《群面》专题
-
 腾讯CSIG 云与智慧产业事业群产品运营 三四面面经
腾讯CSIG 云与智慧产业事业群产品运营 三四面面经三面 1.自我介绍 2.相关实习的主要工作任务? 3.有什么收获和启发? 4.如何理解产品运营的工作? 5.用户运营的职责和意义? 6.对于未来的规划? 7.认为自己做的比较好的运营案例? 8.对产品的了解如何?认为有什么比较好的地方和不足? 9.反问环节 -部门组织架构,入职后负责的方向? -实习生的培养计划? -面试的反馈? HR面 1.自我介绍 2.介绍以往的实习经历 3.对于产品经理的理解
-
 吃水不忘挖井人:蚂蚁集团国际事业群Alipay+产品面经
吃水不忘挖井人:蚂蚁集团国际事业群Alipay+产品面经写在前面: 我的整个求职过程是从2021年7月开始的,工作是2022年5月定下来的,一路下来非常坎坷,从牛客上看了很多面经,也亲身经历了互联网寒冬,想到今年求职只会更严酷所以想把自己的SB求职经历和大家分享一下,希望能给到求职崩溃的学弟学妹们一点点心理安慰,顺便把去年就写好了的面经再反哺回牛客这个社区吧,不需要心理安慰看面经的直接从分界线看就好。(又名《一个不了解国内招聘市场的“水硕”第一人称求职
-
 腾讯 光子工作室群 游戏客户端开发 实习 一面 凉经
腾讯 光子工作室群 游戏客户端开发 实习 一面 凉经展示一下项目。 path tracing的思路。 重要性采样。 对面光源的采样和其他光源一样吗(盲猜是问有没有用LTC)。 了解PBR吗(我把微表面brdf和Disney principled BRDF都讲了一下)。 lambert材质的BRDF是ρ/pi,为什么要除这个pi呢。 项目用了什么加速方法(BVH)。 怎么去划分BVH。 BVH和kd树的对比。 有用到俄罗斯轮盘赌吗?有什么缺点。 用过
-
Mongodb atlas专用集群:如何与AWS建立对等连接,然后访问集群而不必将IP列入白名单
我们在Mongodb Atlas中有一个专用的M10集群,我在该集群上创建了一个与AWS的对等连接,以使用VPC实现安全性。我遵循了这个Mongodb文档来配置AWS和集群之间的对等连接。 https://docs.atlas.mongodb.com/security-vpc-peering/ 对等连接已成功创建,现在处于活动状态。但问题是,如果不将我的IP列入白名单,我就无法连接到集群。当我尝试
-
Quartz调度程序:在每个集群节点上触发一些作业,而有些作业每个集群只触发一次
我有一些用@NotConcurrent注释的作业,它们每个集群运行一次(即,只在一个节点中,只在一个线程中)。 现在我需要在集群的每个节点上运行一个作业。我删除了@NotConcurrent注释,但它只在一台机器上的每个线程上运行。它不会在其他节点上被激发。 我应该用什么来注释这份工作?
-
简单注解实现集群同步锁(spring+redis+注解)
本文向大家介绍简单注解实现集群同步锁(spring+redis+注解),包括了简单注解实现集群同步锁(spring+redis+注解)的使用技巧和注意事项,需要的朋友参考一下 互联网面试的时候,是不是面试官常问一个问题如何保证集群环境下数据操作并发问题,常用的synchronized肯定是无法满足了,或许你可以借助for update对数据加锁。本文的最终解决方式你只要在方法上加一个@P4jSyn
-
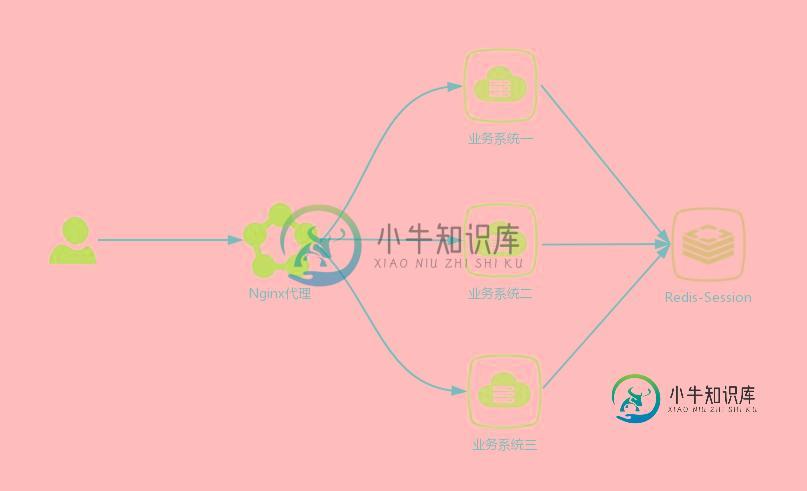 SpringBoot开发案例 分布式集群共享Session详解
SpringBoot开发案例 分布式集群共享Session详解本文向大家介绍SpringBoot开发案例 分布式集群共享Session详解,包括了SpringBoot开发案例 分布式集群共享Session详解的使用技巧和注意事项,需要的朋友参考一下 前言 在分布式系统中,为了提升系统性能,通常会对单体项目进行拆分,分解成多个基于功能的微服务,如果有条件,可能还会对单个微服务进行水平扩展,保证服务高可用。 那么问题来了,如果使用传统管理 Session 的方式
