《中兴优招》专题
-
Hibernate vs JPA vs JDO-各自的优缺点?
问题内容: 我对ORM这个概念很熟悉,几年前甚至在n.ibernate项目中使用过nHibernate。但是,我没有跟上Java中ORM的话题,也没有机会使用任何这些工具。 但是,现在我可能有机会开始对我们的一个应用程序使用一些ORM工具,以尝试摆脱一系列旧式Web服务。 我很难说出JPA规范之间的区别,您从Hibernate库本身获得的收益以及JDO必须提供的收益。 因此,我知道这个问题有点开放
-
 JavaScript代码性能优化总结(推荐)
JavaScript代码性能优化总结(推荐)本文向大家介绍JavaScript代码性能优化总结(推荐),包括了JavaScript代码性能优化总结(推荐)的使用技巧和注意事项,需要的朋友参考一下 下面是我总结的一些小技巧,仅供参考。 以下代码基本上在jQuery的源码里面都可以看到,如有说得不对的地方,请大家指出。 尽量使用源生方法 javaScript是解释性语言,相比编译性语言执行速度要慢。浏览器已经实现的方法,就不要再去实现一遍了。另
-
21条MySQL优化建议(经验总结)
本文向大家介绍21条MySQL优化建议(经验总结),包括了21条MySQL优化建议(经验总结)的使用技巧和注意事项,需要的朋友参考一下 今天一个朋友向我咨询怎么去优化 MySQL,我按着思维整理了一下,大概粗的可以分为21个方向。 还有一些细节东西(table cache, 表设计,索引设计,程序端缓存之类的)先不列了,对一个系统,初期能把下面做完也是一个不错的系统。 1. 要确保有足够的内存 数
-
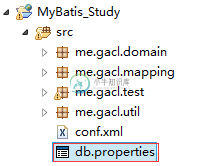 MyBatis学习教程(三)-MyBatis配置优化
MyBatis学习教程(三)-MyBatis配置优化本文向大家介绍MyBatis学习教程(三)-MyBatis配置优化,包括了MyBatis学习教程(三)-MyBatis配置优化的使用技巧和注意事项,需要的朋友参考一下 一、连接数据库的配置单独放在一个properties文件中 之前,我们是直接将数据库的连接配置信息写在了MyBatis的conf.xml文件中,如下: 其实我们完全可以将数据库的连接配置信息写在一个properties文件中
-
如何禁用V8的优化编译器
问题内容: 我正在编写一个常量字符串比较函数(用于node.js),并且想为此功能禁用V8的优化编译器;使用命令行标志是不可能的。 我知道,使用(或try / catch语句)块将禁用优化编译器 现在 ,但恐怕这个“功能”(错误)将被固定在未来的版本。 是否有一种不可变(且已记录)的方式来禁用V8的优化编译器? 示例功能: 性能测试只是为了好玩。 问题答案: 如果您想要可靠的方法来执行此操作,则需
-
AJAX工作原理及优缺点详解
本文向大家介绍AJAX工作原理及优缺点详解,包括了AJAX工作原理及优缺点详解的使用技巧和注意事项,需要的朋友参考一下 AJAX 是一种用于创建快速动态网页的技术。通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。 一、ajax所包含的技术 大家都知道ajax并非一种新的技术,而是几种原有技术的结合体。它由下列技
-
最全面的JVM优化经验总结
本文向大家介绍最全面的JVM优化经验总结,包括了最全面的JVM优化经验总结的使用技巧和注意事项,需要的朋友参考一下 开始之前 Java 虚拟机有自己完善的硬件架构, 如处理器、堆栈、寄存器等,还具有相应的指令系统。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 Java 虚拟机上运行的目标代码 (字节码), 就可以在多种平台上不加修改地运行。Java 虚拟机在执行字节码
-
19个MySQL性能优化要点解析
本文向大家介绍19个MySQL性能优化要点解析,包括了19个MySQL性能优化要点解析的使用技巧和注意事项,需要的朋友参考一下 以下就是跟大家分享的19个MySQL性能优化主要要点,一起学习学习。 1、为查询优化你的查询 大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中
-
基于js文件加载优化(详解)
本文向大家介绍基于js文件加载优化(详解),包括了基于js文件加载优化(详解)的使用技巧和注意事项,需要的朋友参考一下 在js引擎部分,我们可以了解到,当渲染引擎解析到script标签时,会将控制权给JS引擎,如果script加载的是外部资源,则需要等待下载完后才能执行。 所以,在这里,我们可以对其进行很多优化工作。 放置在BODY底部 为了让渲染引擎能够及早的将DOM树给渲染出来,我们需要将sc
-
Python优化(-O或PYTHONOPTIMIZE)有什么作用?
