《龙湖集团数字科技》专题
-
弹性式数据集 RDD
一、RDD简介 RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD 转换而来,它具有以下特性: 一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,
-
13 常用数据集 Datasets
CIFAR10 小图像分类数据集 50,000 张 32x32 彩色训练图像数据,以及 10,000 张测试图像数据,总共分为 10 个类别。 用法: from keras.datasets import cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data() 返回: 2 个元组: x_train, x_test:
-
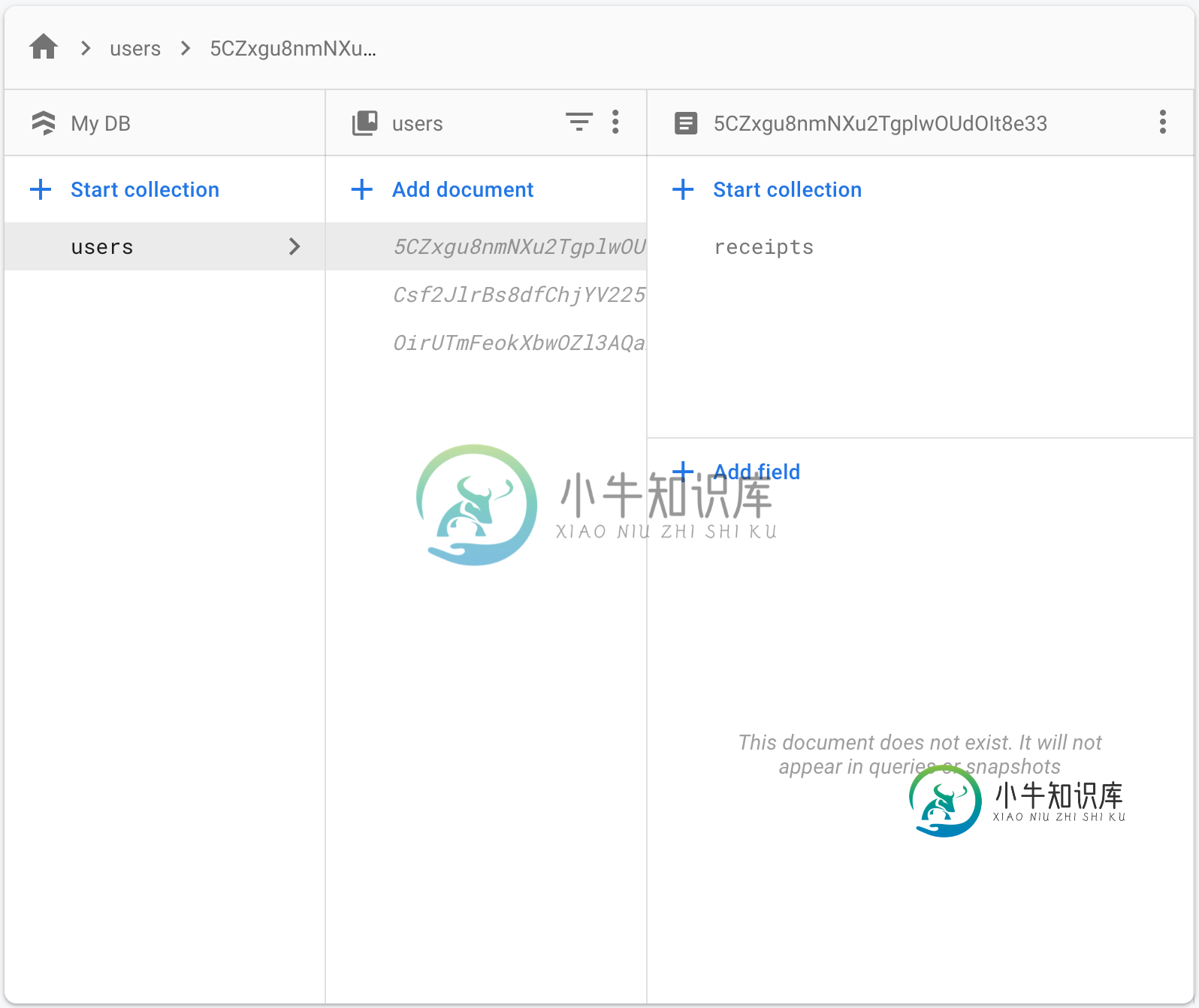 Firestore云函数空集合
Firestore云函数空集合我有一个困扰我好几天的问题。我正在尝试创建一个从Firestore数据库读取的Firebase云函数。 我的Firestore DB如下所示: 问题是我无法像这样列出: 如果我尝试这样做,我会得到空响应,就像我的集合中没有用户一样。 但我尝试直接访问用户它可以工作: 我的完整代码: 有人知道我做错了什么吗?非常感谢。
-
AWS SageMaker超大数据集
我有一个500GB的csv文件和一个1.5 TB数据的mysql数据库,我想运行aws sagemaker分类和回归算法和随机森林。 aws sagemaker能支持吗?模型可以批量或分块读取和训练吗?它的任何例子
-
了解RDD和数据集
从数据集和RDD文档中, 数据集: 数据集是特定领域对象的强类型集合,可以使用函数或关系操作并行转换。每个数据集还有一个称为DataFrame的无类型视图,它是行数据集 RDD: RDD表示可以并行操作的不可变、分区的元素集合 此外,据说它们之间的区别是: 主要区别在于,dataset是特定于域的对象的集合,而RDD是任何对象的集合。定义的域对象部分表示数据集的架构部分。所以,数据集API总是强类
-
Spark数据集API-连接
我正在尝试使用Spark数据集API,但在进行简单连接时遇到了一些问题。 假设我有两个带有字段的数据集:,那么在的情况下,我的连接如下所示: 但是,对于数据集,有一个。joinWith方法,但相同的方法不起作用:
-
Spark 1.6中的数据集
我正在评估将现有的RDD代码替换为Dataset。对于我的一个用例,我无法将数据集映射到另一个用例类。 以下是我想做的。。。 任何帮助都将不胜感激。 但以下例外情况:
-
带负数的子集和
我知道这是子集和问题的一个变体,我也见过类似问题的一些解决方案(带负数的子集和),但我需要用动态规划来解决这个问题。我见过的大多数解决方案都使用递归,而不是DP。 我想我需要一个大小为(n*n*d)的3d布尔表S(I,j,k)。但是S(i,j,k)什么时候为真,什么时候为假?因为我总是需要检查使用k个数计算和的所有可能方法,这些方法既可以是正数,也可以是负数(例如:对于4个数{1,2,3,4},有
