《福瑞泰克Freetech》专题
-
忽略python3中bot与discord一起生成的错误。派克
由于不和谐,我在python3中开发了一个小机器人。py插件,必须向Discord服务器中的所有用户发送私人消息。 因此,我创建了一个服务器上所有用户的列表,然后我创建了一个循环,通过删除bot将上述消息发送给所有用户。问题在于,在此用户列表中,有些用户已禁用服务器上的私人消息,因此bot无法发送消息并生成错误: 所以我希望机器人继续列表,尽管有错误。因此,我们可以找到参数并删除那些禁用带有条件的
-
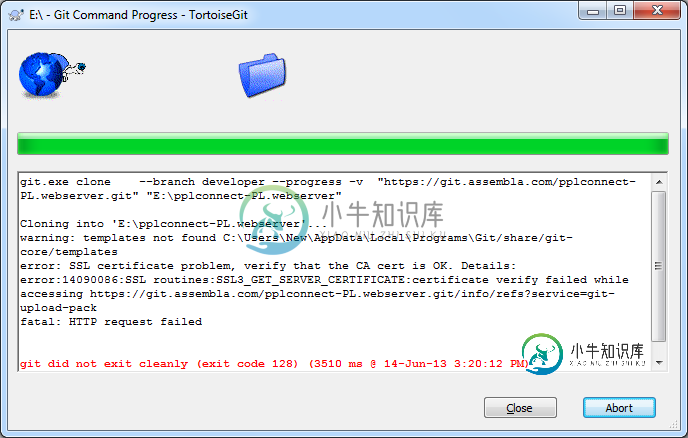 使用Ortoisegit创建git克隆时出现SSL证书问题
使用Ortoisegit创建git克隆时出现SSL证书问题我想克隆git仓库与TortoiseGit的帮助下,但我得到错误: 错误:SSL证书问题,请验证CA证书是否正常。详细信息:错误:14090086:SSL例程:SSL3\u获取\u服务器\u证书:访问时证书验证失败https://git.assembla.com/pplconnect-PL.webserver.git/info/refs?service=git-上载包致命:HTTP请求失败 git
-
不和谐机器人欢迎信息不起作用。派克
当成员加入服务器时,bot不会以消息响应。有什么问题吗?
-
浅谈Java中的克隆close()和赋值引用的区别
本文向大家介绍浅谈Java中的克隆close()和赋值引用的区别,包括了浅谈Java中的克隆close()和赋值引用的区别的使用技巧和注意事项,需要的朋友参考一下 学生类Student: 测试克隆学生类: 以上就是小编为大家带来的浅谈Java中的克隆close()和赋值引用的区别的全部内容了,希望对大家有所帮助,多多支持呐喊教程~
-
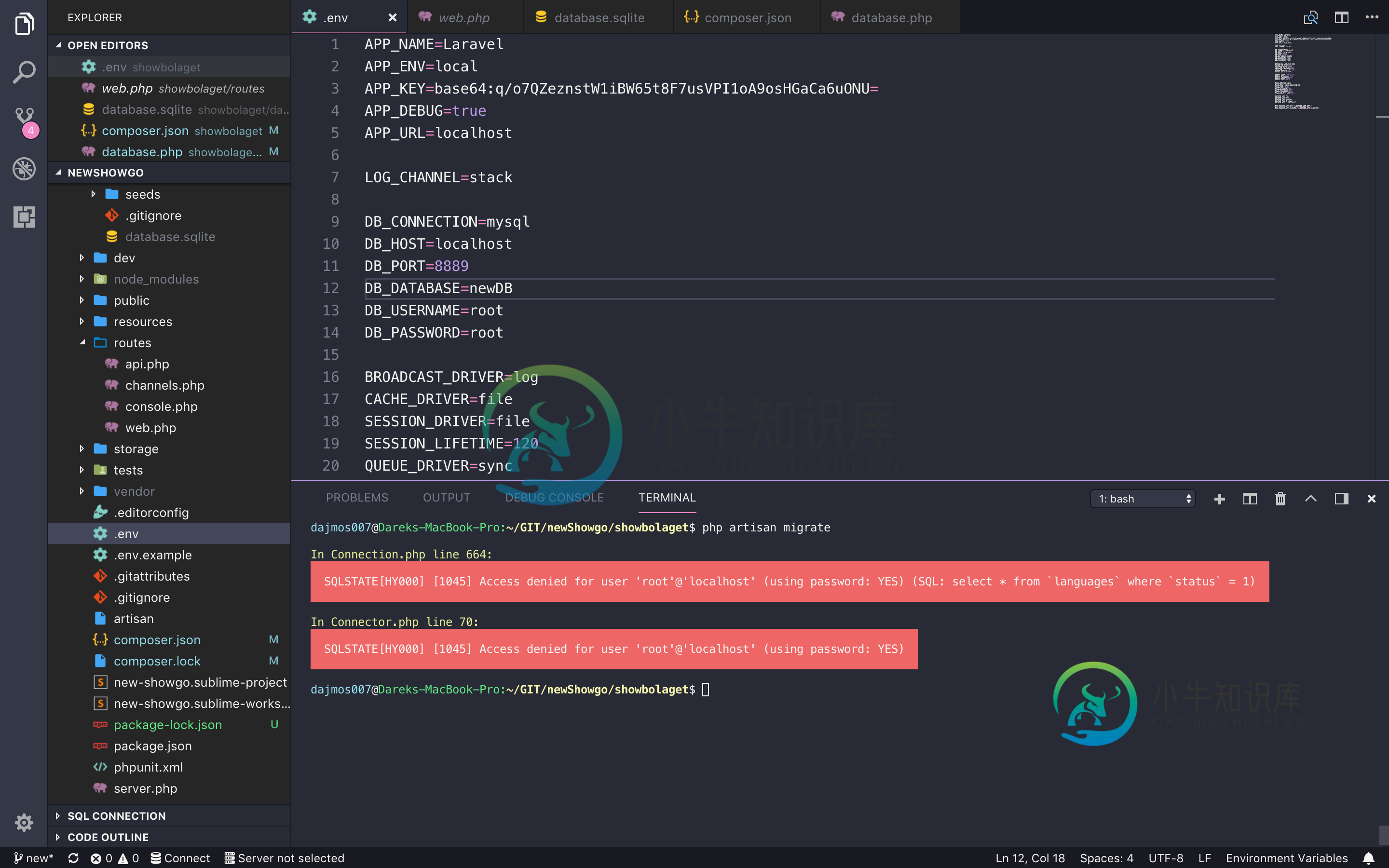 从repo//PHP laravel克隆项目后数据库出现问题
从repo//PHP laravel克隆项目后数据库出现问题我的Laravel项目有问题。从git克隆回购后,我做了 我有一个错误: 关于。php第664行: 用户“root”@“localhost”(使用密码:YES)的SQLSTATE[HY000][1045]访问被拒绝(SQL:select*fromwhere=1) 插入连接器。php第70行: 用户“root”@“localhost”的SQLSTATE[HY000][1045]访问被拒绝(使用密码:
-
试图克隆git回购后,Win控制台挂起[复制]
我有一个远程回购,我想克隆。我设置了pageant.exe并添加了私钥。还添加了GIT_SSH指向plink.exe.克隆命令后,我得到这样的输出 当键入或时,什么也没有发生,控制台只是挂起,我必须用终止命令 为什么会发生这种情况以及如何解决?
-
android camera2 api-将视频声音和麦克风一起录制
我正在尝试通过camera2 api录制我自己,同时观看视频。我想录制视频配乐,用麦克风音源录制表面。 我如何创建两个音轨,第一个为呈现给用户的视频,第二个为mediaRecorder AudioSource.mic
-
使用杰克逊反序列化为字符串或对象