问题内容: 该文档只说Python解释器执行“基本优化”,而没有涉及任何细节。显然,它取决于实现,但是有什么方法可以使您优化哪种类型的东西,以及可以节省多少运行时间? 使用-O有什么缺点吗? 我唯一知道的是-O disables ,但大概不应该将它用于生产中仍然可能出错的事情。 问题答案: 要验证不同版本的CPython的效果,请grep的源代码。 链接到官方文档:https : //docs.p
-
正则表达式 - 运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。 相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序: 运算符 描述 \ 转义符 (), (?:), (?=), [] 圆括号和方括号 *, +, ?, {n}, {n,}, {n,m} 限定符 ^, $, \任何元字符、任何字符 定位点和序列(即:位置和顺序) | 替
-
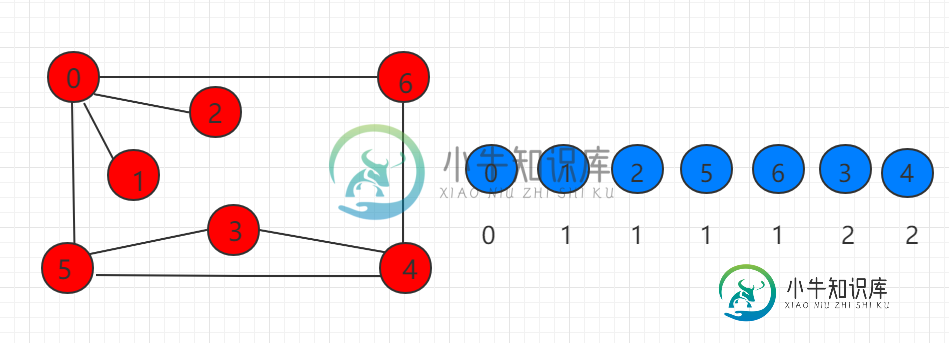 广度优先遍历与最短路径
广度优先遍历与最短路径主要内容:src/runoob/graph/ShortestPath.java 文件代码:广度优先遍历从某个顶点 v 出发,首先访问这个结点,并将其标记为已访问过,然后顺序访问结点v的所有未被访问的邻接点 {vi,..,vj} ,并将其标记为已访问过,然后将 {vi,...,vj} 中的每一个节点重复节点v的访问方法,直到所有结点都被访问完为止。 我们可以分为三个步骤: (1)使用一个辅助队列 q,首先将顶点 v 入队,将其标记为已访问,然后循环检测队列是否为空。 (2)如果队列不为空
-
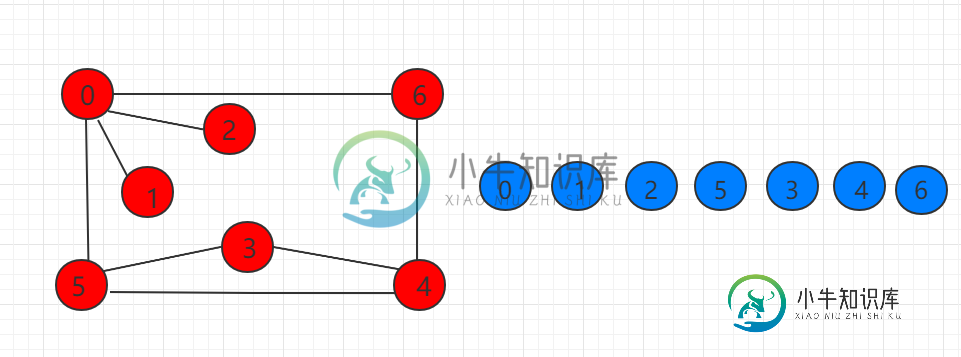 深度优先遍历与连通分量
