《深信服二面》专题
-
web服务器元文件信息发现 (OTG-INFO-003)
综述 这章节描述如何从robots.txt中发现泄露的web应用路径信息。更进一步,这些应该被蜘蛛、机器人和网页抓取软件忽略的目录列表能很好地作为建立应用流程的参考。 测试目标 web应用路径或者文件夹泄露信息。 建立被蜘蛛机器人忽略的目录列表。 如何测试 robots.txt Web蜘蛛、机器人和网页抓取软件通过获取页面,递归遍历超链接来获取更多的网页内容。他们的行为应该遵循在网站根目录下rob
-
微信服务号与订阅号的主要区别
订阅号和服务号都是微信公众号的一种,对于一个普通的微信用户,可能感受的差别只是所有订阅号的消息都收纳在了微信会话列表的【订阅号消息】中,而服务号消息则是一个个服务号出现在了微信会话列表中; 对于企业市场人员,微信服务号与订阅号的主要区别体现在以下几点: 1. 带参数的二维码 微信服务号支持参数二维码,支持在不同的场景下生成微信服务号参数二维码,可以帮助企业识别微信服务号粉丝关注来源。 订阅号不支持
-
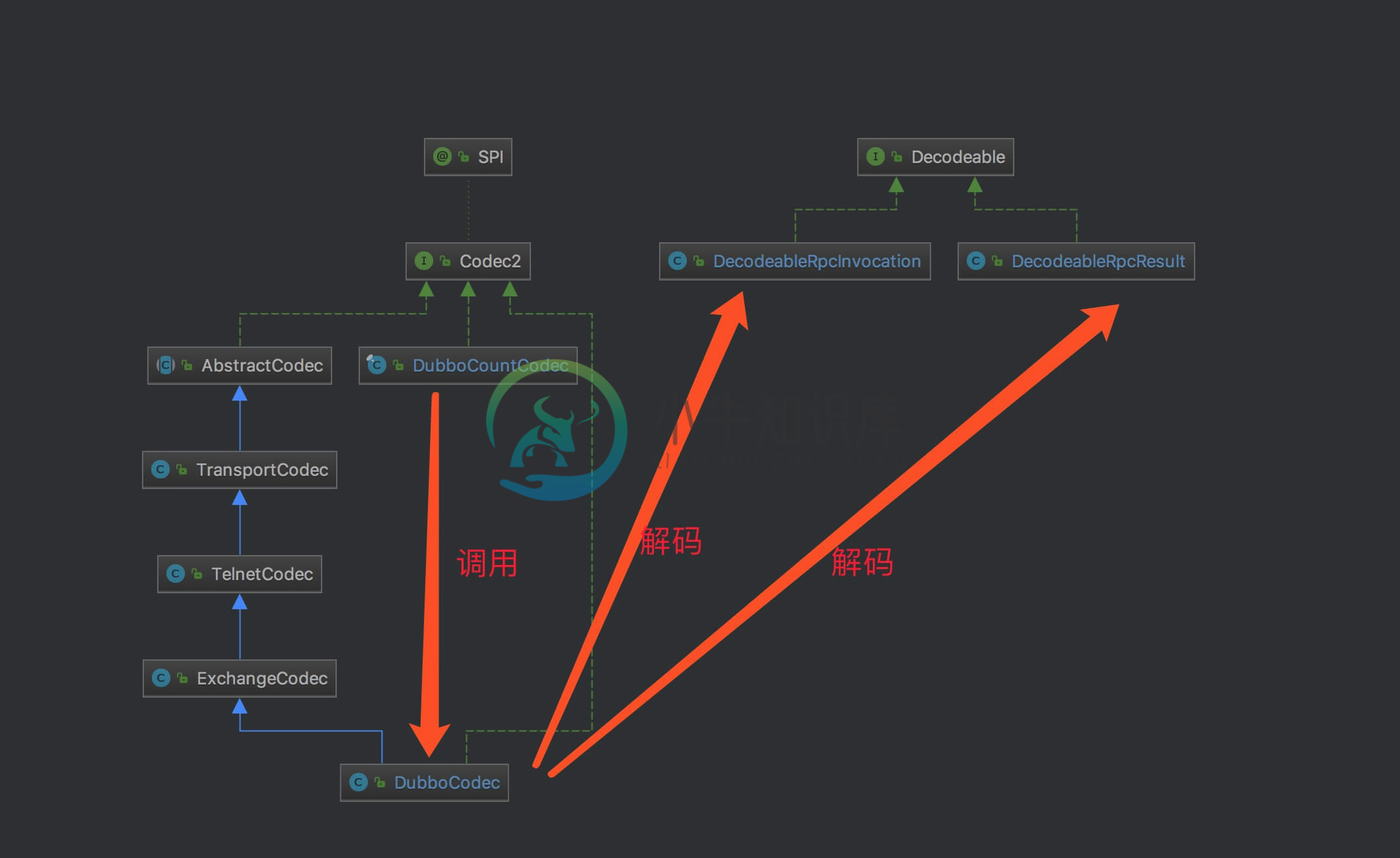 Dubbo 服务调用之远程调用-通信实现
Dubbo 服务调用之远程调用-通信实现主要内容:1.概述,2.ExchangeHandler,3. Codec1.概述 本文涉及类图如下: 2.ExchangeHandler 在 DubboProtocol 中,实现了 ExchangeHandler ,代码如下: 3. Codec 实现 Codec2 接口,支持多消息的编解码器。 3.1 DubboCountCodec 3.2 DubboCodec 实现 Codec2 接口,继承 ExchangeCodec 类,Dubbo 编解码器实现类。 构造方法 3
-
在kubernetes上部署微服务时服务间通信的连接超时问题
我正在做一个演示项目,它有5个微服务-发现服务器,api-gateway,user-order-detail,order和user Service。 我将在GKE上内部公开订单和用户服务 我将对外公开user-order-detail服务,它将使用restendpoint调用其他两个服务 google kubernetes引擎上的服务: user-order-detail LoadBalancer
-
用docker和kubernetes部署的Spring-boot微服务应用程序:服务不通信
我的应用程序服务无法相互通信。我拥有的是一个由身份验证服务、发现服务器、api网关和商家服务组成的应用程序。我使用eureka服务器和客户端依赖关系进行服务发现。每个服务都用docker进行容器化,我使用K8进行编排。 当我向服务器发送请求时,我得到的响应是: 以下是我的尤里卡属性和K8配置文件: 发现服务器文件 身份验证服务application.properties文件 商户服务 API 网关
-
深入了解库
问题内容: 我试图了解如何使用Golang和forks。情况如下,我在写一个依赖于library的库,这不是我的。 由于缺少我需要的一些方法,因此将其分叉到。但是,我不能只是这样做,库引用了自己,所以它坏了。 在本文中,他们提供了可能的解决方案: 现在,这充其量是hacky。从库代码中无法得知依赖项来自其他存储库。任何使用我的图书馆的人都无法使其正常运行。 由于dep有望成为正式的依赖管理器。我发
-
JSON.stringify深层对象
问题内容: 我需要一个从任何参数构建JSON有效字符串的函数,但: 通过不两次添加对象来避免递归问题 通过截断给定深度来避免调用堆栈大小问题 通常,它应该能够处理大对象,但要以截断为代价。 作为参考,此代码失败: 避免递归问题很简单: 但是到目前为止,除了复制和更改Douglas Crockford的代码 以跟踪深度之外,我还没有找到任何方法来避免在诸如或any之类的非常深的对象上发生堆栈溢出。有
