《数据分析》专题
-
数据表 - 查询数据项
{% tabs first=”SDK 1.1.0 及以上版本”, second=”SDK 1.1.0 以下版本” %} {% content “first” %} SDK 1.1.0 及以上版本 操作步骤 1.通过 tableID 实例化一个 TableObject 对象,操作该对象即相当于操作对应的数据表 let MyTableObject = new wx.BaaS.TableObject(t
-
数据表 - 获取数据项
{% tabs first=”SDK 1.1.0 及以上版本”, second=”SDK 1.1.0 以下版本” %} {% content “first” %} SDK 1.1.0 及以上版本 操作步骤 1.通过 tableID 实例化一个 TableObject 对象,操作该对象即相当于操作对应的数据表 let MyTableObject = new wx.BaaS.TableObject(t
-
数据表 - 删除数据项
{% tabs first=”SDK 1.1.0 及以上版本”, second=”SDK 1.1.0 以下版本” %} {% content “first” %} SDK 1.1.0 及以上版本 操作步骤 1.通过 tableID 实例化一个 TableObject 对象,操作该对象即相当于操作对应的数据表 let MyTableObject = new wx.BaaS.TableObject(t
-
数据表 - 更新数据项
{% tabs first=”SDK 1.1.0 及以上版本”, second=”SDK 1.1.0 以下版本” %} {% content “first” %} SDK 1.1.0 及以上版本 操作步骤 1.通过 tableID 实例化一个 TableObject 对象,操作该对象即相当于操作对应的数据表 let MyTableObject = new wx.BaaS.TableObject(t
-
数据表 - 新增数据项
{% tabs first=”SDK 1.1.0 及以上版本”, second=”SDK 1.1.0 以下版本” %} {% content “first” %} SDK 1.1.0 及以上版本 操作步骤 1.通过 tableID 实例化一个 TableObject 对象,操作该对象即相当于操作对应的数据表 let MyTableObject = new wx.BaaS.TableObject(t
-
使用数据库元数据
SQLAlchemy 1.4 / 2.0 Tutorial 此页是 SQLAlchemy 1.4/2.0教程 . 上一页: 处理事务和DBAPI |下一步: |next| 使用数据库元数据 随着引擎和SQL执行的停止,我们准备开始一些炼金术。SQLAlchemy Core和ORM的核心元素是SQL表达式语言,它允许流畅、可组合地构造SQL查询。这些查询的基础是表示数据库概念(如表和列)的Pytho
-
JS实现table表格数据排序功能(可支持动态数据+分页效果)
本文向大家介绍JS实现table表格数据排序功能(可支持动态数据+分页效果),包括了JS实现table表格数据排序功能(可支持动态数据+分页效果)的使用技巧和注意事项,需要的朋友参考一下 asp.net会经常遇到分页的效果,尤其是希望实现静态的html分页排序(html分页相信大家都已经有自己的解决方案.在这里就不多说).我写了一个简单的Demo排序. 数据就是字母和数字两组.(汉字需要找到asc
-
如何将一个多索引数据集与另一个多索引数据集分割
最初,我认为将一个多索引对象传递给。loc可以提取出我想要的值/级别,但这是行不通的。做这样的事情最好的方法是什么?
