
决策表的Drools性能

当我尝试使用Drools引擎计算保险费时,我有一个潜在的性能/内存瓶颈。
我在我的项目中使用Drools将业务逻辑与java代码分开,我决定也将其用于溢价计算。
- 我是不是用错了口水
- 如何以更高性能的方式满足要求
详情如下:
我必须为给定的合同计算保险费。
合约配置有
- productCode(来自字典的代码)
- 合同代码(来自字典的代码)
- 客户的个人资料(例如年龄、地址)
- 保险金额(SI)
- 等等
目前,保费使用以下公式计算:
premium := SI * px * (1 + py) / pz
哪里:
- px是Excel文件中参数化的因子,取决于2个属性(客户端的年龄和性别)
- py是Excel文件中参数化的因子,取决于4个合约的属性
- pz-类似地
- R1–java代码不知道公式,
- R2-java代码对公式依赖性一无所知,换句话说,premium依赖于:px、py、pz、
- java代码对参数的依赖性一无所知,我的意思是px依赖于客户机的年龄和性别,等等
随着R1、R2和R3的实现,我将java代码与业务逻辑分离,任何业务分析师(BA)都可以修改公式并添加新的依赖项,而无需重新部署。
我有一个合同域模型,它由类contract、Product、Client、Policy等组成。合同类别定义为:
public class Contract {
String code; // contractCode
double sumInsured; // SI
String clientSex; // M, F
int professionCode; // code from dictionary
int policyYear; // 1..5
int clientAge; //
... // etc.
此外,我还引入了Var类,它是任何参数化变量的容器:
public class Var {
public final String name;
public final ContractPremiumRequest request;
private double value; // calculated value
private boolean ready; // true if value is calculated
public Var(String name, ContractPremiumRequest request) {
this.name = name;
this.request = request;
}
...
public void setReady(boolean ready) {
this.ready = ready;
request.check();
}
...
// getters, setters
}
最后—请求类:
public class ContractPremiumRequest {
public static enum State {
INIT,
IN_PROGRESS,
READY
}
public final Contract contract;
private State state = State.INIT;
// all dependencies (parameterized factors, e.g. px, py, ...)
private Map<String, Var> varMap = new TreeMap<>();
// calculated response - premium value
private BigDecimal value;
public ContractPremiumRequest(Contract contract) {
this.contract = contract;
}
// true if *all* vars are ready
private boolean _isReady() {
for (Var var : varMap.values()) {
if (!var.isReady()) {
return false;
}
}
return true;
}
// check if should modify state
public void check() {
if (_isReady()) {
setState(State.READY);
}
}
// read number from var with given [name]
public double getVar(String name) {
return varMap.get(name).getValue();
}
