
d3中高效的数据存储、分区和选择

我很难看到一些潜在的大规模重构的全局。我正在寻找一种同时解决两个问题的解决方案(如果存在的话)。我已经很长时间没有用d3编码了,一开始也不太流利。
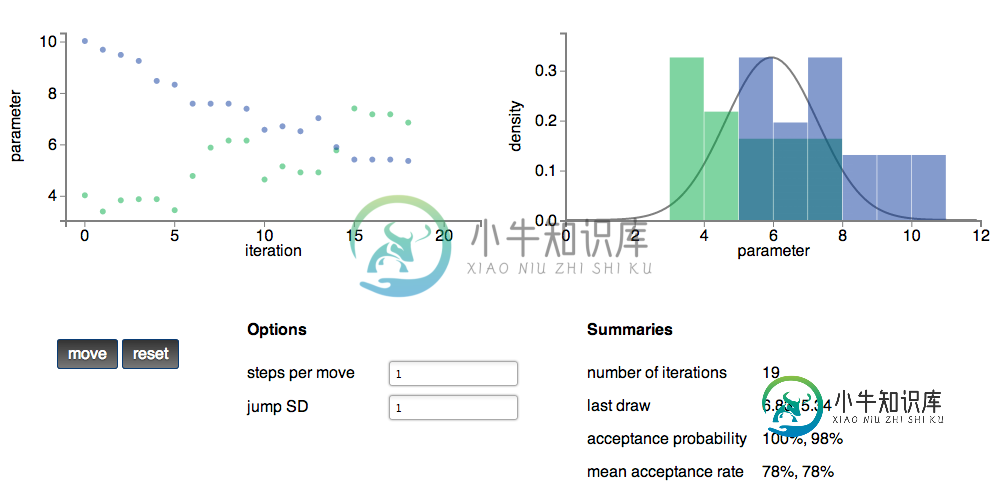
所有数据都存在于一个数组中,该数组的维数为n,或2 x。。。(链长度随着每次鼠标单击而增加)。
现在我想显示一个老化,每个链的长度都是一样的。对于左边的图,老化将以不同的颜色(例如橙色和红色)显示每个链的第一个biLlong点。实际上,已经存在的第一个biLlong点将被不同地着色。在右边的直方图中,我希望这些点有自己对应的条。
我是否应该创建一个单独的数组来保存老化,在每个绘图上有效地绘制两个数据容器?(有没有这样的例子?)或者,是否有某种方法可以将数据保存在θ中,但处理子组件的方式不同?(例如?)
下面是一些示例代码,展示我当前如何绘制θ:
// Left plot update
function movePoints ()
{
var tmp = chart.selectAll(".vis1points").data(thetas[0], function (d, i) { return i; } );
tmp
.enter().insert("svg:circle")
.attr("class", "vis1points")
.attr("cx", function (d, i) { return xx(i); })
.attr("cy", yy)
.attr("r", 3)
tmp.transition()
.duration(10)
.attr("cx", function (d, i) { return xx(i); })
.attr("cy", yy)
tmp.exit()
.transition().duration(10).attr("r",0).remove();
if ( nChains == 2 ) {
var tmp2 = chart.selectAll(".vis1points2").data(thetas[1], function (d, i) { return i; } );
tmp2
.enter().insert("svg:circle")
.attr("class", "vis1points2")
.attr("cx", function (d, i) { return xx(i); })
.attr("cy", yy)
.attr("r", 3)
tmp2.transition()
.duration(10)
.attr("cx", function (d, i) { return xx(i); })
.attr("cy", yy)
tmp2.exit()
.transition().duration(10).attr("r",0).remove();
}
};
轴当前以θ作为输入,以推断范围和域限制。
对于右侧的直方图:
// Creation involves...
var dataLength = thetas[0].length;
this.histBars = this.vis.selectAll("rect.vis2bars")
.data(that.histVals.counts[0])
.enter().append("svg:rect")
.attr("class", "vis2bars")
.attr("x", function (d, i) { return that.xx2(i); })
.attr("y", function (d, i) { return that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[0])/dataLength)); })
.attr("height",function (d, i) { return that.yy2(0)-that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[0])/dataLength)); })
.attr("width", Math.floor(innerWidth2/numBins));
this.histBars.transition()
.attr("y", function (d, i) { return that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[0])/dataLength)); })
.attr("height",function (d, i) { return that.yy2(0)-that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[0])/dataLength)); })
.duration(dur);
以及更新:
this.update = function( dur2 ) {
var dataLength = thetas[0].length;
var tmp2 = this.histBars.data(this.histVals.counts[0]);
var tmp3;
if ( nChains > 1 ) { // fix
tmp3 = this.histBars2.data(this.histVals.counts[1]);
}
var that = this;
tmp2
.transition()
.delay( 0 ) // could tweak...