-
16 深度遍历
def deep(root): if not root: return print root.data deep(root.left) deep(root.right) if __name__ == '__main__': lookup(tree) deep(tree)
-
1.16 深度学习
现在开始学深度学习。在这部分讲义中,我们要简单介绍神经网络,讨论一下向量化以及利用反向传播(backpropagation)来训练神经网络。 1 神经网络(Neural Networks) 我们将慢慢的从一个小问题开始一步一步的构建一个神经网络。回忆一下本课程最开始的时就见到的那个房价预测问题:给定房屋的面积,我们要预测其价格。 在之前的章节中,我们学到的方法是在数据图像中拟合一条直线。现在咱们不
-
深入理解(function(){... })();
本文向大家介绍深入理解(function(){... })();,包括了深入理解(function(){... })();的使用技巧和注意事项,需要的朋友参考一下 1.他叫做立即运行的匿名函数(也叫立即调用函数) 2.当一个匿名函数被括起来,然后再在后面加一个括号,这个匿名函数就能立即运行起来!有木有很神奇哦~ 3.要使用一个函数,我们就得首先声明它的存在。而我们最常用的方式就是使用functio
-
sass 套料深度
本文向大家介绍sass 套料深度,包括了sass 套料深度的使用技巧和注意事项,需要的朋友参考一下 示例 嵌套是一项非常强大的功能,但应谨慎使用。它可以非常容易和快速地发生,您可以开始嵌套并继续进行嵌套,嵌套或嵌套中的所有子代。让我示范一下: 问题 特异性 在li从上面的例子中有一个margin组。假设我们要稍后在媒体查询中覆盖它。 因此,由于嵌套太深,因此每当要覆盖某个值时,都必须再次嵌套深。更
-
CSRF深度保护
我目前添加了一个CSRF令牌保护机制到我的php应用程序。正如我所读到的,唯一的要求是一个独特的每个用户令牌,我在php7中使用random_bytes生成。 我担心的是,如果攻击者使用用户的浏览器发送http请求,浏览器不会发送令牌的会话变量吗?(因为用户具有与令牌关联的sessionid)。 我将令牌存储在会话变量的一个隐藏值内。 例如:我的令牌存储在会话变量中,然后攻击者将我发送到具有csr
-
sys.getsizeof的深版本
问题内容: 我想计算对象使用的内存。很大,但是很浅(例如,在列表上调用,它不包括列表元素占用的内存)。 我想写一个通用的“深度”版本。我了解“深层”的定义有些含糊;我对后跟的定义感到非常满意。 这是我的第一次尝试: 它存在两个已知问题,并且存在许多未知问题: 我不知道如何以捕获所有链接对象的方式遍历通用容器。因此,我使用进行了迭代,并对字典的大小写进行了硬编码(包括值,而不仅仅是键)。显然,这不适
-
深入了解 Tasks
在这本教程的一开始 (第 6 章, 构建脚本基础) 你已经学习了如何创建简单的任务. 然后你也学习了如何给这些任务加入额外的行为, 以及如何在任务之间建立依赖关系. 这些仅仅是用来构建简单的任务. Gradle 可以创建更为强大复杂的任务. 这些任务可以有它们自己的属性和方法. 这一点正是和 Ant targets 不一样的地方. 这些强大的任务既可以由你自己创建也可以使用 Gradle 内建好的
-
深度学习层
深度学习的总体来讲分三层,输入层,隐藏层和输出层。如下图: 但是中间的隐藏层可以是多层,所以叫深度神经网络,中间的隐藏层可以有多种形式,就构成了各种不同的神经网络模型。这部分主要介绍各种常见的神经网络层。在熟悉这些常见的层后,一个神经网络其实就是各种不同层的组合。后边介绍主要基于keras的文档进行组织介绍。