《数据分析》专题
-
9.2. 分析和解读数据
分析和解读数据 错误检查 试验开始之后的短时间内(几个小时或者1天),我们应该通过实时观察「试验概况」与「指标详情」页面,来检查试验数据是否表现正常,也就是检查是否有程序错误。如果包括原始版本在内的任一版本没有数据显示或者和正常数据相比有很大的、异常的差异,说明试验可能在集成环节出现问题,或者存在程序错误。这时需要停止试验,重新检查调试。 置信区间的解读 若短时间内的数据正常,试验应继续运行至预定
-
 蔚来数据分析 一面
蔚来数据分析 一面自我介绍 最满意的实习项目经历,展开说做了什么 异动分析 拆解场景,考虑哪些数据指标,答得不好 两个sql代码题,一个sql开放题说思路 最后问了会不会python ,那些库,了解埋点吗 问题20分钟,代码三十分钟。 #数据分析求职# #技术面经#
-
 浪潮数据分析一面
浪潮数据分析一面软开笔试+测评 问了下实习经历 python中的函数,python开发会不会,sql,索引,优化
-
 蔚来数据分析面经
蔚来数据分析面经体验很差,这辈子不会再去蔚来了 🕒 岗位/面试时间 数据分析实习生 👥 面试题目(20min) 1.自我介绍 2.可视化项目展示 3.一些normal无意义的问题 4.给我介绍岗位问我是否合适 5.反问(5min)有被侮辱! 🤔 面试感受 从来没有这么差过,面试官没开摄像头,整个过程每次我说完十几秒后才回复我几个字,然后问一句新的问题,感觉自己像个小丑。 反问环节我问她对我这次简历和面试有什
-
 5.30阿里云数据分析
5.30阿里云数据分析淑淑淑芬芬芬数分俺不活咧 早上电话通知面试时间,下午就面 自我介绍 实习的是啥公司,主要做了什么 介绍项目内容 指标分析思路 异常指标怎么处理,如何归因 异常指标影响因素怎么计算 遇到什么特殊数据情况、原因是什么、如何解决 618期间做了什么数据运营工作、紧急情况下做了什么 是否用SQL、一般用sql做什么 云计算项目内容(项目只是用了隐私保护相关的云计算的场景,没有实现,感觉没啥用,食之无味弃之
-
 博西家电 数据分析
博西家电 数据分析#我的实习求职记录# #面试# 5-24上午 博西家电数据分析岗(应该是挂了,唉!) 实习经历介绍深挖 SQL drop和delete区别 (我答的一个删除列一个删除行,但面试官说是一个新建表一个没新建) 辛普森悖论(没答上来,提示了之后总结了一下) 还有几个不记得了 最后是思维题:黑盒拿球问题,烧绳子问题(一根30秒,怎么计算15秒) 反问:工作内容,后续面试流程 面试官问我为什么问第二个问题,
-
 蔚来数据分析一面
蔚来数据分析一面1.数据分析全流程 2.牛顿迭代和梯度下降的原理对比 3.看板指标拆解
-
 东风汽车 数据分析
东风汽车 数据分析三月底一面,一面完一周二面 一面(HR面): 自我介绍 就业规划 有无读博计划 最成功的经历等 聊了十多分钟就结束了 二面(业务面): 自我介绍 pre一个自己做过的数分案例 介绍了一下部门情况,问我最感兴趣的业务方向 为什么想做数分 大概30分钟 二面完两天给了offer,HR直接说是SP offer 还是拒绝了(还是不够多以及base地) 面试体感很好,福利待遇也还可以
-
 【笔试】pdd数据分析0825
【笔试】pdd数据分析0825单选考点主要是概率统计,涉及到离散分布,连续分布,贝叶斯公式,全概率公式等,sql题目总体不难。第一道分组求和,第二道比较两个月的涨幅,第三道主要需要用到窗口函数。#拼多多##数据分析##笔试#
-
SQLite 分离数据库
主要内容:语法,实例SQLite 的 DETACH DATABASE 语句是用来把命名数据库从一个数据库连接分离和游离出来,连接是之前使用 ATTACH 语句附加的。如果同一个数据库文件已经被附加上多个别名,DETACH 命令将只断开给定名称的连接,而其余的仍然有效。您无法分离 main 或 temp 数据库。 如果数据库是在内存中或者是临时数据库,则该数据库将被摧毁,且内容将会丢失。 语法 SQLite 的 DET
-
SQL Server数据分组
SQL Server中分组查询通常用于配合聚合函数,实现分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排序,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。 SQL Server中常用的数据分组相关查询如下: GROUP BY - 根据指定列表达式列表中的值对查询结果进行分组。 HAVING - 指定组或聚合的搜索条件。 GROUPING SETS - 生成多个分组集。 CUB
-
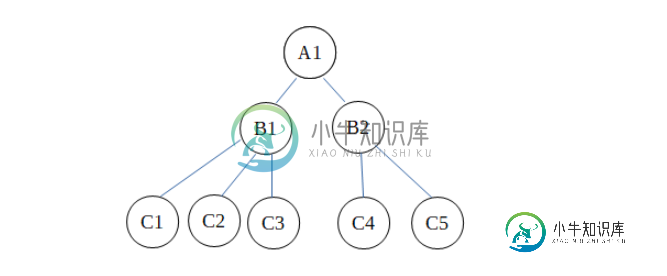 分层数据模型
分层数据模型本文向大家介绍分层数据模型,包括了分层数据模型的使用技巧和注意事项,需要的朋友参考一下 分层数据模型是最早的数据模型之一。该模型是基于文件的模型构建,就像树一样。在此树中,父节点可以与多个子节点关联,但是一个子节点只能有一个父节点。 对于目录和文件,可以说单个目录进一步包含多个文件或目录,然后这些目录包含更多文件,依此类推。 这可以表示为- 示例 使用关系数据库的层次模型的示例如下- <员工> E
-
Django ForeignKey数据分组
Django ForeignKey需要分组 我想列出所有的记者和他们的所有文章显示以下格式。怎么可能呢?
-
Spring数据mongo分页
我想用Spring Data Mongo实现分页。有很多教程和文档建议使用PagingAndSorting Repository,如下所示: 因此,因为PagingAndSorting Repository提供了用于分页查询的api,我可以像这样使用它: 我的问题是这里的findAll方法实际上是在哪里实现的?我需要自己编写它的实现吗?实现StoryRepo的StoryRepoImpl需要实现这个
-
分布式数据库
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19