《龙湖集团数字科技》专题
-
java实现阿拉伯数字转汉字数字
本文向大家介绍java实现阿拉伯数字转汉字数字,包括了java实现阿拉伯数字转汉字数字的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了java实现阿拉伯数字转汉字数字的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
 联通数科(Java开发工程师)-11.9
联通数科(Java开发工程师)-11.9全程15分钟,5位面试官,小姐姐挺好看的,嘻嘻嘻! 1、自我介绍 2、问我项目中springcloud中使用的组件 3、问我如何使用nacos和gateway 4、问我如果出现400怎么回事 5、问我另一个项目中redis的定位 6、如何在项目中使用redis的以及相关场景 7、小姐姐问意向地方和目前有那几个offer 完事! #联通数科##Java开发#
-
科特林 lambda 与接口作为参数
我对Koltin lambdas有点困惑,我想知道如何使用它,给出以下代码片段: 以及需要将该接口作为参数传递的函数: 但是,相同的逻辑,但在Java中,按预期编译和运行。 和 在这种情况下,如何在静态编程语言中使用lambda?
-
 Cider跨境电商——数据科学面试
Cider跨境电商——数据科学面试一家正在迅速发展的电商公司,两年竟然融资两轮(好夸张),Hr主打的就是一手能学到很多东西(因为涉及到供应链、商品、用户多个角度),入职后可能需要去一线学习。 一面:(1月31日,数据组同事) 实习中感觉最有趣的一件事 服务分实验的设计流程,实验结果,有没有使用到ABtest,以及ABtest的结果? 实习中遇到的最难的一件事? sql,连接有几种;聚合的方式有几种? python,缺失值处理的方式
-
 【2023暑实】optiver数据科学家 笔试
【2023暑实】optiver数据科学家 笔试投递+约笔:半个月 时长:2h 形势:HackerRank 外企的coding笔试基本上都是用的HackerRank,但题目基本上刷不到只能自己平时多做做题培养coding思维。 一共考了两道编程题,合计两个小时。 Q1:股票分红,输入 股价 分红 时间 输出 现股价 Q2:动物表演,找某个时间房间内的最大动物 题目本身没有涉及到多难的算法,核心难点在于—— 必须是stdin和stdout输入输出
-
 秋招-快手-数据科学家-一面
秋招-快手-数据科学家-一面公司:快手 岗位:数据科学家 形式:视频面试 视频面试平台:轻雀 时长:60分钟 流程: 0、面试官自我介绍及面试流程介绍。 1、自我介绍。 2、对于样本和总体这两个概念,它们之间的关系是什么?它们的差异和相似点分别是什么? 3、了解哪些抽样方法?不同抽样方法分别适用于什么场景? 4、写一下随机
-
 腾讯IEG 数据科学实习面经
腾讯IEG 数据科学实习面经题主背景:对计算机基本上一窍不通的半个数学人。 题主在面试屋外等候时,工作人员问题主昨天是不是来咨询过(昨天校招宣讲),题主点头,工作人员又说,“你的简历我们印象非常深,我们今天主要是偏后台开发的,你先跟后台开发的一起面试,之后有其他部门想要你了我们再推你走哈”,题主此时还没有感受到不妙…… 数据结构:首先提问数据结构,问树的结构掌握哪些,如何用Java实现一个哈希表,链表结构有哪些。 数据库:询
-
 科华数据,嵌入式软件笔试
科华数据,嵌入式软件笔试单选题,60分,多是c语音,电力电子,模电知识。没有太难, 简答题,40分,第一个不会,是自控里面的,画一个方程的伯德图,自控没学好。 第二个手写代码测量50hz,220v交流电的有效值,有一个1ms的回调函数。这个感觉写的一般,采集用的adc,难点是算法,当时脑子瓦了,怎么算有效值忘完了,算法上我直接就是求平均值结果再除根号3,后来又忘了adc采集电压为负的信号结果是多少,只能把311扩展成62
-
 科大讯飞 数据开发 一面 35min
科大讯飞 数据开发 一面 35min1.自我介绍,城市相关 2.你对于大数据哪一块比较了解,展开讲讲 3.结合项目讲数仓建模理论 4.数仓分层的理解和好处,每一层的作用 5.app层如果下面有多个看板,他们有多个指标是重复的,你怎么设计app层才能保证数据查询起来容易又包装数据的一致性呢 6.指标体系的了解 7.原子指标派生指标衍生指标 8.日活留存率怎么算,要得到连续十五天相对于第一天的的留存率,如何优化 9.spark学到什么程
-
 腾讯pcg 数据科学 一面凉经
腾讯pcg 数据科学 一面凉经之前投了多模态方向泡池子泡了大半个月,16号转投数据科学当晚安排面试。 面试过程中感觉还不错,问题基本都答上了,但面试官提过几次说我的科研方向有点偏,还推荐我去另一家企业呃呃了属于是。 希望后续还能被捞上来
-
 科大讯飞一面凉经 | 大数据
科大讯飞一面凉经 | 大数据一面 共 30min 自我介绍 实习经历介绍 项目介绍:数仓分层的理解 为什么用spark而不用hadoop 为什么spark比hadoop快 spark开始计算的标志 java抽象类和接口的区别 对继承和多态的理解 最近有想要学习的新技术吗 #科大讯飞##秋招##大数据#
-
Apache Spark中的数据集
问题内容: 当我仔细观察时,我唯一提出的疑问是: 找不到适用于实际参数“ org.apache.spark.unsafe.types.UTF8String”的适用构造函数/方法;候选者为:“ public void sparkSQL.Tweet.setId(long)” 问题答案: 正如@ user9718686所写,id字段具有不同的类型:在json文件和类定义中。当您将其读入时,Spark会从
-
Python-解析JSON数据集
问题内容: 我正在尝试解析看起来像这样的JSON数据集: 假设可以有许多这样的数据集。 我想遍历它们中的每一个并获取“名称”和“广告系列ID”参数。 到目前为止,我的代码看起来像这样: 可能挺简单的!我对列表/字典不好:( 问题答案: 使用或(提供默认值)访问词典: 我建议你读一些有关字典的东西。
-
spark数据集的变换
我在RDBMS中有几个数据库表,在当前的逻辑中,所有这些表都被连接起来并给出一些数据,基本上SQL被存储为视图的一部分。使用sqoop将数据推送到HDFS中,需要应用一些分组和按操作排序。 什么可能是连接数据集的最佳方式,如转储所需的列到内存(如df.registeredTempTable())和应用连接,或者我可以使用数据集连接,因为数据在HDFS的不同文件中可用。 问候阿南
-
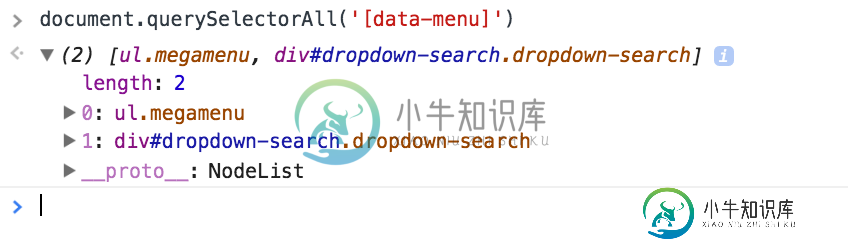 数据集和Internet Explorer 11
数据集和Internet Explorer 11在Internet Explorer中使用似乎有问题。 获取此错误 无法获取未定义或空引用的属性“menu” 我得到以下信息: 但是,如果我在Internet Explorer 11中运行相同的命令: 它似乎找到了2属性,但是没有列出它们,所以NodeList是空的,因此我的错误。