《大数据开发》专题
-
错误ORA-01000:超过最大打开游标数
在Eclipse中,我遇到了这个错误:*错误ORA-01000:超过了最大打开游标数,我已经在块中关闭了连接,但我不知道为什么会出现这个错误,这是我的JAVA代码。请帮帮我!
-
从具有条件的不同大小的数据帧中复制数据
我有2个不同大小的数据帧df1-df2(df2比df1有更多的行和列)。 我试图分配的值从df2['率']到df1['率'],在其中df1['单元']==df2['单元']行。 期望的输出是 我尝试了不同的方法: 只能比较相同标记的Series对象 给我假消息 我认为这来自于这样一个事实,即两个数据帧从一开始就有不同的大小。然而,我不明白为什么它应该阻止它做比较。我不确定如何从这里开始。
-
如何在Spring Boot Restful中更改大量数据(更新多个数据)
我想一次更改大量数据,如何更改? 在这个DAO下只更改一个数据,如果我想更改很多怎么办?
-
 屡败屡战的大数据秋招之面试必问数据倾斜
屡败屡战的大数据秋招之面试必问数据倾斜面试必问。大数据面试绝对重点!! 面过的12家,有字节、快手、美的、顺丰、OPPO、京东、贝壳都被问道过。菜鸡的我没有实习经历项目中也没有遇到过数据倾斜的情况,每次被问到都如坐针毡思维混乱一通乱说。😅😅给各位面试官留下了逻辑性差、实践少的差印象。特把这个问题单独摘出来进行深入整理!!!! 各位朋友,本人实践经验有限,下文如有错误劳烦您指出,万分感谢! 花式提问😅😅 你遇到过Spark 的数
-
 Oracle数据库中SQL开窗函数的使用
Oracle数据库中SQL开窗函数的使用本文向大家介绍Oracle数据库中SQL开窗函数的使用,包括了Oracle数据库中SQL开窗函数的使用的使用技巧和注意事项,需要的朋友参考一下 开窗函数:在开窗函数出现之前存在着很多用 SQL 语句很难解决的问题,很多都要通过复杂的相关子查询或者存储过程来完成。为了解决这些问题,在 2003 年 ISO SQL 标准加入了开窗函数,开窗函数的使用使得这些经典的难题可以被轻松的解决。目前在 MSSQ
-
在大熊猫数据框中提取具有最大值的行
问题内容: 但是,即使该组中有多个具有最大值的记录,我也只需要每组一个记录。 在下面的示例中,我需要一条记录用于“ s2”。对我来说,哪一个都没关系。 问题答案: 您可以使用 设置来实现你的目标 再次更新 很抱歉误解您的意思。如果您要一个组中最大数量的组,可以先对其进行排序
-
从数据结构中的最大HBLT中删除最大元素
本文向大家介绍从数据结构中的最大HBLT中删除最大元素,包括了从数据结构中的最大HBLT中删除最大元素的使用技巧和注意事项,需要的朋友参考一下 在Max HBLT中,将根放在根上。如果根被删除,则两个最大的HBLT(即左和右)将分开。通过再次将这两个Max HBLT融合在一起,我们可以将它们合并为一个。因此,在融合之后,所有元素都将存在,除了已删除的元素。
-
二次开发 - 常用数据表说明 - dede_sysconfig|系统参数表
dede_sysconfig|系统参数表: 字段 类型 整理 属性 Null 默认 额外 aid smallint(8) UNSIGNED 是 0 参数ID varname varchar(20) utf8_general_ci 是 参数名 info varchar(100) utf8_general_ci 是 变量说明 groupid smallint(6) 是 1 变量类型ID type va
-
Android:通过BLE发送大于20个字节的数据
问题内容: 通过连接到外部BLE设备,我最多可以发送20个字节的数据。如何发送大于20个字节的数据。我已经读到我们必须将数据分段或将特征拆分为所需的部分。如果我假设我的数据是32字节,你能否告诉我我需要在代码中进行的更改才能使其正常工作?以下是我的代码中必需的摘录: 这是我用于发送数据的代码。在以下onclick事件中使用“发送”功能。 当大于20个字节时,则仅接收前20个字节。如何纠正呢? 为了
-
 阶跃星辰大数据基础架构研发一面
阶跃星辰大数据基础架构研发一面系统组 1.自我介绍 2.实习拷打 3.项目拷打 4.spark任务提交过程 5.sparkrdd运行过程shuffle阶段拆分 6.hdfs上文件存储方式 7.hdfs写数据流程 8.算法:判断链表是否有环 9.反问 23大概40min 4567 10min 8 5min
-
从数据帧开始向pandas数据帧结束添加值[重复]
我有一个pandas数据帧,如下所示: 我希望将第0行添加到数据帧的末尾,并获得如下所示的新数据帧: 我在熊猫身上能做什么来做到这一点?
