《福瑞泰克Freetech》专题
-
杰克逊将对象转换为地图保存日期类型
问题内容: 我正在使用Jackson 将Java Bean转换为。 但是,它不是保留对象,而是将其转换为。 这是失败的测试用例, 有一个简单的解决方案吗? 问题答案: 默认情况下,Jackson将实例序列化为数字时间戳。您可以将Jackson配置为使用带有 或提供您自己的。 但是,当您进行转换时,中间JSON和目标类型中绝对没有任何内容可向Jackson表示应将其反序列化为对象。如果没有额外的类型
-
强迫杰克逊反序列化为特定的原始类型
问题内容: 我正在使用Jackson 1.8.3将以下域对象序列化和反序列化为JSON 然后使用以下代码对对象进行序列化和反序列化 然后用 对象的原始值为Strings,Doubles,Longs或Booleans。但是,在序列化和反序列化过程中,Jackson将Long值(例如4)转换为Integers。 如何“强制” Jackson将数字非十进制值反序列化为Long而不是Integer? 问题
-
克隆HashSet时如何避免未经检查的转换警告?
问题内容: 我正在尝试制作一个称为myHash的Point HashSet的浅表副本。截至目前,我有以下内容: 这段代码给了我一个未经检查的强制转换警告。有一个更好的方法吗? 问题答案: 您可以尝试以下方法:
-
有什么方法可以克隆HTML5 canvas元素及其内容?
问题内容: 有什么方法可以创建包含所有绘制内容的canvas元素的 深层 副本? 问题答案: 实际上,复制画布数据的正确方法是将旧画布传递到新的空白画布。试试这个功能。 使用getImageData用于像素数据访问,而不用于复制画布。使用它进行复制非常缓慢,并且很难在浏览器上进行。应该避免。
-
组织。xml。萨克斯。SAXParseException:prolog问题中不允许包含内容
我正在尝试使用jasperreports,当我尝试运行正在开发的应用程序时,我遇到了下一个错误: 对于我写的代码: 怎么了?。谢谢。xml是这样的,我不知道出了什么问题: 再次感谢。
-
使用GitLab令牌进行克隆而不进行身份验证
我想使用我的GitLab帐户中的私有令牌克隆GitLab存储库,而不提示输入我的自动化脚本。 有人能给我一个样品吗? 我知道我可以使用用户和密码执行此操作: 我知道使用ssh密钥是可能的 但是,这两种选择都是不够的。
-
在PHP中有人可以解释克隆vs指针引用吗?
问题内容: 首先,我了解编程和对象,但是在PHP中,以下内容对我而言意义不大。 在PHP中,我们使用&运算符检索对变量的引用。我理解引用是指使用不同变量引用相同“事物”的一种方式。如果我说例如 将输出3,因为对$ a所做的更改与对$ b所做的更改相同。反过来: 应该输出1。 在这种情况下,为什么必须使用clone关键字?在我看来,如果我定下 那么对$ obj_a所做的更改不应影响$ obj_b,相
-
 php实现图片添加描边字和马赛克的方法
php实现图片添加描边字和马赛克的方法本文向大家介绍php实现图片添加描边字和马赛克的方法,包括了php实现图片添加描边字和马赛克的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php实现图片添加描边字和马赛克的方法。分享给大家供大家参考。具体实现方法如下: 马赛克:void imagemask ( resource image, int x1, int y1, int x2, int y2, int deep) ima
-
Azure Devops OnPremise,致命:克隆Git repo时的身份验证失败
使用OnPremise Azure Devops 2019服务器,我试图通过在ProcessInfo中调用以下git命令以编程方式克隆git存储库: 这里是c#代码: 但我一直在犯错误 PAT是否使用不当?有什么建议吗
-
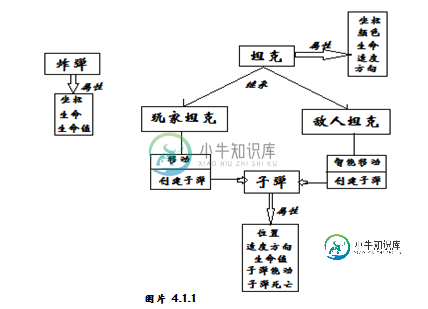 经典再现 基于JAVA平台开发坦克大战游戏
经典再现 基于JAVA平台开发坦克大战游戏本文向大家介绍经典再现 基于JAVA平台开发坦克大战游戏,包括了经典再现 基于JAVA平台开发坦克大战游戏的使用技巧和注意事项,需要的朋友参考一下 一、需求描述 1.功能性需求 在功能需求分析阶段,我们的主要任务是指定系统必须提供哪些服务,定义软件完成哪些功能,提供给那些人使用,功能需求是软件开发的一项基本需求,是需求分析必不可少的一部分。坦克大战是一款经典游戏了,本游戏学习了一些前辈们的经验,
-
克隆一个LLL并增加java中的每个元素[重复]
我正在尝试编写一个函数,它递归地复制给定的线性链表L,并以常量值x递增。当我在终端编译时,我得到了,这是一个内存位置,而不是实际的列表。我只想更改函数本身以提供正确的输出。
-
启动http时的spring云配置克隆。后缓冲区问题
我得到了问题。 应用yml 堆栈跟踪 问题和解决方案可能是什么?
-
本地(hg-git)克隆上游从(github)原始到fork的变化
我已经为Windows安装了Github,这样我就可以管理SSH密钥了。它生成了一个密钥(github_rsa),并将其附加到我的Github帐户。 我编辑了hgrc文件,并添加了一个设置,指向本地git'ssh'命令(隐藏在中)。 这样,如果我进入一个“git-shell”窗口,我猜它会生成ssh-agent,那么我可以输入命令,如“hg incommery”,连接就建立了。因此,我已经正确地设
-
使用杰克逊xml映射器将xml反序列化为pojo
问题内容: 我正在使用Jackson XML映射器将XML反序列化为POJO。XML看起来像 我的课看起来像 我想将电话号码设置为“电话”类别中的号码。我无法更改XML或类的构造方式。我收到无法构造错误的实例,并创建了一个AgencyPhone构造函数 但这没有用。那么如何反序列化嵌套实例。 问题答案: 您可以编写自己的自定义解串器来实现此目的。这是使您入门的代码:
-
将包含数据的Docker容器克隆到另一台主机
我有两个正在运行的docker容器。一个容器有MySQL和数据,另一个容器有Tomcat中的Java web应用程序。 如何使用数据将MySQL容器克隆到另一个Docker主机? 尝试了保存/加载方法。但是没有成功,因为没有数据 但是Java web应用程序容器正在工作