《中兴优招》专题
-
Java关闭后的Scala优势
问题内容: 随着闭包被添加到Java中,Scala作为语言选择优于Java的优势是什么? 有人可以详细说明任何优势吗? 问题答案: 除了闭包(Java似乎没有闭包之外),这是Java中缺少的Scala功能列表。我将在此处省略库,而将重点放在语言本身的功能上。这无论如何都不是全面的,但我认为它包含了大笔票。 隐式参数/转换 模式匹配,案例类 类型推断(某些) 种类较多的类型(对类型构造函数的抽象)
-
公告栏-数据库优化
问题内容: 这个问题是从这一后续 问题 项目与问题 我目前正在从事的项目是一个大型非营利组织的公告栏。公告板将用于允许组织内部的部门间通信。 我正在构建应用程序,并且一直无法从数据库中提取所需的结果,因为我认为它没有适当地规范化,并且由于我对关系数据库理论和mysql的了解有限。 总体而言,我希望您对委员会的设计有所投入,尤其是可以通过改进数据库结构来促进高效查询并帮助我更快地开发此应用程序和将来
-
Java HashMap性能优化/替代
问题内容: 我想创建一个大型HashMap,但性能不够好。有任何想法吗? 欢迎其他数据结构建议,但我需要Java Map的查找功能: 就我而言,我想创建一个包含2600万个条目的地图。使用标准的Java HashMap,插入2到3百万次后,放置速度会变得异常缓慢。 另外,有人知道对密钥使用不同的哈希码分布是否有帮助? 我的哈希码方法: 我正在使用adding的关联属性来确保相等的对象具有相同的哈希
-
Java线程优先级无效
问题内容: 这是关于线程优先级的测试。该代码来自《 Thinking in Java p.809》 我不知道为什么我不能得到像这样的常规结果: 但是结果是随机的(每次运行时都会改变): 我在Win 7 64位JDK 7中使用i3-2350M 2C4T CPU,这有关系吗? 问题答案: Java线程优先级无效 线程优先级是高度特定于操作系统的,并且在许多操作系统上的影响通常很小。优先级有助于仅对运行
-
如何优化打印样式?
本文向大家介绍如何优化打印样式?相关面试题,主要包含被问及如何优化打印样式?时的应答技巧和注意事项,需要的朋友参考一下 参考文章
-
SQL多行作为列(优化)
问题内容: 我有一个SQL查询,给出正确的结果,但执行速度太慢。 该查询对以下三个表进行操作: 包含许多客户数据,例如姓名,地址,电话等。为简化表格,我仅使用名称。 包含某些自定义(而非客户)数据。(表是用软件创建的,这就是为什么该表的复数形式是错误的) 将自定义数据与客户相关联。 顾客 自订资料 customercustomdatarels (客户数据和自定义数据之间的关系-具有相应的值) 我想
-
angularjs性能优化的方法
本文向大家介绍angularjs性能优化的方法,包括了angularjs性能优化的方法的使用技巧和注意事项,需要的朋友参考一下 学习angularjs有一段时间了,但是一直都没有怎么考虑过性能方面的问题,上次在研究过滤器的时候涉及到了性能问题。所以自己也总结了下常用的性能优化。 优化$watch 1.及时移除不必要的watch 2.尽量避免深度watch 我们都知道$watch有三个参数,第三个参
-
迭代器的性能优势?
问题内容: 使用迭代器可以提供什么(如果有的话)性能优势。似乎是解决许多问题的“正确方法”,但是它会创建更快/更具有内存意识的代码吗?我在用Python专门思考,但不要仅仅局限于此。 问题答案: 实际上在python邮件列表上有一封很好的邮件: Iterators vs Lists 。这有点过时(从2003年开始),但是据我所知,它仍然有效。 总结如下: 对于小型数据集,基于迭代器和列表的方法具有
-
TreeSet的优缺点是什么?
问题内容: 只是想知道TreeSet的优缺点是什么,是否有人可以告诉我?谢谢! 问题答案: 收藏类之一。它使您可以按键或按键顺序访问集合中的元素。它比ArrayList或HashMap具有更多的开销。当您不需要顺序访问时,只需按键查找即可使用HashSet。使用ArrayList并使用Arrays。如果只想按顺序排列元素,则排序。TreeSet始终保持元素顺序。使用ArrayList,您可以在需要
-
 抢先式优先级调度
抢先式优先级调度在抢占式优先级调度中,在进程到达就绪队列时,其优先级与就绪队列中存在的其他进程的优先级以及CPU在该点执行的优先级进行比较。 在所有可用的进程中具有最高优先级的那个将被赋予CPU。 抢先优先级调度和非抢占优先级调度之间的区别在于,在抢先优先级调度中,正在执行的作业可以在更高优先级作业到达时停止。 一旦所有作业在就绪队列中可用,算法将表现为非抢占式优先级调度,这意味着计划的作业将运行直至完成并且不会
-
kubernetes豆荚的优雅终止
我们有一个应用程序,其中包含 4 个 pod,并使用负载均衡器运行!我们想尝试滚动更新,但我们不确定当 Pod 出现故障时会发生什么!文档不清楚!特别是《豆荚的终止》中的这句话: Pod将从服务的endpoint列表中删除,并且不再被视为复制控制器的运行Pod集的一部分。缓慢关闭的Pod可以继续为流量提供服务,因为负载平衡器(如服务代理)将它们从轮换中删除。 因此,如果有人能在以下问题上指导我们:
-
Proxyquire、rewire、SandboxedModule和Sinon:优缺点
在模拟节点依赖关系时,我遇到了以下库: 代理 重新布线 沙盒模块 锡农 它们似乎都做了或多或少相同的事情:允许您模拟调用(Sinon除外,它模拟了几乎所有的东西)。它们似乎都需要一些非常复杂的设置,注意传递给的字符串的确切语法--在重构期间不太好。 每个图书馆的利弊是什么?我什么时候会选择一个而不是另一个?每个库都擅长的示例用例是什么?这个空间还有哪些产品比较好?
-
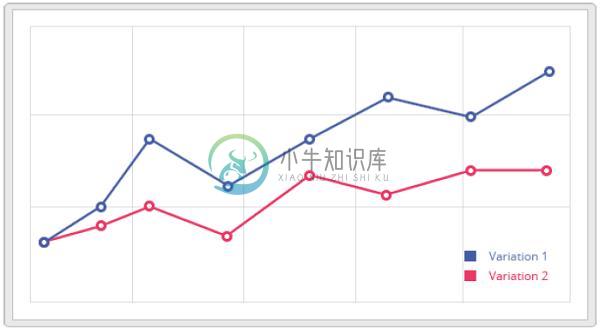 A/B测试优化结果
A/B测试优化结果当实验完成,下一步就是分析结果。 A/B测试工具将显示实验中的数据,并会告诉您使用数学方法和统计的帮助,网页上的不同变化如何执行,以及变化之间是否存在显着差异。 示例 如果网页上的图像降低了跳出率,当在网页上上传多个图像时可以判断决定是否有良好的转换。 如果您因此看到跳出率没有变化,请返回上一步并创建一个新的假设/变体以执行新的测试。 像VWO和Optimizely这样的工具可用于运行测试,但Go
-
优化的冒泡排序(Java)
问题内容: 我想知道还有什么可以优化冒泡排序的方法,以便即使在第一次通过之后也可以忽略已经排序的元素。 我们观察到[4,5,6]已经按顺序排列,如何修改我的代码,以便在下一遍中忽略这3个元素?(这意味着排序会更有效?)您是否建议使用递归方法? 谢谢你的时间! 问题答案: 首先,您具有越界访问权限: 因为,所以循环条件应该是。 但是,在Bubble排序中,您知道经过传递后,最大的元素将在数组的最后一
-
Java:具有优先级的ReentrantReadWriteLock
问题内容: 以下是典型的读写器模式(很多读取而很少写入) 我想知道是否有可能优先考虑作家和读者?例如,如果其他线程不断持有读取锁,通常writer可能会等待很长一段时间(也许永远),因此有可能使writer具有更高的优先级,因此只要有writer出现,就可以认为它是高优先级(跳过行)之类的。 问题答案: 按照javadoc的,JDK实现并 不会 有任何读/写器的优先级。但是,如果你使用了“公平”的