识别有兴趣或者仅仅希望应用的入门朋友参考。 一、安装 测试电脑:MacBook Pro 测试系统:MacOS Monterey 12.6 1、安装brew
-
1.根据提示安装依赖 : 安装Whisper前先安装依赖 1.1安装torch: ERROR: Could not find a version that satisfies the requirement torch (from versions: none) 经过了解torch是 pip install torch Looking in indexes: https://mirrors.ali
-
关于 whisper Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as w
-
首先,请确保你的CentOS系统已经更新到最新版本。 安装 pip: 使用命令 "yum install python3-pip" 安装 pip。 安装 Whisper: 使用命令 "pip3 install whisper" 安装 Whisper。 配置 Whisper: 使用命令 "whisper configure" 进行配置。 开始使用: 使用命令 "whisper" 开始使用 Whisp
-
OpenAI-API-中文版 一. Introduction 介绍 如果你想使用我们的API,你可以通过 HTTP 请求从任何语言与 API 进行交互,也可以使用我们的官方 Python 绑定、官方 Node.js库 或 社区维护的库。 若要安装官方 Python 绑定,请运行以下命令: pip install openai 要安装官方的 Node.js 库,请在您的 Node.js 项目目录中
-
由于连接到不同的API,我目前正在开发一个工具,允许我阅读所有的通知。 它工作得很好,但现在我想用一些声音命令来做一些动作。 就像当软件说“一封来自Bob的邮件”时,我想说“阅读”或“存档”。 我的软件是通过一个节点服务器运行的,目前我没有任何浏览器实现,但它可以是一个计划。 在NodeJS中,启用语音到文本的最佳方式是什么? 我在它上面看到了很多线程,但主要是使用浏览器,如果可能的话,我希望在一
-
语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产
-
识别简单的语句。
-
光环板内置的麦克风和Wi-Fi功能相结合,可以实现语音识别相关的应用。通过接入互联网,可以使用各大主流科技公司提供的语音识别服务,像是微软语音识别服务。使用联网功能需要登陆慧编程账号。 注册/登陆慧编程 点击工具栏右侧的登陆/注册按钮,依据提示登陆/注册账号。 启用上传模式 点击启用上传模式。 新建语音识别项目 我们将新建一个语音识别项目,使用语音来点亮光环板的LED灯。 连接网络 1. 添加事件
-
1.1. ASR(语音识别) HTTP接口文档 1.1.1. 概述 1.1.2. 服务地址 1.1.3. 协议详解 1.1.4. HTTP API 接入参考Demo 1.1.5. 协议概述 1.1. ASR(语音识别) HTTP接口文档 1.1.1. 概述 本文档目的是描述Rokid云ASR(语音识别)Http接口协议,面向想要了解ASR细节,并具有一定开发能力的开发者或用户。 1.1.2. 服务
-
1.1. ASR(语音识别) WebSocket接口文档 1.1.1. 概述 1.1.2. 服务地址 1.1.3. 协议详解 1.1.4. 协议地址 1.1.5. 协议概述 1.1.6. ASR 云端一些细节 1.1. ASR(语音识别) WebSocket接口文档 1.1.1. 概述 本文档目的是描述Rokid云ASR(语音识别)WebSocket接口协议,面向想要了解ASR细节,并具有一定开发
-
1.1.1. 开放平台接口定义文档(http版) - 语音识别 1.1.2. 前言 1.1.3. 文档版本 1.1.4. 服务地址 1.1.5. 协议地址 1.1.6. 协议概述 1.1.7. 示例 1.1.1. 开放平台接口定义文档(http版) - 语音识别 Table of Contents 前言 文档版本 服务地址 协议地址 协议概述 认证 说明 语音识别 请求 响应 示例 1.1.2.
-
我正在为嵌入式设备的语音相关语音识别解决方案寻找解决方案。我已经研究过Pocketsphinx,但由于我仍然不熟悉它,我想也许更有经验的人可能会知道。是否有可能使用Pocketsphinx来实现这样的语音识别。它应该记录音频,提取其特征,然后将其与所说的任何内容进行匹配,而不是使用声学和语言模型。是否有可能使用Pocketsphinx实现此流程?如果没有,有人能为这样的解决方案指出正确的方向吗?谢