-
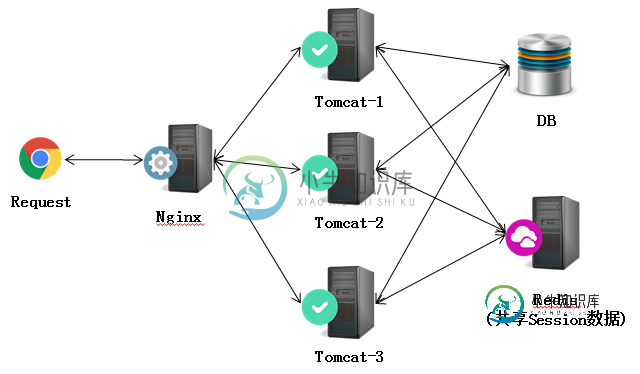 Nginx+Tomcat高性能负载均衡集群搭建教程
Nginx+Tomcat高性能负载均衡集群搭建教程本文向大家介绍Nginx+Tomcat高性能负载均衡集群搭建教程,包括了Nginx+Tomcat高性能负载均衡集群搭建教程的使用技巧和注意事项,需要的朋友参考一下 Nginx是一个高性能的HTTP服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其占有内存少,并发能力强,在同类型的网页服务器中表现较好。Nginx可以在大多数Unix Linux OS上编译运行,并有Windows移
-
Linux修改用户(群组)的磁盘配额(edquota命令)
针对用户和群组的配额限制(Quota),不仅可以手动控制开启和关闭,还可以手动修改配额参数,即使用 edquota 命令。 edquota 命令,是 edit quota 缩写,用于修改用户和群组的配额限制参数,包括磁盘容量和文件个数限制、软限制和硬限制值、宽限时间,该命令的基本格式有以下 3 种: [root@localhost ~]# edquota [-u 用户名] [-g 群组名] [ro
-
从HDInsight集群头节点运行火花应用程序
我正在尝试使用命令从 azure HDInsight 群集的头节点运行火花 scala 应用程序 类com.test.spark.WordCountSparkJob1.jarwasbs 我正在接受它的异常。 导致原因:java.lang.ClassCastExc的:不能分配scala.collection.immutable.列表的实例$序列化代理字段org.apache.spark.rdd.RD
-
如何为集群外的查询公开kube-dns服务?
以前有人试图公开kube-dns服务吗?如果有,有没有其他的安装步骤或者你有什么调试建议给我? 服务定义如下:
-
可以kafka连接-mongo源作为集群运行(max.tasks>1)
我使用的是kafka connect支持的以下mongo源代码。我发现mongo源代码的一个配置(从这里)是tasks.max。 这意味着我可以提供连接器tasks.max这是 如果它将创建多个连接器来侦听mongoDb更改流,那么我将最终得到重复的消息。那么,mongo真的具有并行性并作为集群工作吗?如果它有超过1个tasks.max?
-
Kafka连接集群设置或启动连接工作者
我正在浏览Kafka连接,我试图得到一些概念。 假设我有kafka集群(节点k1、k2和k3)设置并且正在运行,现在我想在不同的节点上运行kafka连接工作器,比如分布式模式下的c1和c2。 很少有问题。 1) 要在分布式模式下运行或启动kafka connect,我需要使用命令,这在kaffa集群节点中可用,所以我需要从任何一个kafka集群节点启动kafka连接?或者我启动kafka conn
-
2.6.1 集群部署时的分布式 Session 如何实现?
面试题 集群部署时的分布式 session 如何实现? 面试官心理分析 面试官问了你一堆 dubbo 是怎么玩儿的,你会玩儿 dubbo 就可以把单块系统弄成分布式系统,然后分布式之后接踵而来的就是一堆问题,最大的问题就是分布式事务、接口幂等性、分布式锁,还有最后一个就是分布式 session。 当然了,分布式系统中的问题何止这么一点,非常之多,复杂度很高,这里只是说一下常见的几个问题,也是面试的
-
第一部分:常用操作 - 11. 修改集群配置
启动 Ceph 存储集群时,各守护进程都从同一个配置文件(即默认的 ceph.conf )里查找它自己的配置。ceph.conf 中可配置参数很多,有时我们需要根据实际环境对某些参数进行修改。 修改的方式分为两种:直接修改 ceph.conf 配置文件中的参数值,修改完后需要重启 Ceph 进程才能生效。或在运行中动态地进行参数调整,无需重启进程。 11.1 查看运行时配置 如果你的 Ceph 存