《数据分析》专题
-
 d3中高效的数据存储、分区和选择
d3中高效的数据存储、分区和选择我很难看到一些潜在的大规模重构的全局。我正在寻找一种同时解决两个问题的解决方案(如果存在的话)。我已经很长时间没有用d3编码了,一开始也不太流利。 所有数据都存在于一个数组中,该数组的维数为n,或2 x。。。(链长度随着每次鼠标单击而增加)。 现在我想显示一个老化,每个链的长度都是一样的。对于左边的图,老化将以不同的颜色(例如橙色和红色)显示每个链的第一个点。实际上,已经存在的第一个点将被不同地着
-
实时数据:候选分辨率将很快更改
在同样的情况下,当我调用LiveData对象的方法时,Android studio会显示警告消息 候选解析将很快更改,请使用完全限定名显式调用以下更接近的候选: 公共开放乐趣观察(所有者:LifecycleOwner,观察者:observer 据我所知,这是在更新kotlin 1.4之后发生的,这到底是什么意思?
-
MongoDB根据_id统计每分钟的新文档数
我想统计一下每分钟存储的新文档数量。 由于带有标准ObjectID的_id字段已经包含文档创建的时间戳,我认为应该可以以某种方式使用它。 在Stackoverflow上,我发现了以下映射缩减代码,以便在创建数据有专用字段时完成它 地图-减少每分钟的文档数MongoDB 根据Mongo DB文档(http://docs.mongodb.org/manual/reference/object-id/)
-
Flink监控:捕获统计数据5分钟以上
我是Flink社区的新成员,我正在尝试进行一项实验研究,以捕获Flink在流数据方面的性能。为此,我试图收集几个小时内运行作业的统计数据。然而,使用Flink的UI,我只能看到过去5分钟的统计数据。我尝试访问Rest API,但它不包含除读/写字节以外的统计数据。 UI中任务度量下提供的度量非常有用,但不会超过5分钟。是否有一种方法可以捕获度量的整个历史记录。
-
使用多部分/表单数据吞噬 PSR7 请求
我在Lumen(应用程序A)中创建了一个简单的API,它: 接收PSR-7请求接口 替换对应用程序B的请求的URI 并通过古斯发送请求。 上面的代码将数据传递给应用程序B以获取查询参数、x-www-form-urlencoded或JSON内容类型。但是,它无法传递多部分/form-data。(该文件在应用程序A中可用:
-
可分页+@query+JOIN(fetch?)在Spring数据不起作用
我试图通过使用Spring Data中的注释,将排序与集成在联接字段上。 有人建议将添加到参数中,以便在某种程度上与分页(spring data jpa@query和pagable)相对应 我已经学习了Baeldung的教程,但这不包括联接 Spring-Data FETCH JOIN与分页不起作用也建议使用,但我更喜欢使用,而不是. 我将在下面留下一些代码示例。如果我遗漏了一些重要的东西,请随时
-
Spring批处理中的数据中间作业分区
第1步--第一步从数据库中读取某些事务,并生成一个记录ID列表,这些记录ID将通过jobContext属性发送到第2步。 步骤2-这应该是一个分区步骤:从步骤应该基于从步骤1获得的列表进行分区(每个线程从列表中获得不同的Id),并在不相互干扰的情况下执行它们的读/处理/写操作。 我的问题是,尽管我希望根据步骤1产生的列表对数据进行分区,但spring在步骤1开始之前就配置了步骤2(因此调用了分区器
-
Pyspark拆分字符串类型的火花数据框
我正在使用spark(批处理,而不是流)从kafka topic中读取数据来创建spark dataframe。我想使用spark将这个数据帧加载到cassandra。Dataframe是字符串格式,如下所示。 root |-value:string(nullable = true) 我尝试使用','分隔符拆分数据帧记录,并形成新的数据帧,我可以将其数据到cassandra。 创建了如下的火花DF
-
根据日期和值聚合行,并添加分数
我目前有以下数据帧; 我要做的是创建一个如下所示的dataframe; 其中,每当“感情”列中的值为“正”时,就会添加1,每当它为负时,就会从新创建的sentiment_score列中扣除1。最后,数据帧将被聚合成每个日期的股票及其相应的情绪得分。 然而,我的问题是我知道如何在Excel中这样做,但我刚刚开始使用Python,因此对如何在Excel中这样做几乎一无所知。 任何帮助都将非常感谢!
-
django中业务逻辑和数据访问的分离
null 我的数据库的实体,持久性级别:我的应用程序保留哪些数据? 我的应用程序的实体,业务逻辑级别:我的应用程序做什么? 在Django有哪些实施这种办法的良好做法?
-
href link检索未分页的json-spring数据rest jpa
我已经开始使用Spring开发REST API。我使用的教程项目gs-访问-数据-Rest-初始,这是很容易通过Spring工具套件加载,为了让一些东西尽快工作。 我使用PagingAndSortingRepository公开了两个相关的实体(aplicacion和registros_app),并用@RepositoryRestResource对它们进行了注释,这使我能够正确地公开实体。当我查询a
-
使用Java8个流将数据分组到地图中
我想使用Java8 streams API对数据进行分组。所有具有父_id的行都应分组在一起。下面是示例文本文件。结果应该是一个映射,其中id是一个整数,值是各自分组的行。例如,在下面的例子中,结果将是一个包含3个条目的映射。键1对应2个值,键2对应无值,键3对应1个值。 代码片段是: 输出可以是:。 简单的规则是:如果父母ID不是空的,这些记录应该被分组到一个列表中。这个列表将被视为map中的值
-
压缩和分解Spark SQL数据帧中的多列
我有以下结构的数据帧: 我想写一个UDF,那个 < li >压缩DF中每列第I个位置的元素 < li >分解每个压缩元组的DF 生成的列应如下所示: 目前,我正在对UDF使用多调用(每个列名一个,在运行时之前收集列名列表),如下所示: 由于dataframe可能有数百列,因此这种对< code>withColumn的迭代调用似乎需要很长时间。 问题:这是否可能与一个UDF和一个<code>DF.w
-
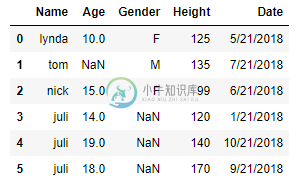 Pandas:基于列中的空值拆分数据帧[duplicate]
Pandas:基于列中的空值拆分数据帧[duplicate]我有一个数据帧如下所示: 如何根据性别的np值转换dataframe? 我想要原始数据帧df被拆分为df1(姓名,年龄,性别,高度,日期),它将具有性别的值(df的前3行)
-
使用pandas以.txt格式保存拆分数据集
尝试将数据集吐槽到和,然后需要将其保存为格式。 这是到目前为止的代码,