
web服务器元文件信息发现 (OTG-INFO-003)
综述
这章节描述如何从robots.txt中发现泄露的web应用路径信息。更进一步,这些应该被蜘蛛、机器人和网页抓取软件忽略的目录列表能很好地作为建立应用流程的参考。
测试目标
web应用路径或者文件夹泄露信息。
建立被蜘蛛机器人忽略的目录列表。
如何测试
robots.txt
Web蜘蛛、机器人和网页抓取软件通过获取页面,递归遍历超链接来获取更多的网页内容。他们的行为应该遵循在网站根目录下robots.txt所定义的机器人排除协议[1]。
例如,2013年8月11日获取的 http://www.google.com/robots.txt 的robots.txt文件,该文件开头如下所示:
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
Disallow: /catalogs
...
User-Agent 指令特别指定了特定的蜘蛛机器人。例如,User-Agent: Googlebot 特指那些谷歌的蜘蛛机器人,"User-Agent: bingbot" 特指那些来自Microsoft/Yahoo!的爬虫机器人。在如下所示例子中的 User-Agent: * 则指明包括所有的蜘蛛机器人[2]:
User-agent: *
Disallow 指令规定了蜘蛛机器人限制访问的资源。上面的例子中如下资源被禁止访问:
...
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
Disallow: /catalogs
...
Web蜘蛛机器人可以故意忽略robots.txt中的Disallow指令所规定的内容[3], 比如那些来自Social Networks 的机器人需要确保共享的链接依旧合法。因此,robots.txt不应该当做一个强制约束机制来控制第三方访问这些web页面。
获取根目录下的robots.txt- 使用"wget" 或 "curl"
robots.txt文件能从web服务器根目录下获得。例如使用"wget"或"curl"获取www.google.com的robots.txt文件:
cmlh$ wget http://www.google.com/robots.txt
--2013-08-11 14:40:36-- http://www.google.com/robots.txt
Resolving www.google.com... 74.125.237.17, 74.125.237.18, 74.125.237.19, ...
Connecting to www.google.com|74.125.237.17|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/plain]
Saving to: ‘robots.txt.1’
[ <=> ] 7,074 --.-K/s in 0s
2013-08-11 14:40:37 (59.7 MB/s) - ‘robots.txt’ saved [7074]
cmlh$ head -n5 robots.txt
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
cmlh$
cmlh$ curl -O http://www.google.com/robots.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
101 7074 0 7074 0 0 9410 0 --:--:-- --:--:-- --:--:-- 27312
cmlh$ head -n5 robots.txt
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
cmlh$
获取根目录下的robots.txt- 使用rockspider
"rockspider" 能自动为蜘蛛机器人建立初始的范围和网站的目录。
例如,使用"rockspider"基于allowed:指令建立www.google.com的网站初始目录结构:
cmlh$ ./rockspider.pl -www www.google.com
"Rockspider" Alpha v0.1_2
Copyright 2013 Christian Heinrich
Licensed under the Apache License, Version 2.0
1. Downloading http://www.google.com/robots.txt
2. "robots.txt" saved as "www.google.com-robots.txt"
3. Sending Allow: URIs of www.google.com to web proxy i.e. 127.0.0.1:8080
/catalogs/about sent
/catalogs/p? sent
/news/directory sent
...
4. Done.
cmlh$
使用Google Webmaster 工具分析 robots.txt
网站拥有者们可以使用"Google Webmaster Tools"工具中的"Analyze robots.txt"功能来分析网站结构。这个工具能帮助测试,使用方式如下:
- 使用Google帐号登陆Google Webmaster Tools;
- 在操作面板中输入待分析网站URL;
- 根据指示选择合适的功能。
元标签(META)
标签位于HTML文档的HEAD区域内,应该与网站整体内容保持一致以防蜘蛛机器人从其他地方开始抓取,并非从根页面,例如"deep link"。
如果没有像"<META NAME="ROBOTS" ... >"这样的条目,那么“机器人排除协议”默认为可索引("INDEX,FOLLOW")。因此协议规定的其他另外两个合法的条目以"NO..."开头,例如"NOINDEX" and "NOFOLLOW"。
web蜘蛛机器人也可以故意忽略"<META NAME="ROBOTS"",就像对待robots.txt一样。因此,<META>也不能被当做是一项主要控制措施,最多只是robots.txt的补充措施。
发现<META>标签 - 使用Burp
基于robots.txt定义的Disallow指令目录与使用正则表达式搜索每个页面中的"<META NAME="ROBOTS""相互比较结果。
比如facebook.com下测robots.txt有一条"Disallow: /ac.php" 入口,以及搜索得来的"<META NAME="ROBOTS"" 显示如下:
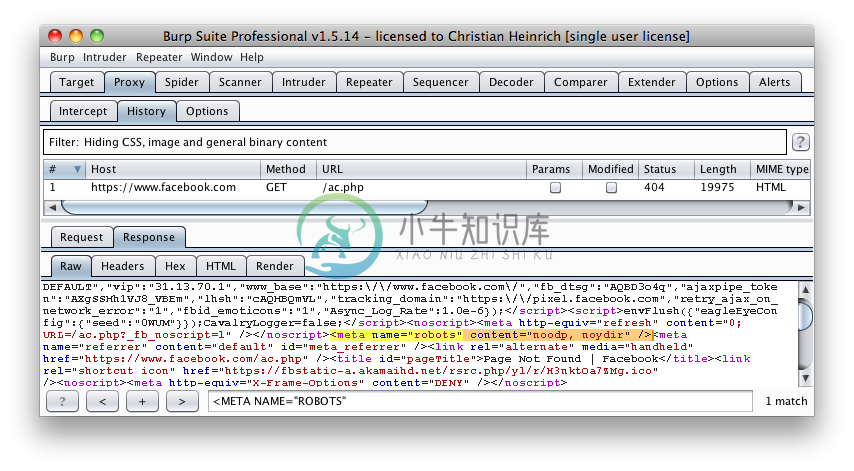
上面可以当做一个失败的例子,因为"INDEX,FOLLOW"是“机器人排除协议”中默认的<META>标签描述,但是 "Disallow: /ac.php"却在robots.txt中清楚表明,两者相互矛盾。
测试工具
- Browser (View Source function)
- curl
- wget
- rockspider
参考资料
白皮书
- [1] "The Web Robots Pages" - http://www.robotstxt.org/
- [2] "Block and Remove Pages Using a robots.txt File" - https://support.google.com/webmasters/answer/156449
- [3] "(ISC)2 Blog: The Attack of the Spiders from the Clouds" - http://blog.isc2.org/isc2_blog/2008/07/the-attack-of-t.html
- [4] "Telstra customer database exposed" - http://www.smh.com.au/it-pro/security-it/telstra-customer-database-exposed-20111209-1on60.html