-
MongoDB中的数组交集
好吧,这里有几件事。。我有两个集合:test和test1。这两个集合中的文档都有一个数组字段(分别是tags和tags1),其中包含一些标记。我需要找到这些标记的交叉点,如果单个标记匹配,还需要从集合test1获取整个文档。 令人惊讶的是,这并没有返回任何结果。但是,当我尝试使用单个文档时,它是有效的: 但这是我需要的一部分。我也需要交集。所以我尝试了这个: 但它只返回“a”,而“a”和“b”都在
-
Kite数据集图-缩小
https://github.com/kite-sdk/kite/blob/master/kite-data/kite-data-mapreduce/src/test/java/org/kitesdk/data/mapreduce/testmapreduce.java 我的代码段如下 我正在使用HDP2.3.2 box,创建组装jar并通过Spark-Submit提交我的应用程序。 我不明白怎么了
-
Jooq数组作为集合
我想在java中使用集合而不是数组来序列化postgreSQL数组。例如INT[]、varchar(256)[]到java集合和Collection。 SQL: 创建表array_tests(string_array varchar(256)[]); 我在生成的类中出错:
-
比较对象数组集
如果两个集合包含相同的对象,如何进行比较? 当然会打印错误。
-
2.5.2 结果集元数据
在前面讲过,execute、executeQuery和executeUpdate方法都可以返回ResultSet对象。通过ResultSet接口的next方法可以对数据进行扫描,但要获得ResultSet对象的元数据(列数、列名、字段类型等),就需要使用ResultSet接口的getMetaData方法,getMetaData方法的定义如下: ResultSetMetaData getMetaDa
-
定义数据集( Defining Datasets)
数据集名称指定文件的名称,它在JCL中由DSN表示。 DSN参数引用新创建或现有数据集的物理数据集名称。 DSN值可以由1到8个字符长度的子名组成,以句点分隔,总长度为44个字符(字母数字)。 以下是语法: <b>DSN=&name | *.stepname.ddname</b> Temporary datasets仅需要存储作业持续时间,并在作业完成时删除。 此类数据集表示为DSN=&name
-
21. 函数系集的熵
考虑一个各态历经的带限函数系集,最高频率为W个周期/秒。设n个连续采样点的幅度的分布密度函数为: 。将该系集的熵(每自由度)定义为: 。 我们还定义一个熵H(每秒),这次除以的不是n,而是n个采样的持续时间T(单位为秒)。由于,所以有。 当噪声为高斯白色热噪声时,有: . 对于给定平均功率N,白噪声的熵最大。这一点是由上面给出的高斯分布的最大化属性得到的。 连续随机过程的熵有很多与离散情景类似的性