
Spark的KMeans是否无法处理大数据?

KMeans有几个用于训练的参数,初始化模式默认为kmeans
||。问题在于它快速前进(不到10分钟)到前13个阶段,但随后 完全挂起 ,而不会产生错误!
*重现问题的 *最小示例 (如果我使用1000点或随机初始化,它将成功):
from pyspark.context import SparkContext
from pyspark.mllib.clustering import KMeans
from pyspark.mllib.random import RandomRDDs
if __name__ == "__main__":
sc = SparkContext(appName='kmeansMinimalExample')
# same with 10000 points
data = RandomRDDs.uniformVectorRDD(sc, 10000000, 64)
C = KMeans.train(data, 8192, maxIterations=10)
sc.stop()
如下所示,该作业不执行任何操作(该操作不会成功,失败或没有进展。)。“执行器”选项卡中没有活动/失败的任务。Stdout和Stderr
Logs没有特别有趣的东西:
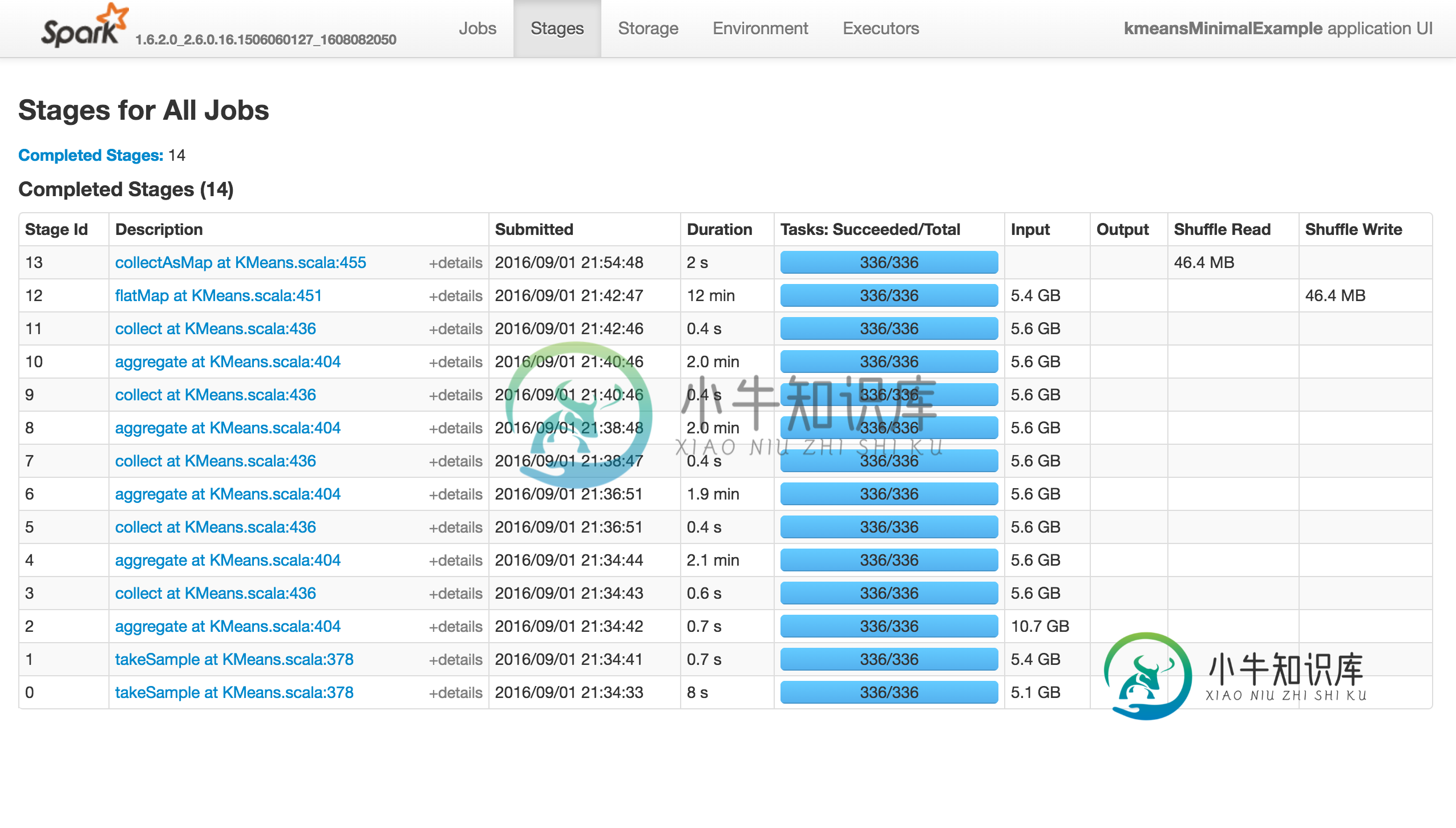
如果使用k=81而不是8192,它将成功:
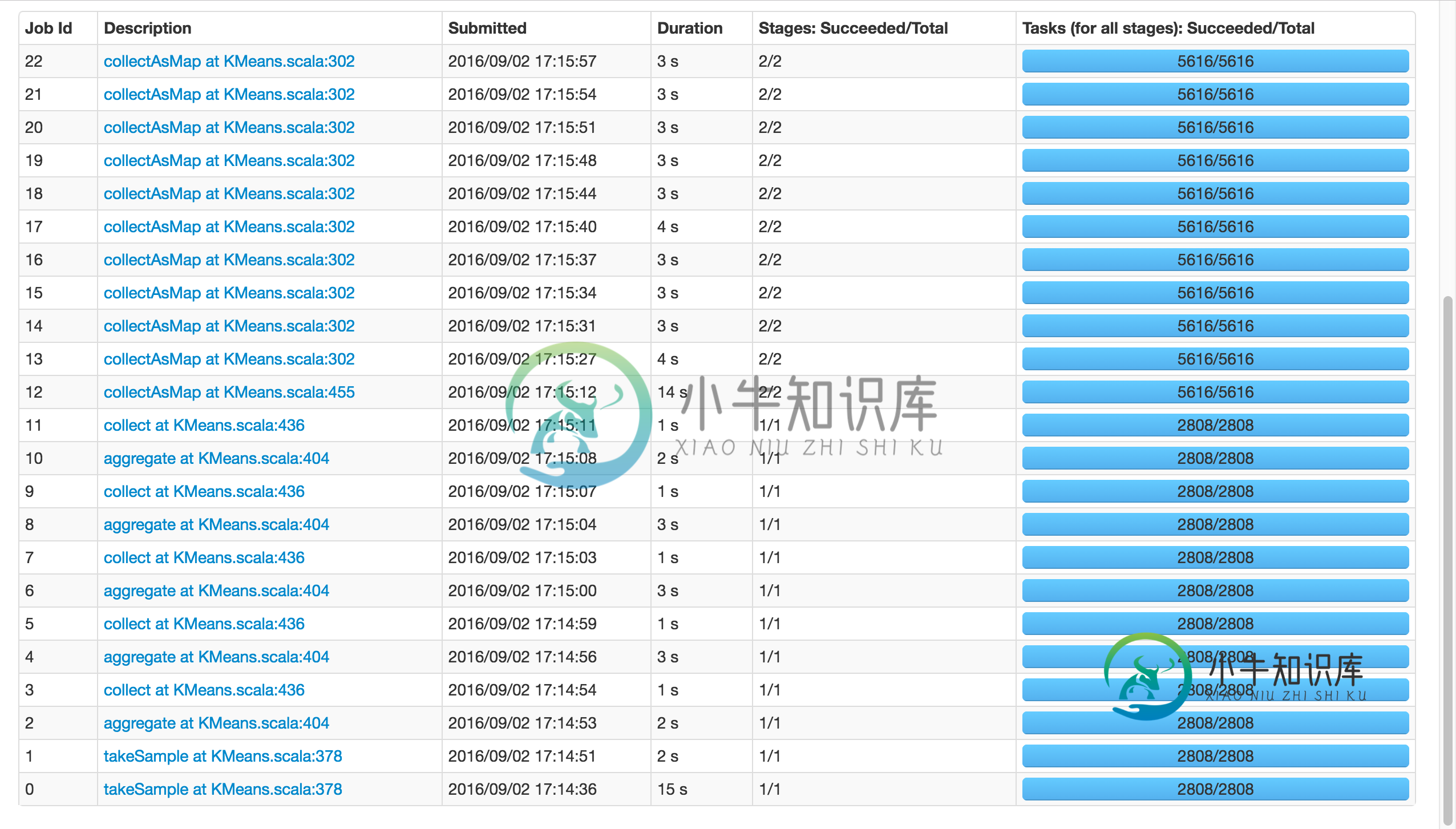
请注意,这两个电话takeSample(),不应该是一个问题,因为有在随机初始化的情况下打了两次电话。
那么,发生了什么事?Spark的Kmeans是否 无法扩展 ?有人知道吗 你能繁殖吗?