-
计算表中BLOB列的总数据大小
问题内容: 我的表中的一列中包含大量BLOB数据。我正在编写一个实用程序以将数据转储到文件系统。但是在转储之前,我需要检查磁盘上是否有必要的空间来导出整个表中的所有Blob字段。 请提出一种有效的方法来获取表中所有Blob字段的大小。 问题答案: 您可以使用MySQL函数。有关更多详细信息,请参见此处。
-
Python=-使用pandas的“大数据”工作流程
问题内容: 在学习pandas的过程中,我试图迷惑了这个问题很多月。我在日常工作中使用SAS,这非常有用,因为它提供了核心支持。但是,由于许多其他原因,SAS作为一个软件还是很糟糕的。 有一天,我希望用python和pandas取代我对SAS的使用,但是我目前缺少大型数据集的核心工作流程。我并不是说需要分布式网络的“大数据”,而是文件太大而无法容纳在内存中,但文件又足够小而无法容纳在硬盘上。 我的
-
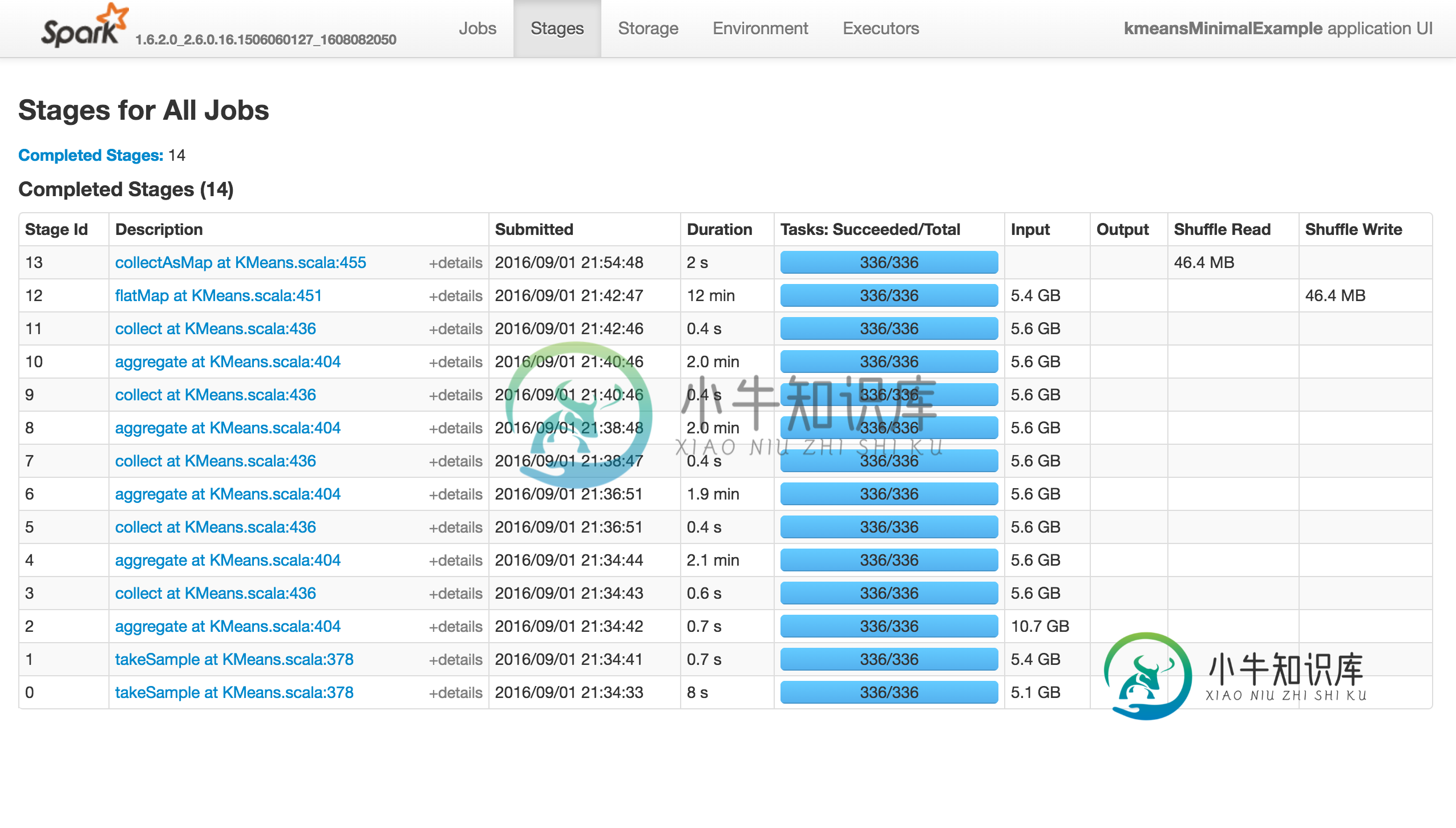 Spark的KMeans是否无法处理大数据?
Spark的KMeans是否无法处理大数据?问题内容: KMeans有几个用于训练的参数,初始化模式默认为kmeans ||。问题在于它快速前进(不到10分钟)到前13个阶段,但随后 完全挂起 ,而不会产生错误! *重现问题的 *最小示例 (如果我使用1000点或随机初始化,它将成功): 如下所示,该作业不执行任何操作(该操作不会成功,失败或没有进展。)。“执行器”选项卡中没有活动/失败的任务。Stdout和Stderr Logs没有特别有
-
如何获取MySQL数据库表的大小?
问题内容: 我可以运行此查询来获取MySQL数据库中所有表的大小: 我希望对了解结果有所帮助。我正在寻找尺寸最大的桌子。 我应该看哪一列? 问题答案: 您可以使用此查询显示表的大小(尽管您需要先替换变量): 或此查询以列出每个数据库中每个表的大小,从大到大: