
Hibernate:QueryImpl列表方法性能

对于我们的报告UI,我们查询sessions对象并在屏幕中列出它。为了查询数据,我们使用Hibernate和通用Dao实现。在使用Dynatrace之前,我们总是将此查询归咎于数据库,但在开始使用Dynatrace之后,它告诉我们,瓶颈在QueryImpl的代码中。列表方法。我们的Prod和Dev性能都很差,Prod中的总计数记录约为200万条,需要75秒(是的,超过1分钟:()下面的屏幕截图显示了Dynatrace屏幕截图,它显示了Hibernate QueryImpl list方法中的问题。我在DEV环境中检查了具有500K条记录的应用程序,在DEV中也需要30秒,在这个查询中同样的方法需要28秒。我在dynatrace和jvisualvm中跟踪应用程序获取堆转储并进行分析。还要检查samurai和dyntarace的线程转储,但找不到任何锁定线程或许多特殊类实例。我分享了dynatrace纯路径截图和使用Spring事务注释的方法调用。
ReadOnly.java
@Target({ ElementType.METHOD, ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Transactional(readOnly = true)
public @interface ReadOnly {
}
会话服务。Java语言
@Override
@ReadOnly
public SearchResult<Session> getReport(ISearch search) {
return sessionDao.searchAndCount(search);
}
SessionDao.java
public <RT> SearchResult<RT> searchAndCount(ISearch search) {
if (search == null) {
SearchResult<RT> result = new SearchResult<RT>();
result.setResult((List<RT>) getAll());
result.setTotalCount(result.getResult().size());
return result;
}
return searchAndCount(persistentClass, search);
}
我花了2-3天来调查这个问题,我真的很想知道原因。
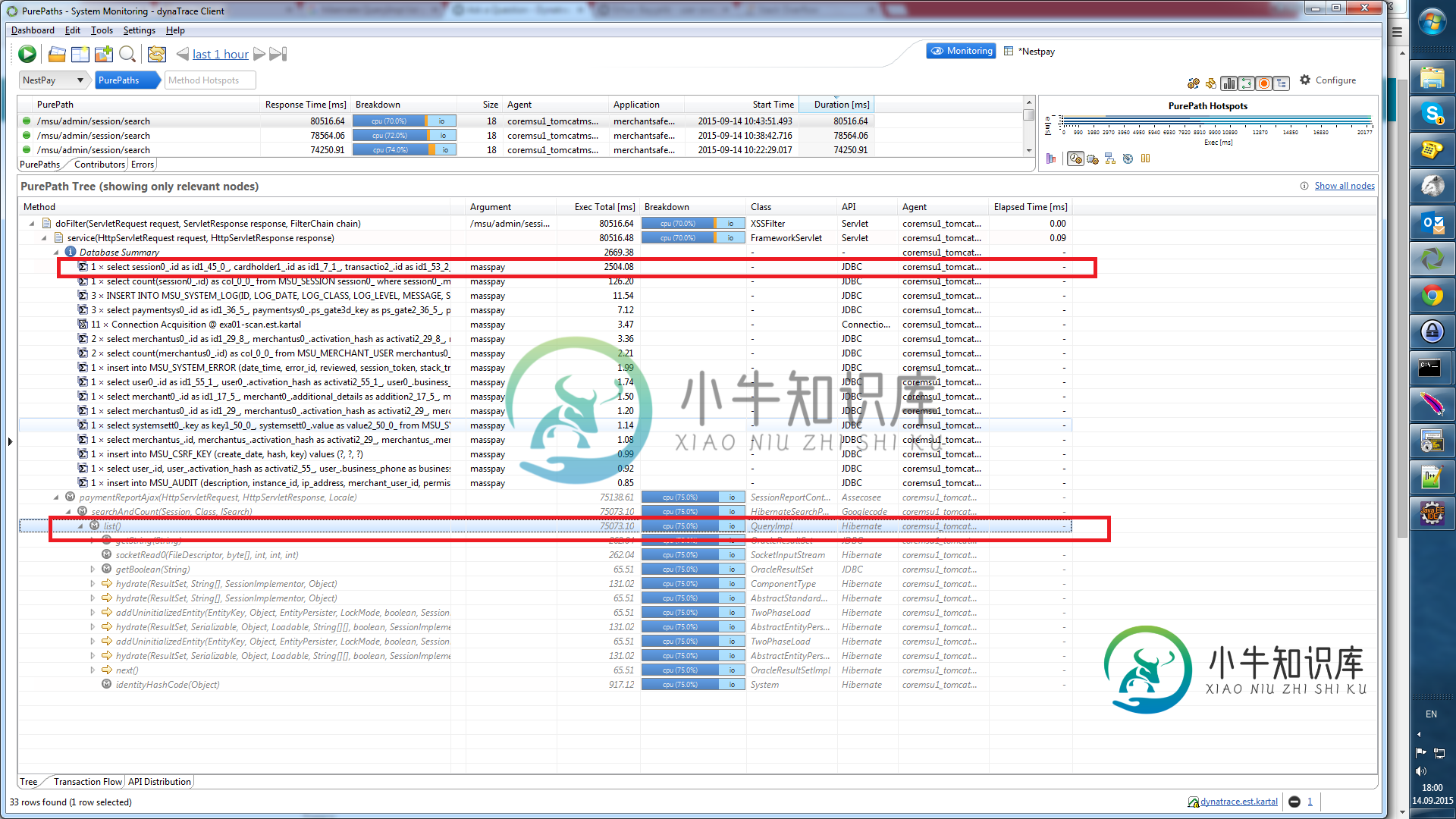
编辑:我从2M表中查询了50条记录,我使用分页方法,在屏幕截图中我提到在数据库中需要2.5秒,但在内存中花费75秒QueryImpl列表方法。所以我已经从2M表中查询了50条记录,该表在日期字段中有索引。请检查屏幕截图红色矩形。
共有1个答案

首先感谢@M.Deinum的评论,这些评论帮助我们解决了这个问题。问题描述如下,请回答以下问题:
- 问题和公认答案描述问题
- 另一个相关问题和答案
- 接受的回答提出了有用的建议
在我的情况下,第一次运行并需要75秒的PROD查询如下。
SessionWithJOINFETCH。sql
SELECT
session0.*,
cardholder0.*,
transaction0.*
FROM
MSU_SESSION session0 LEFT OUTER JOIN MSU_CARD_HOLDER cardholder0
ON session0.card_holder_id = cardholder0_.id LEFT OUTER JOIN MSU_TRANSACTION transaction0
ON session0.id = transaction0_.session_id
WHERE
(
session0.status IN(
? ,
?
