《中兴优招》专题
-
在WebApp中优雅地关闭ExecutorService?
在我的webapp中,我创建了一个使用具有固定大小线程池的的服务。我在整个应用程序生命周期中重用相同的。 All在Tomcat中运行,在关闭时出现以下错误: 我确实意识到在关闭tomcat之前需要关闭ExecutorService。Soms所以线程已经谈到了这一点,但我找不到一个干净的方法来处理这一点。 我是否应该使用,就像@tim-bender建议的那样,在优雅地关闭线程和执行器?还是应该使用C
-
Java SE8中parallelStream的优点[副本]
除了我的代码运行在单个核心机器上(此时我假设JVM会将所有工作分配给单个core,从而不会破坏我的程序)之外,到处使用parallelStream()是否有任何缺点?
-
 优化JavaFX中的内存泄漏
优化JavaFX中的内存泄漏我写了一段代码,让字母在我写的时候出现并飞行。这个问题消耗了大量的内存。 我已经优化了一点 在侦听器中共享对象并更新其参数。 每次打印新字母时调用 gc 但是它仍然使用大量的内存,所以有什么想法来降低它的内存利用率吗? 提前致谢。 操作系统:Arch Linux 64位平台:英特尔i7-第三代,8 GB内存IDE : Intellij JDK : 1.8.0_102
-
闭站保护(升级优化中)
什么是闭站保护 由网站自身原因(改版、暂停服务等)、客观原因(服务器故障、政策影响等)造成的网站较长一段时间都无法正常访问,百度搜索引擎会认为该站属于关闭状态。站长可以通过闭站保护工具进行提交申请,申请通过后,百度搜索引擎会暂时保留索引、暂停抓取站点、暂停其在搜索结果中的展现。待网站恢复正常后,站长可通过闭站保护工具申请恢复,申请审核通过后,百度搜索引擎会恢复对站点的抓取和展现,站点的评价得分不会
-
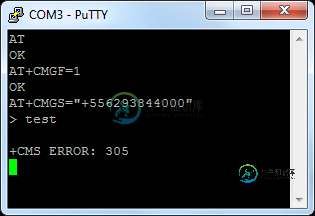 如何通过3G调制解调器发送短信-中兴MF190
如何通过3G调制解调器发送短信-中兴MF190我有一个调制解调器中兴型号MF190,并希望通过在串行端口上的AT命令发送短信。我的问题是:当我发送AT命令时,调制解调器响应错误CMS error:305 他研究了很多关于错误的信息,他在信息中使用了一些无效字符,但我在信息中没有写任何错误。 检查: 有趣的是,如果我发送一条空消息,我就会收到短信(显然是空的) 有人去过那里,知道如何通过这种型号的调制解调器配置或发送短信?
-
 小米/中兴——面试问题总结(嵌入式软件开发)
小米/中兴——面试问题总结(嵌入式软件开发)小米一面: inline函数 c语言与c++的区别。 重写、重载和隐藏的定义。 virtual修饰。 volatile 的作用。 驱动层的同步机制 const与define的区别。 static的用法。 中兴 1.二叉树的查找的时间复杂度? 2.任务调度的方式。 3.快速排序的时间复杂度。 4.select的返回值,有事件连接。 5.设计模式介绍一下。 6.IIC说一下。 7.交叉编译器用的哪个。
-
 中兴-未来领军-软件开发工程师-网络安全
中兴-未来领军-软件开发工程师-网络安全一面 2023-7-19 自我介绍; OSI网络七层/五层模型; Ping属于哪一层?底层依赖什么协议? TCP和UDP的主要区别? 如何结合TCP和UDP,保证大量数据传输效率的同时尽可能增加数据可靠性? HTTP3.0基于的底层协议是什么?具有哪些特性? 使用过/常见的对称密码算法?哪些具有安全问题?具有什么样的安全问题? 使用过/常见的非对称密码算法? 对称和非对称密码算法的适用场景? 使用
-
Java优化
问题内容: 我想知道两者之间是否有任何性能差异 字符串s = someObject.toString(); System.out.println(s); 和 System.out.println(someObject.toString()); 查看生成的字节码,似乎有所不同。JVM是否能够在运行时优化此字节码,以使两个解决方案提供相同的性能? 在这种简单情况下,当然解决方案2似乎更合适,但有时出于
-
1.5.6 优化
为了减小能源消耗,IEEE 802.15.4 以及其它类似的链路层技术很少使用(甚至不使用)多播发送信号。此外,无线网络可能不完全遵循传统的 IP 子网和 IP 连接的概念。IPv6 邻居发现机制并不是设计用于非传输无线连接,因为它依赖于传统的 IPv6 连接,且由于它大量使用多播而降低了效率。这在低功耗有损网络中时不切实际的。 基于这个原因,人们已经对 IPv6 邻居发现机制进行了一些简单的优化
-
lightgbm优势
本文向大家介绍lightgbm优势相关面试题,主要包含被问及lightgbm优势时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1)更快的训练速度和更高的效率:LightGBM使用基于直方图的算法。2)更低的内存占用:使用离散的箱子(bins)保存并替换连续值导致更少的内存占用。3)更高的准确率(相比于其他任何提升算法):它通过leaf-wise分裂方法产生比level-wise分裂方法更
-
Gekko优化
我正在解决这个优化问题,我需要计算出我需要打开多少个配送中心,以满足12家公司设施的需求,同时最小化运输成本。运输成本只是配送中心之间的距离乘以每英里成本,然而在这个问题中,每英里成本是一美元。我有5个选择,分别是波士顿、纳舒亚、普罗维登斯、斯普林菲尔德和伍斯特,这5个是12家公司设施的一部分。 我解决了这个问题,得到了正确的答案,但是后来我试图在同一个代码中添加两个约束,我得到的答案是不正确的。
-
1.5.14 优化
了解explain db.usermodels.find({ '_id' :{ "$gt" :ObjectId("55940ae59c39572851075bfd") } }).explain() 关注点 stage:查询策略 nReturned:返回的文档行数 needTime:耗时(毫秒) indexBounds:所用的索引 http://docs.mongodb.org
-
MySQL 优化
下面说的优化基于 MySQL 5.6,理论上 5.5 之后的都算适用,具体还是要看官网 服务状态查询 查看当前数据库的状态,常用的有: 查看系统状态:SHOW STATUS; 查看刚刚执行 SQL 是否有警告信息:SHOW WARNINGS; 查看刚刚执行 SQL 是否有错误信息:SHOW ERRORS; 查看已经连接的所有线程状况:SHOW PROCESSLIST; 查看当前连接数量:SHOW
-
33.6. 优化
大多数shell脚本处理不复杂的问题时会有很快的解决办法. 正因为这样,优化脚本速度不是一个问题. 考虑这样的情况, 一个脚本处理很重要的任务, 虽然它确实运行的很好很正确,但是处理速度太慢. 用一种可编译的语言重写它可能不是非常好的选择. 最简单的办法是重写使这个脚本效率低下的部分. 这个代码优化的原理是否同样适用于效率低下的shell脚本? 检查脚本中的循环. 反复执行操作的时间消耗增长非常的
-
凸优化
Jensen不等式 如果$$f: \omega->R$$是一个函数,则对于任何$$[{ x_i \in \Omega }]{n}{i=1}$$以及凸组合$$\sum{i=1}{n} w_ix_i$$都有 $$\sum_{i=1}{n} w_if(x_i)>=f(\sum_{i=1}{n} w_ix_i)$$ $$L(x,\lambda ,v) = f_0(x)+\sum_{i=1}{m}\lamb