// adding uncalculated factor to this request – makes request IN_PROGRESS
public Var addVar(String name) {
Var var = new Var(name, this);
varMap.put(name, var);
setState(State.IN_PROGRESS);
return var;
}
...
// getters, setters
}
现在,我可以将这些类用于这样的流:
请求=new ComptPremiumRequest(合约)- 使用
state==INIT创建请求
- 创建变量(“px”),并准备好==false
- 在
px上设置计算值
- 使其
就绪==true
我创建了2条DRL规则,并准备了3个决策表(px.xls、py.xls,…)BA提供的系数。
规则1-合同\保费\准备。drl:
rule "contract premium request - prepare dependencies" when $req : ContractPremiumRequest (state == ContractPremiumRequest.State.INIT) then insert( $req.addVar("px") ); insert( $req.addVar("py") ); insert( $req.addVar("pz") ); $req.setState(ContractPremiumRequest.State.IN_PROGRESS); end规则2-contract\u premium\u calculate。drl:
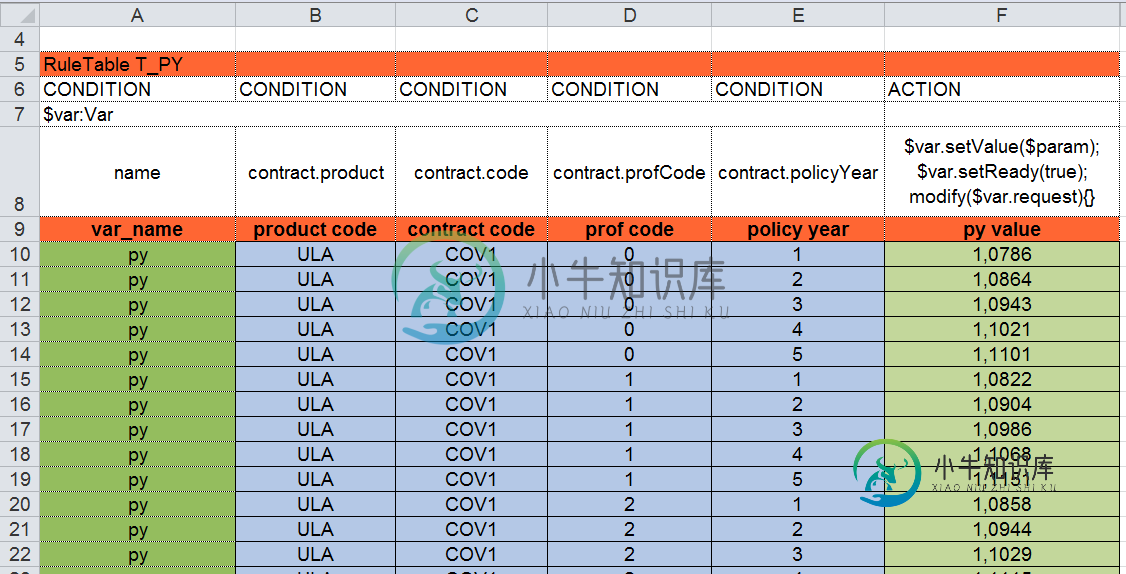
rule "contract premium request - calculate premium" when $req : ContractPremiumRequest (state == ContractPremiumRequest.State.READY) then double px = $req.getVar("px"); double py = $req.getVar("py"); double pz = $req.getVar("pz"); double si = $req.contract.getSumInsured(); // use formula to calculate premium double premium = si * px * (1 + py) / pz; // round to 2 digits $req.setValue(premium); end决策表px。xls:
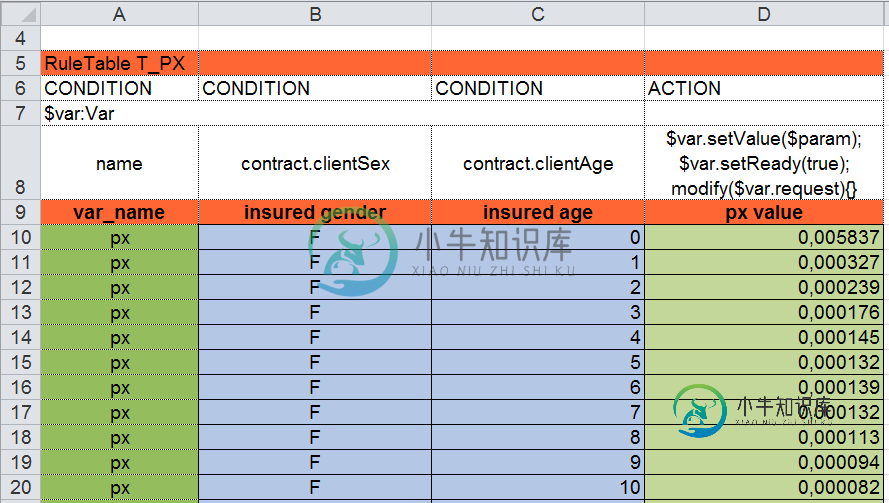
决策表py.xls:
KieContainer在启动时构建一次:
dtconf = KnowledgeBuilderFactory.newDecisionTableConfiguration(); dtconf.setInputType(DecisionTableInputType.XLS); KieServices ks = KieServices.Factory.get(); KieContainer kc = ks.getKieClasspathContainer();现在,为了计算给定合同的保费,我们写道:
ContractPremiumRequest request = new ContractPremiumRequest(contract); // state == INIT kc.newStatelessKieSession("session-rules").execute(request); BigDecimal premium = request.getValue();事情就是这样:
- 规则1触发
ComptPremiumRequest[INIT] - 此规则创建并添加px、py和pz依赖项(
Var对象) - 为每个px、py、pz对象触发正确的excel行并使其准备就绪
- 规则2为
ComptPremiumRequest[READY]触发并使用公式
- PX决策表有~100行,
- PY决策表有~8000行,
- PZ决策表有~50行。
>
- 使用
加载和初始化决策表的第一次计算需要大约45秒-这可能会成为问题。
每次计算(在一些热身之后)需要大约0.8毫秒-这对于我们的团队来说是可以接受的。
堆消耗量约为150 MB,这是一个问题,因为我们预计将使用更多的大表。
- 我用口水的方式不对吗?
- 如何以更高性能的方式满足要求?
- 如何优化内存使用?