-
Hadoop 如何在多个数据节点之间分发数据和映射减少任务
我是hadoop的新手,我阅读了许多hadoop mapreduce和hdfs的页面,但仍然无法明确一个概念。 也许这个问题是愚蠢的或不寻常的,如果真是如此的话。我的问题是,假设我在hadoop中为一个大小为1GB的文件创建了一个单词计数程序,其中map函数将把每一行作为输入,输出作为键值对,reduce函数将输入作为键值,并简单地迭代列表,计算单词进入该文件的总次数。 现在我的问题是,因为这个文
-
python实现的分析并统计nginx日志数据功能示例
本文向大家介绍python实现的分析并统计nginx日志数据功能示例,包括了python实现的分析并统计nginx日志数据功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现的分析并统计nginx日志数据功能。分享给大家供大家参考,具体如下: 利用python脚本分析nginx日志内容,默认统计ip、访问url、状态,可以通过修改脚本统计分析其他字段。 一、脚本运行方式
-
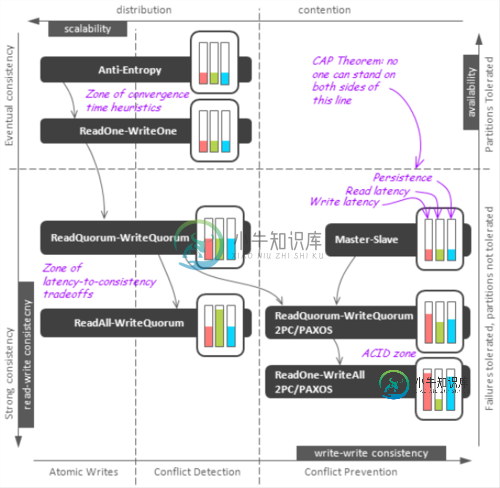 深入解析NoSQL数据库的分布式算法(图文详解)
深入解析NoSQL数据库的分布式算法(图文详解)本文向大家介绍深入解析NoSQL数据库的分布式算法(图文详解),包括了深入解析NoSQL数据库的分布式算法(图文详解)的使用技巧和注意事项,需要的朋友参考一下 尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践。在这篇文章里,我将针对NoSQL数据库的分布式特点进行一些系统化的描述。 系统的可扩展性是推动NoSQL运动发展的的主要
-
IC角色,用于创建物理表,分析SAP HANA中的数据
本文向大家介绍IC角色,用于创建物理表,分析SAP HANA中的数据,包括了IC角色,用于创建物理表,分析SAP HANA中的数据的使用技巧和注意事项,需要的朋友参考一下 要创建物理表,需要上传数据并创建信息视图IC_MODELER角色。如果仅为这些用户分配IC_PUBLIC角色,则他们可以查看其他用户创建的信息视图,但不能创建自己的视图。
-
将聚类分析结果转换为数据。R中的帧格式
这篇文章来自于这个主题,使用R对单词中的相同模式进行分类。解决方案很好,但是我需要数据帧格式。数据是相同的 我们来进行聚类分析 代码完成后,如何将结果转换为data.frame? 预期产出 s=as。数据(函数(…,row.names=NULL,check.rows=FALSE,check.names=TRUE)中的frame(拆分(文本,集群))错误:参数表示行数不同:7,1,2 所以理想的输出
-
用Java进化生物学库(JEBL)分析数据注释树节点
我使用JEBL和跌跌撞撞的API,因为我找不到非常清晰的留档或示例。 我想做的是在一棵树上阅读,树上的树枝标注了长度,节点也标注了长度。然后,我应该能够获取树叶并向上遍历树,同时检查节点的注释(使用JEBL遍历很容易,我的问题实际上是注释)。 它们是系统发育树,其中每个节点都是一个物种,注释将标记特定节点上是否存在某些基因,并且可能有足够少的基因,一个字符串就足够了(例如,如果有三个基因a、B和C
-
 上海银行-数据分析与应用工程师一面面经
上海银行-数据分析与应用工程师一面面经关于数分的面经好像很少,发一下积攒一下人品,面完的友友可以互通一下有无呀,许愿能有二面~ 时间点:9.21投递,9.29收到笔试,9.30笔试,晚上收到约10.5面试的邮件(上银前面好像比较快,会在一个星期左右发笔试,要是还没收到估计是凉了) 楼主是搞深度学习的,对数分可能不太熟悉,面前一直准备复习SQL,之前一直找的算法岗,一直没怎么问过数据结构,所以回答的不是很好,害 腾讯会议的形式,一共五个