《性能》专题
-
sql计数性能问题
我有两个表用于存储员工出勤信息。 一个表存储emp Id以及相应的时间和日期时间信息。第二个表存储其他员工详细信息,如员工Id、员工姓名等。。。我需要生成一份报告,显示emp每天工作的总小时数,一个状态列存储详细信息,如Present if total hours 我写了查询来获取每一个细节,但性能是不可接受的,需要大约30-35分钟来获取所有细节 如果排除天数计算逻辑,大约需要1-2分钟 表的结
-
意外的#temp表性能
问题内容: 开放赏金:好吧,老板需要答案,我需要加薪。这似乎不是一个冷缓存问题。 更新: 我没有遵循以下建议。客户统计数据如何得出一组有趣的数字。 #temp 与 @temp INSERT,DELETE和UPDATE语句的数量0对1 受INSERT,DELETE或UPDATE语句影响的行0 vs 7647 SELECT语句数0 vs 0 SELECT语句返回的行0 vs 0 交易数量0对1 最有趣
-
火花流口水-性能
我在Scala/Spark中有一个批处理作业,它根据一些输入动态创建Drools规则,然后评估规则。我还有一个与要插入到规则引擎的事实相对应的输入。 到目前为止,我正在一个接一个地插入事实,然后触发关于这个事实的所有规则。我正在使用执行此操作。 seqOp运算符的定义如下: 以下是生成的规则的示例: 对于同一RDD,该批次花了20分钟来评估3K规则,但花了10小时来评估10K规则! 我想知道根据事
-
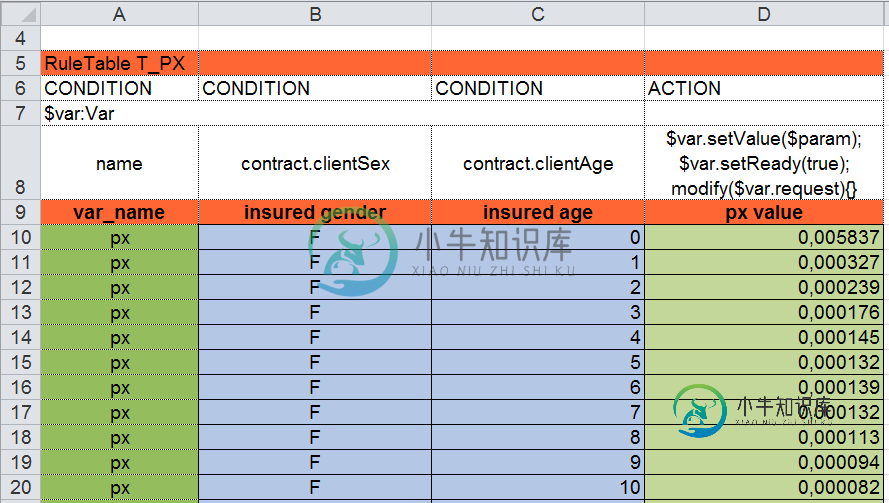 决策表的Drools性能
决策表的Drools性能当我尝试使用Drools引擎计算保险费时,我有一个潜在的性能/内存瓶颈。 我在我的项目中使用Drools将业务逻辑与java代码分开,我决定也将其用于溢价计算。 我是不是用错了口水 如何以更高性能的方式满足要求 详情如下: 我必须为给定的合同计算保险费。 合约配置有 productCode(来自字典的代码) 合同代码(来自字典的代码) 客户的个人资料(例如年龄、地址) 保险金额(SI) 等等 目前
-
Project Euler p14增强性能