.duration(dur2 - 10)
.attr("y", function (d, i) { return that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[0])/dataLength)); })
.attr("height",function (d, i) { return that.yy2(0)-that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[0])/dataLength)); });
// Add update for second data set
if ( nChains > 1 ) {
tmp3
.transition()
.attr("y", function (d, i) { return that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[1])/dataLength)); })
.attr("height",function (d, i) { return that.yy2(0)-that.yy2(that.maxDensity*(d/dataLength)/(d3.max(that.histVals.counts[1])/dataLength)); });
}
共有1个答案

更新圆时,可以动态更改圆的颜色,例如在此处:
tmp.transition()
.duration(10)
.attr("cx", function (d, i) { return xx(i); })
.attr("cy", yy)
.attr("fill", function(d) {
if (d.isBiLengthPoint) {
return "orange";
} else {
return "blue";
}
});
我假设目前您正在根据CSS为圆圈着色,但对于您想要的效果,我真的认为动态加载它们是一个更好的解决方案。
或者,您可以动态更改圆的类,并有两个CSS类声明
tmp.transition()
.attr("class", function(d) {
if (d.isBiLengthPoint) {
return "vis1points-bilength";
} else {
return "vis1points";
}
})
.duration(10)
.attr("cx", function (d, i) { return xx(i); })
.attr("cy", yy)
在你的CSS中
vis1points {
fill: blue;
}
vis1points-bilength {
fill: orange;
}
-
我正在使用Facenet算法进行人脸识别。我想基于此创建应用程序,但问题是Facenet算法返回一个长度为128的数组,即每个人的人脸嵌入。 对于人物识别,我必须找到两个人面部嵌入之间的欧几里得差异,然后检查它是否大于阈值。如果是,那么这些人是相同的;如果它小于,那么这些人是不同的。 比方说,如果我必须在10k人的数据库中找到人x。我必须计算每个人嵌入的差异,这是没有效率的。 有没有办法有效地存储
-
我需要你的一些建议。我试图用redis和哈希(redis类型)存储一些非常有效的内存数据。有一些随机字符串列表(在rfc中平均大小是40个字符,但最大可能是255个字符)--它是文件id,例如我们有100kk的file_id列表。我们还需要每个ID的轨道2参数:download_count(int,incremented)和server_id--tiny int,redis config添加了:
-
我正在设计一个新的数据环境,目前正在开发我的概念证明。在这里,我使用以下架构:Azure函数- 我目前正在努力解决的是如何优化“数据检索”的想法,以便在Azure Databricks上支持我的ETL过程。 我正在处理事务性工厂数据,这些数据通过前面的通道按分钟提交给Azure blob存储。因此,我每天都有86000个文件需要处理。事实上,这需要处理大量的独立文件。目前,我使用下面这段代码来构建
-
你会选择以下两个选项中的哪一个?为什么? 备选方案1: 备选方案2: 您不知道经理存储每个客户以前的所有用户名和密码是否重要。您只知道每个客户可以随时更改他的密码和他的昵称。不管安全方面,您会遵循哪种方法?
-
问题内容: 我目前有一个电子表格类型程序,该程序将其数据保存在HashMaps的ArrayList中。当我告诉您这还不理想时,您无疑会感到震惊。开销似乎使用的内存比数据本身多5倍。 这个问题询问有效的馆藏库,答案是使用Google馆藏。 我的跟进是“ 哪一部分? ” 。我一直在阅读文档,但感觉不像是哪种类最适合。(我也向其他图书馆或建议开放)。 因此,我正在寻找可以使我以最小的内存开销存储密集电子
-
我有两列,一列名为“日期”,另一列名为“时间”。Date是日期数据类型,“time”是字符数据类型。我正在使用以下查询来选择一个新的组合时间戳列 SQL状态:0A000 如何选择包含EST5EDT时区信息的时间戳列?