《中兴优招》专题
-
 Jfreechart优化X轴标签
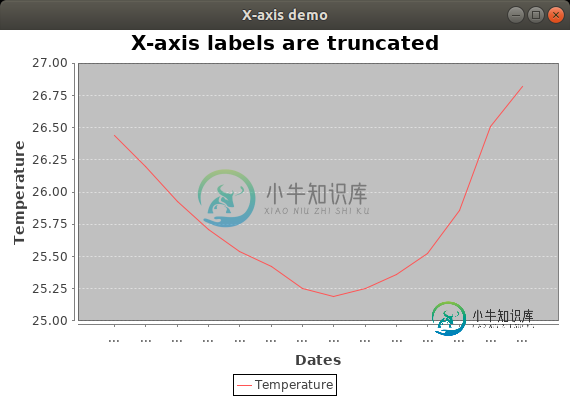
Jfreechart优化X轴标签在JFreechart中,我有一个带有日期(和时间)的X轴。 我怎样才能让JFreechart优化它们并充分利用它们? 现在它包含的标签比空间多,所有标签都转换为“…”。 如果不是所有的刻度都有标签,这是完全可以的,但是我想要尽可能多的(如果它们合适并且可以完全显示)。 我怎样才能做到这一点? 这里是完整的最小源来重现截断的标签。(默认情况下,JFreechart不处理优化: 我更喜欢像@tras
-
RabbitMQ和消息优先级
RabbitMQ有消息优先级的概念吗?我有一个问题,一些更重要的消息由于队列中不太重要的消息而被拖慢。我希望高优先级的优先,并移动到队列的前面。 我知道我可以用两个队列来近似计算,一个是“快”队列,另一个是“慢”队列,但这看起来像是一个黑客。 有人知道使用RabbitMQ的更好的解决方案吗?
-
什么是优步罐子?
我在阅读Maven文档时遇到了这个名称。 是什么意思?它的特性/优点是什么?
-
我应该优化多少?
关于编译器(GCC)所做的优化,标准做法是什么?每个选项(-O、-O1、-O2、-O3、-Os、-s、-fexpensive-optimizations)有什么不同,我如何决定什么是最优的?
-
Camel doCatch和onException优先级
对于特定的路由,我有一个带有doTry()-doCatch()对的路由,而通常是onException()。 附言。删除onException()会调用doCatch()。然而,我有理由保留这两个。Camel版本为:org.apache.Camel:camel-cxf:2.21.0.000033-fuse-000001-redhat-1
-
优化的汇编代码
因此,通常关于通过汇编代码提高性能的问题的答案是“不要打扰,编译器比你聪明”。我明白了。 但是,我注意到优化的线性代数库(例如ACML)可以比标准编译库实现2到5倍的性能改进。例如,在我的8核机器上,与现有的单线程BLAS实现相比,优化的矩阵乘法运行速度快了30倍以上,这意味着,在考虑了由于使用所有内核而提高的8倍之后,仅仅通过优化仍然可以提高4倍。 所以在我看来,优化的汇编代码确实可以带来巨大的
-
 优化算术编码器
优化算术编码器我正在优化名为PackJPG的C库的编码步骤 我使用英特尔 VTune 分析了代码,发现当前的瓶颈是 PackJPG 使用的算术编码器中的以下函数: 这个函数好像借鉴了一些来自:http://paginas . Fe . up . pt/~ vinho za/itpa/BOD den-07-algorithm-tr . pdf我已经设法对函数做了一些优化(主要是通过加快位写的速度)但是现在卡住了。
-
函数返回值优化?
我正在编写自己的编程语言,由于各种原因,它编译为C。(其中之一是我对汇编知之甚少)。 我有一个关于编译器(例如GCC或Clang)如何优化从函数返回值的问题。假设我有这样的代码: 我的理解是,您可能希望变量A在从FUNC返回时复制到B(如果A和B是结构,这可能会很昂贵)。编译器会认识到在这种情况下,B可以指向a所在的位置,而不需要拷贝吗? 如果main()看起来像这样:怎么办? 谢谢大家!
-
优化Spring Data JPA查询
我正在为框架生成的查询寻找可能的优化。据我所知,过程如下: > 您可以将域对象声明为POJO并添加几个注释,例如、、等。 您声明您的存储库,例如每个接口 使用(2),您有几个选项来描述您的查询:例如,每个方法名或 如果我写一个类似如下的查询: SQL查询是自动生成的,其中订单的每一列都会被解析,然后依次针对订单位置和依赖对象/表。就像我写道: 因此,如果我需要来自多个联接对象的一些信息,查询可能非
-
Hazelcast射流内部优化
提前致谢
-
Spring Boot配置优先级
我正在做一个新的项目,第一次使用Spring-Boot。 传统上,在使用Spring和属性文件进行配置时,我在发行版(WAR)中提供了默认属性,并允许在某个文档位置重写它们。 例如: 这将允许我们在不丢失本地系统配置的情况下重新部署应用程序。 我喜欢Spring,因为它允许我们遵守惯例,这让我担心我可能做错了属性级联。 什么是提供包含在发行版中的外部化属性的最合适的方法,该属性具有合理的默认值(嵌
-
点燃数据流优化
我正在使用以下设置: 我的记录大小大约是2000字节。并查看“Grid-Data-Loader-Flusher”线程状态,如下所示: 线程数平均最长持续时间网格-数据-加载器-冲洗器-#100 38 4,737,793.579 30,427,862 180,036,156 数据流的最佳配置是什么? 谢谢
-
优步Cadence生产设置
我在找一个微服务协调器,遇到了优步卡登斯。我已经阅读了文档,并在开发设置中使用了它。 我对生产场景有几个问题: > 是否建议为工作流及其使用的不同活动设置一个专用的任务列表?或者,我们应该为所有人使用一个任务列表?这个决定会影响可扩展性或性能吗? 当我们添加新的工作线程计算机时,在同一台计算机中为不同的活动/工作流运行所有工作线程是否是一种常见的做法?例: 或者我们应该在专用机器中运行每个活动/工
-
定义优先级队列
考虑下面的优先级类声明<代码>类优先级队列 我的想法: 我能想到的一件事是,这将强制优先级队列使用对象比较器,并且不会提供实现其自定义比较器的能力,因为类的用户可能希望基于某个不同的比较器构建队列。
-
优化字符串分析
我需要解析“txf”格式的数据文件。这些文件可能包含 1000 多个条目。由于格式像JSON一样定义得很好,我想做一个像JSON这样的通用解析器,它可以序列化和解串化txf文件。 与JSON相反,标记没有办法识别对象或数组。如果一个带有相同标签的条目出现,我们需要把它看作一个数组。 标记对象的开始。 标记对象的成员 标记对象的结尾 下面是一个示例“txf”文件 我能够使用NSScanner创建通用