深度优先遍历与连通分量主要内容:src/runoob/graph/Components.java 文件代码:深度优先遍历(Depth First Search)的主要思想是首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点。当没有未访问过的顶点时,则回到上一个顶点,继续试探别的顶点,直至所有的顶点都被访问过。 下图示例的图从 0 开始遍历顺序如右图所示: 无向图 G 的一个极大连通子图称为 G 的一个连通分量(或连通分支)。连通图只有一个连通分量,即其自身;非连通的无向图有多个连通
-
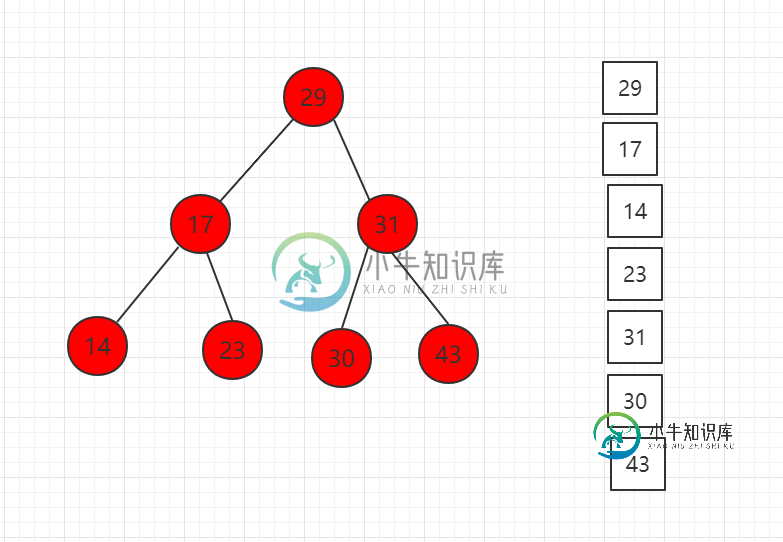 二分搜索树深度优先遍历
二分搜索树深度优先遍历主要内容:src/runoob/binary/Traverse.java 文件代码:二分搜索树遍历分为两大类,深度优先遍历和层序遍历。 深度优先遍历分为三种:先序遍历(preorder tree walk)、中序遍历(inorder tree walk)、后序遍历(postorder tree walk),分别为: 1、前序遍历:先访问当前节点,再依次递归访问左右子树。 2、中序遍历:先递归访问左子树,再访问自身,再递归访问右子树。 3、后序遍历:先递归访问左右子树,再访问自身节
-
 哈夫曼树(赫夫曼树、最优树)
哈夫曼树(赫夫曼树、最优树)主要内容:哈夫曼树相关的几个名词,什么是哈夫曼树,构建哈夫曼树的过程,哈弗曼树中结点结构,构建哈弗曼树的算法实现赫夫曼树,别名“哈夫曼树”、“最优树”以及“最优 二叉树”。学习哈夫曼树之前,首先要了解几个名词。 哈夫曼树相关的几个名词 路径: 在一棵树中,一个结点到另一个结点之间的通路,称为 路径。图 1 中,从根结点到结点 a 之间的通路就是一条路径。 路径长度:在一条路径中,每经过一个结点,路径长度都要加 1 。例如在一棵树中,规定根结点所在层数为1层,那么从根结点到第 i 层结点的路径长度