《数据分析》专题
-
数据分片
定义 Sharding Table Rule SHOW SHARDING TABLE tableRule | RULES [FROM schemaName] SHOW SHARDING ALGORITHMS [FROM schemaName] tableRule: RULE tableName 支持查询所有数据分片规则和指定表查询 支持查询所有分片算法 Sharding Bindin
-
数据分片
定义 Sharding Table Rule CREATE SHARDING TABLE RULE shardingTableRuleDefinition [, shardingTableRuleDefinition] ... ALTER SHARDING TABLE RULE shardingTableRuleDefinition [, shardingTableRuleDefinition]
-
数据分片
背景 传统的将数据集中存储至单一数据节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。 从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。 从可用性的方面来讲,服务化的无状态型,能够达到较小成本的随
-
 数据分析一面
数据分析一面经纬恒润 1.介绍下数学建模竞赛,你做了啥工作 2.介绍下实习项目 3.你mentor对你的评价 4.薪资要求,工作地点 5.sql题
-
1.5.3.2.16 大数据分析
SuperMap iClient for Leaflet 对接了 SuperMap iServer 的分布式分析服务,为用户提供大数据分析功能,主要包括: 密度分析 点聚合分析 单对象空间查询分析 区域汇总分析 矢量裁剪分析
-
WinPcap: 分析数据包
现在,我们可以捕捉并过滤网络流量了,那就让我们学以致用,来做一个简单使用的程序吧。 在本讲中,我们将会利用上一讲的一些代码,来建立一个更实用的程序。 本程序的主要目标是展示如何解析所捕获的数据包的协议首部。这个程序可以称为UDPdump,打印一些网络上传输的UDP数据的信息。 我们选择分析和现实UDP协议而不是TCP等其它协议,是因为它比其它的协议更简单,作为一个入门程序范例,是很不错的选择。让我
-
如何分析数据
当你检查一个商业活动并且发现了把它转换为软件应用程序的需求时,数据分析是软件开发早期的一个过程。这是一个官方的定义,当你,一个程序员,应该集中注意力在写别人设计的东西的代码时,这可能会让你相信数据分析是一种更应该归入系统分析的行为。如果我们严格遵循软件工程范式,这可能是正确的。有经验的程序员会成为设计者,最尖锐的设计者变成商业分析师,因此被冠名去思考所有数据需要,并且给你充分定义的任务去执行。这不
-
数据分析系统
数据概览 1.数据概览 首页>报表>数据 查看时间范围内系统的关键数据指标。包括总会话量、总消息量、平均会话时长、平均响应时长、排队放弃会话量、平均满意度以及会话量、消息量、平均会话时长之间的变化趋势条形图、柱状图和饼状图。 2.客服报表 首页>报表>客服 客服工作量分析:查看人工客服的工作数据。包括接待总数、对话总数、对话总时长、在线总时长以及在线人工利用率。 客服工作效率/质量分析:查看人工客
-
 客尼数据分析
客尼数据分析1.简历 2.标准化和归一化 3.ab test 4.如何与非技术人员进行沟通
-
 招联-数据分析
招联-数据分析1轮面试 5.13下午三点面试 1.自我介绍 2.实习项目深挖,好像也没问很多 (实习的经历和数分并不是很相关,偏算法) 3.比赛项目深挖 数据有哪些特征,用了什么模型,xgboost原理和rf的优缺点 4.反问 总得来说好像并没有问很深很难的的问题 二轮面试 一面面完五分钟内就通知过了 四点半开始(效率感人😂) 1.自我介绍 2.base,投了哪些公司,有什么offer(可能比较关注意向度)
-
 龙湖数科数据分析
龙湖数科数据分析9.16 一面 20min左右 1.自我介绍 2.挖实习,针对部分细节做提问 3.数据分析需要哪些技能 4.反问 9.19 二面 25min 1.自我介绍 2.深挖简历,面试官比较关注项目的产出 3.广告投放的渠道分析(实习中有) 4.是否了解地产数字化 5.反问 问了下后续面试流程,说是至少还有一轮业务面+hr面,如果sp的话还会有总监面 许愿终试 龙湖数科数据分析求抱团 #龙湖集团数字科技##
-
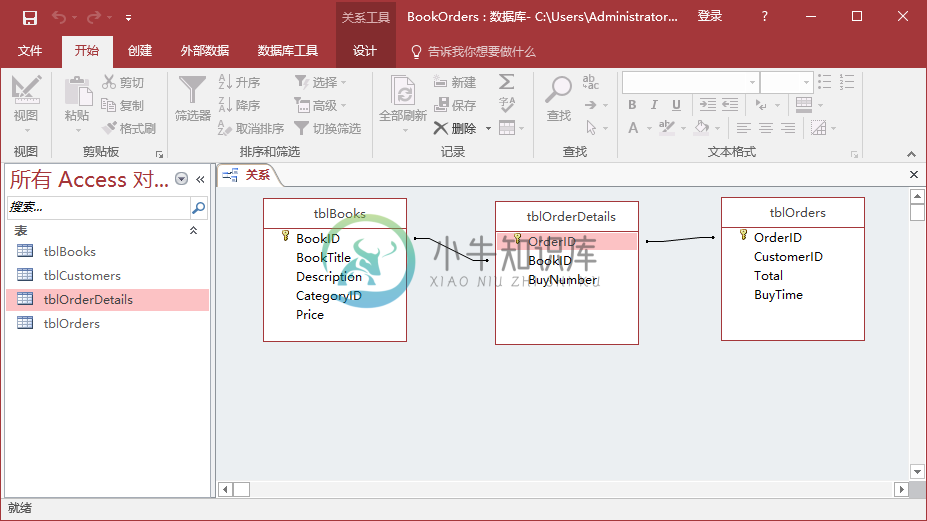 Access分组数据
Access分组数据主要内容:聚合查询,Access中的连接,示例在本章中,我们将介绍Access中如何计算如何分组记录。 我们创建了一个按行计算或按记录计算的字段来创建行总计或小计字段,但是如果想通过分组记录而不是单个记录来计算,那该怎么办呢? 可以通过创建聚合查询来实现这一点。 聚合查询 聚合查询也称为总计或汇总查询是总和,质量或组的详细信息。它可以是总金额或总金额或记录的组或子集。 聚合查询可以执行许多操作。下面是一个简单的表格,列出了分组记录中总的方法。
-
hazelcast数据分布
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
数据集拆分
在机器学习中,通常将所有的数据划分为三份:训练数据集、验证数据集和测试数据集。它们的功能分别为 训练数据集(train dataset):用来构建机器学习模型 验证数据集(validation dataset):辅助构建模型,用于在构建过程中评估模型,为模型提供无偏估计,进而调整模型超参数 测试数据集(test dataset):用来评估训练好的最终模型的性能 不断使用测试集和验证集会使其逐渐失去
-
 vivo数据分析面经
vivo数据分析面经测评 8.25 一面 9.19 进来常规互相自我介绍。然后面试官说,我先问你三个和简历无关的问题,顿时我心凉了半截。第一道SQL,考窗口函数,很简单。第二道考统计,问卡方分布原理,还给两分钟让去查我都没查出来。第三道考概率论,五分钟时间看着你做,彻底凉凉。不过面试小哥哥人很好,全程微笑,看我不会还给我提示,在线给我解题,我只觉得自己很没用很丢人呜呜呜。 然后简历部分就是挑一段印象最深的实习经历展开