==========编辑(2年后)==========
这是两年后的简短总结。
正如我们所预期的那样,我们的系统发展得非常快。我们最终得到了500多个表(或矩阵),其中包括保险定价、精算因素、保险范围配置等。一些表的大小超过了100万行。我们使用了drools,但无法处理性能问题。
最后我们使用了Hyperon引擎(http://hyperon.io)
这个系统是一个野兽-它允许我们在大约10毫秒的总时间内运行数百个规则匹配。
我们甚至能够在UI字段上的每个KeyType事件上触发完整的策略重新计算。
正如我们所了解的,Hyperon对每个规则表使用快速内存索引,这些索引以某种方式被压缩,因此几乎没有内存占用。
我们现在还有一个好处——所有定价、因素和配置表都可以在线修改(值和结构),这对java代码是完全透明的。应用程序只需继续使用新逻辑,无需开发或重启。
然而,我们需要一些时间和努力来充分了解Hyperon:)
我发现我们的团队一年前进行了一些比较——它显示了引擎初始化(drools/hyperon)和从jvisualVM角度进行的100k简单计算:

共有2个答案

在更仔细地阅读了这个问题之后,我将提出一些建议:
比起Excel电子表格,我更喜欢关系数据库。
这些都是非常简单的计算。我认为这种模式太过分了。对于这种规模的问题来说,规则引擎似乎太大了。
我会更简单地编写代码。
使计算基于接口,以便您可以通过注入新的类实现来修改它。
了解如何编写Junit测试。
我的第一选择是一个简单的决策表计算,没有规则引擎,在关系数据库中维护因子。
Rete规则引擎是if/else或switch语句的重锤。我认为如果你不利用诱导功能,那就太过分了。
我不会把任何东西放在会议上。我正在设想一个幂等REST服务,它接收一个请求并返回一个带有premium的响应,以及其他必须返回的内容。
在我看来,您过早地将解决方案过度复杂化了。尽可能做最简单的事情;衡量绩效;根据您得到的数据和需求,根据需要进行重构。
你是一个有经验的开发人员吗?你是一个人还是团队的一员?这是一个你以前从未做过的新系统吗?

问题是您为相对较少的数据创建了大量代码(表产生的所有规则)。我见过类似的案例,它们都受益于将表作为数据插入。PxRow、PyRow和PzRow应该这样定义:
class PxRow {
private String gender;
private int age;
private double px;
// Constructor (3 params) and getters
}
数据仍然可以保存在(更简单的)电子表格或其他任何你喜欢的地方,供英国航空管理局的工作人员输入数据。将所有行插入为事实PxRow、PyRow、PzRow。那么您需要一个或两个规则:
rule calculate
when
$c: Contract( $cs: clientSex, $ca: clientAge,
$pc: professionCode, $py: policyYear,...
...
$si: sumInsured )
PxRow( gender == $cs, age == $ca, $px: px )
PyRow( profCode == $pc, polYear == $py,... $py: py )
PzRow( ... $pz: pz )
then
double premium = $si * $px * (1 + $py) / $pz;
// round to 2 digits
modify( $c ){ setPremium( premium ) }
end
忘记流水和其他装饰吧。但您可能需要另一条规则,以防您的合同与Px、Py或Pz不匹配:
rule "no match"
salience -100
when
$c: Contract( premium == null ) # or 0.00
then
// diagnostic
end
-
我有一个drools决策表,其中包含条件和位置类型 我的excel如下所示 设置参数的代码如下 我按要求提供的excel文件条件对象: 需求级别==$参数位置类型==$参数 当我像上面那样设置时,我得到以下错误: 创建KieBase时出错[消息[id=1,级别=错误,路径=规则.xls,行=8,列=0文本=[错误102]行8:14不匹配的输入'=='在规则“替换规则”中],消息[id=2,级别=错
-
场景如下: 我有一个java pojo类,具有2个变量和以及适当的getter和setter。我正在使用决策表流,我想要: 条件:当类型设置为“1”时 操作:调用name类的setName setter,并从excel中设置适当的参数 现在,我想在java中访问name的这个集值。 这就是我所做的: Name.java- MainClass.java-这有口水实现!! 决策表e:: http://
-
有人能帮我调试Drools中的决策表吗。对于我们的项目,我们正在创建一个包含1000多条规则的决策表。每当他们在规则中出现错误时,谁的电子表格不工作,也不显示准确的错误在哪里。
-
我对口水和决策表还不熟悉。我需要创建一个规则,使用规则中的人的年龄来测试一个人是否年长/年轻。该规则在无限循环中工作。 这是规则,是基本的,人的年龄 我的角色类是一个简单的POJO,用于测试决策表: Person类(静态,在主类中): 我的主要方法是在JRE 1.7中使用drools 6.5: 这是无限循环的输出。 感谢您提供的任何提示、链接、教程等。
-
我在excel电子表格中有一个drools决策表,其中有两条规则。(此示例已大大简化,我正在使用的示例有更多规则。) 我的目标是让规则自上而下地触发,随后的规则可能取决于早期规则对事实/对象所做的更改。 这个问题有解决办法吗?任何帮助都将不胜感激,谢谢!
-
我对Drools很陌生,正在尝试编译这个简单的。xls作为决策表,并得到这个非常无用的编译错误:[错误102]第8:1行规则“Patient Notification\u 11”中的输入“then”不匹配 我已经附加了xls以及随之而来的简单对象。我已经阅读了有关此内容的所有材料,但无法弄清楚为什么我会收到以下错误。我很感谢您提前提供帮助。具体来说,我想知道是否有办法检查并查看导致此错误的幕后原因