问题内容: 我有一个有时看起来像这样的对象: 有时看起来像这样: 这些类如下所示: 第一种情况是第二种情况的简写。我想总是反序列化为第二种情况。 此外- 这是我们代码中非常常见的模式,因此我希望能够以通用方式进行序列化,因为与上述类似的其他类具有将String用作语法糖的相同模式。更复杂的对象。 我以为使用它的代码看起来像这样 如何编写可同时处理两种情况的自定义解串器(或其他模块)? 问题答案:
-
窗口功能SORT成本高昂,我们可以克服吗?
问题内容: 我的要求: 确定的前10个帐户,并按帐号升序排列。 询问: 痕迹: 指数: 该说,在列。 强制扫描的费用从3855降低至11092 表中的总行数为632667; 以上都是测试区域的结果。生产实际上是数量的两倍。 我的数据库是Exadata,Quarter RAC。运行Oracle 11g R2。该数据库功能强大到可以立即执行,但是DBA不愿使用13M的tempSpc。商业报告该报告的频
-
尝试使用gradle运行克隆项目但无法生成
我从github克隆了一个Spring boot项目,并在IntelliJ中打开了它。所以我正在尝试运行build.gradle,但我只得到了这个错误:
-
使用PDFBox克隆具有所有样式的表单字段
我们需要为我们的客户填写一个表格,并获得一个PDF,他们可以打印,签名 但我很难确定页码。由于表单由多个模板组合而成,我必须用PDFBox修复页码。到目前为止,我们在每页上都使用了一个样式化的输入字段。但由于它们都有相同的名字,我不能单独填写。 我可以以某种方式拆分或克隆字段并为它们提供单独的名称,以便我可以单独填充它们吗?当然,样式应该保持不变。
-
可以使用构造函数克隆方法创建对象
我一直认为,clone()创建对象时不需要调用构造函数。 但是,在阅读有效Java第11条:明智地覆盖克隆时,我发现了一条声明,上面写着 “不调用构造函数”的规定太强了。行为良好的克隆方法可以调用构造函数来创建正在构建的克隆内部的对象。如果类是最终的,克隆甚至可以返回构造函数创建的对象。 谁能给我解释一下吗?
-
Tensorflow gpu,ModuleNotFoundError:列车中没有名为“dataclasses”的模块。派克
我正在尝试在Windows10中使用tensorflow gpu 2.4。0到目标检测。我不知道如何修正这个错误,你能帮我吗? (tensorflow1)C:\tensorflow1\models\research\object\u detection 提前谢谢你!
-
Restcomm jain-slee jackson NoClassDefFoundError: com/快速xml/杰克逊/数据库/ObjectMapper
我正在使用restcomm jain slee编写IDR sender java应用程序 Im使用下面的json解码来解码传入的http post请求json数据。 为此目的,我使用快速xml杰克逊。 我正在WildFly Docker容器中部署这个。当试图解码jason时,我发现了这个错误。Java语言lang.NoClassDefFoundError:com/fasterxml/jackson
-
将CDS与斯巴达克斯集成时出现的问题
我已经创建了angular应用程序,并根据下面的文档做了相应的更改,并能够加载斯巴达克斯商店。https://sap.github.io/spartacus-docs/building-the-spartacus-storefront-from-libraries/试图通过https://sap.github.io/spartacus-docs/cds-integration下面的链接在相同的应用