)
)
AND(
session0.sessionType IS NULL
OR session0.sessionType IN(
? ,
?
)
)
AND session0.session_create_timestamp >= ?
AND session0.session_create_timestamp <= ?
ORDER BY
session0.session_create_timestamp DESC
并且在日志中我看到警告:
firstResult/max使用集合获取指定的结果;在内存中应用!
这意味着我们在内存中使用分页(用于Oracle rowNum)。首先运行sql时可以看到它没有任何rowNum,它根据标准获取所有数据,然后“firstResult/maxResult指定集合获取;在内存中应用!”在内存中应用firstResult/maxResult需要时间。
原因是我们正在使用带有setMaxResult的JOIN FETCH。根据Hibernate论坛和上面的问题链接,这是Hibernate的一项功能,因此在删除下面的关系后,您不应该将setMaxResult与JOIN FETCH一起使用(至少使用1-N关系),sql是由Hibernate创建的,现在它的性能更好了。
后删除JOINFETCH. sql
SELECT
*
FROM
(
SELECT
session0_.*
FROM
MSU_SESSION session0_
WHERE
(
session0_.status IN(
? ,
?
)
)
AND(
session0_.sessionType IS NULL
OR session0_.sessionType IN(
? ,
?
)
)
AND session0_.session_create_timestamp >= ?
AND session0_.session_create_timestamp <= ?
ORDER BY
session0_.session_create_timestamp DESC
)
WHERE
rownum <= ?
我不知道为什么要创建一个内部sql,但它的html" target="_blank">性能比以前要好,现在您可以看到,查询中添加了rownum,分页是在DB级别完成的。
firstResult/max使用集合获取指定的结果;在内存中应用!
警告也消失了。
-
数组的方法列表。 merge sort
-
表单(form)以及例如 <input> 的控件(control)元素有许多特殊的属性和事件。 当我们学习了这些相关内容后,处理表单会变得更加方便。 导航:表单和元素 文档中的表单是特殊集合 document.forms 的成员。 这就是所谓的“命名的集合”:既是被命名了的,也是有序的。我们既可以使用名字,也可以使用在文档中的编号来获取表单。 document.forms.my - name="m
-
我的问题是这个问题的延伸。 要获得属性列表,我们可以使用以下代码: 但是如果我想得到100个不同的属性。 选项#1: 那么,重写这一行100次会更好吗?或者我应该简单地运行1个循环并收集那里的所有属性。 选项2:
-
问题内容: 我有一个列表列表(由于必须动态生成它,所以不能是元组),它的结构为一个int和一个float的列表列表,像这样: 我想对它进行排序,但我只能设法获得内置的排序功能,以便按列表的第一个元素对其进行排序,或者什么也不做,但是我需要按列表的第二个元素对它们进行排序,但是我没有不想实现我自己的排序功能。所以我想要的一个例子是: 有人可以告诉我如何获取内置的排序功能之一来执行此操作吗? 问题答案
-
我需要一个解决方案来提高这种方法的性能。我需要使用LinkedHashMap按顺序插入这些输入,它工作得很好。然而,我不喜欢这个解决方案,因为我有一个列表,每次我都要通过它来检索我想插入到这个地图中的输入。 这是我的密码 我需要一种方法来检索这些对象,而无需重复此列表3次。
-
问题内容: 我很好奇将这种数据对象唯一化的有效方法: 对于每个数据对,左边的数字字符串加上右边的类型说明了数据元素的唯一性。返回值应为与testdata相同的列表列表,但仅保留唯一值。 问题答案: 您可以使用一组: 您还可以看到此页面,该页面对各种保留或不保留顺序的方法进行了基准测试。