我已经用以下代码完成了项目欧拉问题14: 将最长的Collatz数字序列从1000000降到2大约需要39秒。我想知道我是否可以缓存任何值来加速我的代码,以及如何在不获得无限循环的情况下从代码中删除if longestSequence[-1]==2,以及任何其他可以改进代码的方法。 为正整数集定义以下迭代序列: n→n/2(n为偶数)n→3n 1(n为奇数) 使用上述规则,从13开始,我们生成以下
-
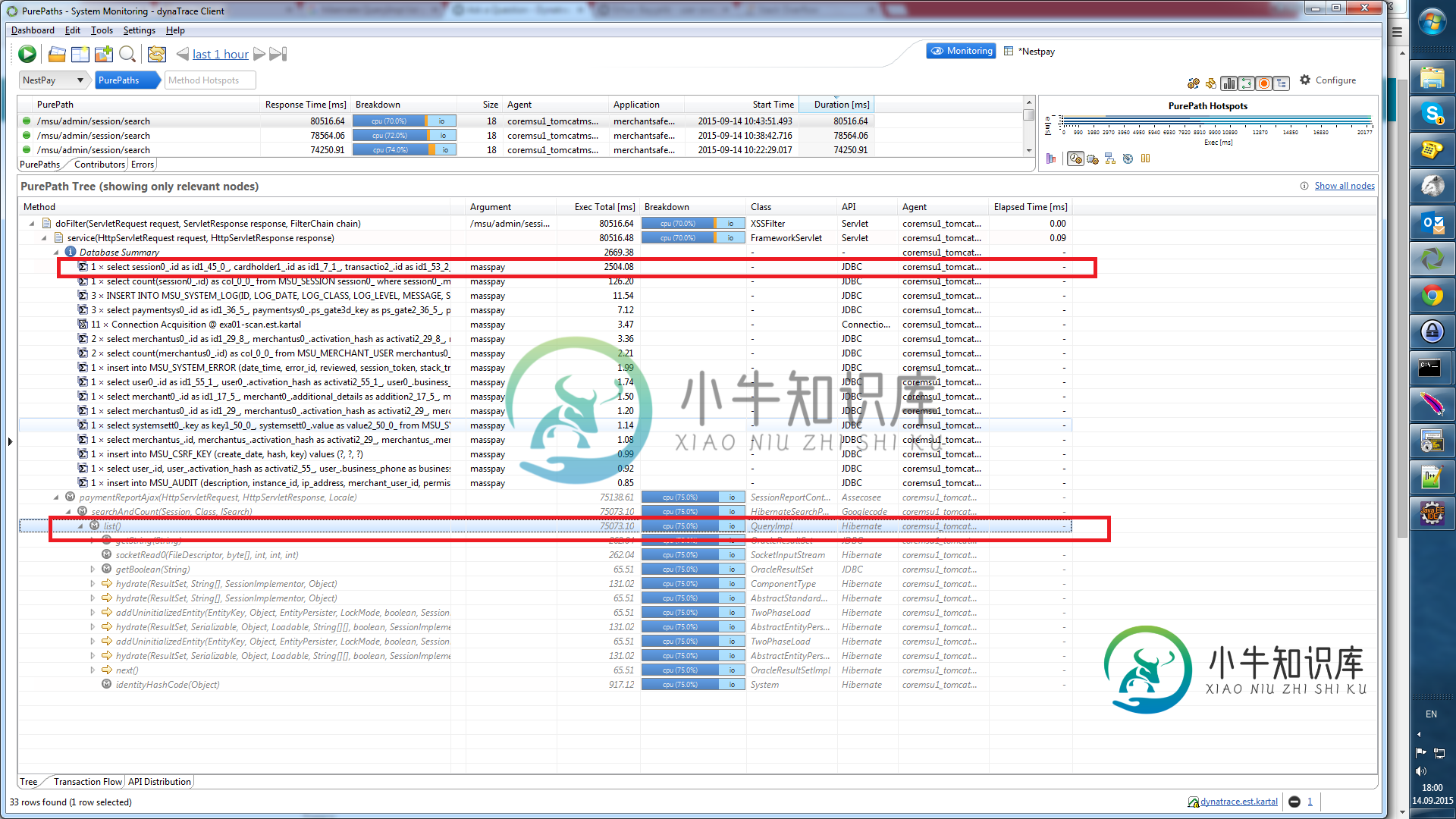 Hibernate:QueryImpl列表方法性能
Hibernate:QueryImpl列表方法性能对于我们的报告UI,我们查询sessions对象并在屏幕中列出它。为了查询数据,我们使用Hibernate和通用Dao实现。在使用Dynatrace之前,我们总是将此查询归咎于数据库,但在开始使用Dynatrace之后,它告诉我们,瓶颈在QueryImpl的代码中。列表方法。我们的Prod和Dev性能都很差,Prod中的总计数记录约为200万条,需要75秒(是的,超过1分钟:()下面的屏幕截图显示
-
HashSet vs ArrayList包含性能
问题内容: 在处理大量数据时,我经常发现自己在做以下事情: 类似于“倾销”列表中的集合内容。我通常这样做是因为添加的元素通常包含要删除的重复项,这似乎是删除它们的一种简便方法。 考虑到这个目标(避免重复),我也可以这样写: 因此,无需将集“转储”到列表中。但是,在插入每个元素之前,我会做一个小检查(我假设HashSet也是如此) 这两种可能性中的任何一种是否明显更有效? 问题答案: 集合将提供更好
-
react性能优化方案
本文向大家介绍react性能优化方案相关面试题,主要包含被问及react性能优化方案时的应答技巧和注意事项,需要的朋友参考一下 重写shouldComponentUpdate来避免不必要的dom操作0 使用 production 版本的react.js0 使用key来帮助React识别列表中所有子组件的最小变化。 参考链接: https://segmentfault.com/a/119000000
-
Spark性能如何调优?
本文向大家介绍Spark性能如何调优?相关面试题,主要包含被问及Spark性能如何调优?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 避免创建重复的RDD,尽量复用同一RDD,尽量避免使用shuffle类算子,优化数据结构,使用Hive ETL预处理数据,过滤少数导致倾斜的key,提高shuffle操作的并行度,两阶段聚合,将reduce join转为map join。
-
Java方法调用性能
问题内容: 我有这段代码在做Range Minimum Query 。当t = 100000时,i和j始终在每条输入行中更改,因此在Java 8u60中其执行时间约为12秒。 当我提取一个新方法以找到最小值时,执行时间快了4倍(约2.5秒)。 我一直认为方法调用很慢。但是这个例子却相反。Java 6也演示了这一点,但是在两种情况下(17秒和10秒)执行时间都慢得多。有人可以对此提供一些见识吗? 问
-
位图堆扫描性能
问题内容: 我有一张大桌子。位图堆扫描步骤需要5秒钟以上。 有什么我可以做的吗?我在表中添加了列,对它使用的索引重新索引会有所帮助吗? 我对数据进行合并和求和,所以我不会将50万条记录返回给客户端。 我使用postgres 9.1。 这里的解释: 询问: 表格: 是具有4个不同值的字段。 目前具有10K个不同的值。 问题答案: 在(按此顺序)上创建一个复合索引。 请注意,如果您选择500k条记录(
-
 iOS性能优化浅析
iOS性能优化浅析本文向大家介绍iOS性能优化浅析,包括了iOS性能优化浅析的使用技巧和注意事项,需要的朋友参考一下 本文将从原理出发,解释卡顿发生的原理,然后会讲解项目中行之有效的几个优化点,最后会展望一下接下来将要尝试的方向。下面进入正题。 屏幕显示的原理 屏幕显示原理 我们知道,远古时代的CRT显示器的显示原理是用电子枪扫描荧光屏来发光。如上图所示,电子枪按照从左到右,然后从上到下的顺序扫描。当电子枪换到新的
-
SQL查询-性能优化
问题内容: 我不太擅长SQL,因此我要求你们提供有关编写查询的帮助。 [SQL查询-表连接问题]https://codingdict.com/questions/208252) 我得到了答案,并且可以正常工作!它只是明显的缓慢。我讨厌这样做,但是我真的希望有人在那里推荐一些优化查询的方法。我什至没有自己尝试过,因为我对SQL不够了解,甚至无法开始使用谷歌搜索。 问题答案: 可能有帮助的是在要加入的
-
MySQL多次插入性能
问题内容: 我的数据包含约30 000条记录。而且我需要将此数据插入到MySQL表中。我将这些数据按包进行分组(按1000分组),并创建多个插入,如下所示: 如何优化此插入的性能?每次可以插入1000条以上的记录吗?每行包含大小约为1KB的数据。谢谢。 问题答案: 您需要检查mysql服务器配置,尤其是检查缓冲区大小等。 您可以从表中删除索引(如果有的话),以使其更快。一旦数据输入,就创建索引。
-
表与视图的性能
问题内容: 最近开始使用一个数据库,其中的约定是为每个表创建一个视图。如果您假设表和视图之间存在一对一的映射,那么我想知道是否有人可以告诉我这样做的性能影响。顺便说一句,这是在Oracle上。 问题答案: 假设问题是关于非具体化视图的,那么- 确实取决于该视图所基于的查询以及对其执行的操作。有时,谓词可以由优化器推入视图查询中。如果不是这样,那将不如表格本身好。视图建立在表格之上- 为什么您期望性