如果是内存问题,我将像以前一样收到警告和错误。
注意:placeybordeaux的注释基于作业在 客户端模式下 的执行,在该 模式下
,驱动程序的配置无效,从而导致退出代码143等(请参阅编辑历史记录),而在群集模式下则 没有任何错误报告 ,该应用程序 只是挂起 。
从zero323开始:为什么Spark MllibKMeans算法非常慢?是相关的,但我认为他见证了一些进展,而我的绞刑期间,我确实发表了评论…

问题答案:
我认为“悬空”是因为您的执行者不断死亡。正如我在边聊中提到的那样,此代码在本地和群集中的Pyspark和Scala中对我来说运行良好。但是,它花费的时间比应该花费的时间长得多。几乎所有时间都花在k均值上||
初始化。
我打开了https://issues.apache.org/jira/browse/SPARK-17389,以跟踪两项主要改进,您可以立即使用其中一项。编辑:真的,另请参阅https://issues.apache.org/jira/browse/SPARK-11560
首先,有一些代码优化可以将初始化速度提高约13%。
但是,最大的问题是它默认为5步k-均值||。init,似乎2几乎总是一样好。您可以将初始化步骤设置为2,以查看加速情况,尤其是在目前处于挂起状态的阶段。
在我的笔记本电脑上(较小)测试中,初始化时间从5:54变为1:41,并且两者都有变化,这主要是由于设置了初始化步骤。
-
我试图使用Apache Spark来处理我的大型(230K条目)cassandra数据集,但我经常遇到不同类型的错误。然而,我可以成功地运行应用程序时,运行在一个数据集约200个条目。我有一个由3个节点和1个主节点和2个工作节点组成的spark设置,这两个工作节点还安装了一个cassandra集群,该集群的数据索引复制系数为2。我的两个spark workers在web界面上显示2.4和2.8GB
-
本文向大家介绍kmeans算法原理?相关面试题,主要包含被问及kmeans算法原理?时的应答技巧和注意事项,需要的朋友参考一下 随机初始化中心点范围,计算各个类别的平均值得到新的中心点。 重新计算各个点到中心值的距离划分,再次计算平均值得到新的中心点,直至各个类别数据平均值无变化。
-
如果我只有一个内存为25 GB的执行器,并且如果它一次只能运行一个任务,那么是否可以处理(转换和操作)1 TB的数据?如果可以,那么将如何读取它以及中间数据将存储在哪里? 同样对于相同的场景,如果hadoop文件有300个输入拆分,那么RDD中会有300个分区,那么在这种情况下这些分区会在哪里?它会只保留在hadoop磁盘上并且我的单个任务会运行300次吗?
-
好吧,我对使用Scala/Spark还比较陌生,我想知道是否有一种设计模式可以在流媒体应用程序中使用大量数据帧(几个100k)? 在我的示例中,我有一个SparkStreaming应用程序,其消息负载类似于: 因此,当用户id为123的消息传入时,我需要使用特定于相关用户的SparkSQL拉入一些外部数据,并将其本地缓存,然后执行一些额外的计算,然后将新数据持久保存到数据库中。然后对流外传入的每条
-
我有一个问题,在elasticsearch与mongob建立河流。如果日期的大小在一百万以内,我可以从mongob导入数据。但是当数据很大1000万或更大时,河流无法索引来自mongob集合的所有记录。 我在日志中看到这个错误 通常说river stale是错误的几次。此外,我在mongodb设置中的oplog大小为1024MB。
-
本文向大家介绍python处理大数字的方法,包括了python处理大数字的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python处理大数字的方法。分享给大家供大家参考。具体实现方法如下: 运行结果如下: 希望本文所述对大家的Python程序设计有所帮助。