《群面》专题
-
JBPM群集:jbpm-console.war未在第二个节点上部署
我正在尝试构建一个以mysql为DB的JBPM6.5集群。我正在使用Zookeeper-3.4.10 Helix-Core-0.6.8 我正在通过以下步骤创建安装程序 ./bin/helix-admin.sh--zksvr localhost:2181,localhost:2182,localhost:2183--addnode jbpm-domain-cluster server-two:123
-
为什么要运行消息队列(例如RabbitMQ)集群?
你为什么要这么做?我理解增加消息的持久性(如果一个节点关闭,其他队列仍然获得消息)。但是性能呢?集群如何提高性能。难道所有的消费者/生产者都不会连接到主节点的队列吗?如果是这样,我们不是仍然在单个节点上获得流量吗?我们是否设置了负载均衡器,使得流量每次都指向不同的节点? RabbitMQ集群如何提高性能?
-
多重Kafka——Spring Boot多重Kafka集群中的消费者
想要从使用的Spring启动应用程序的不同集群上创建同质。 即想要为已经定义的类创建一个 Kafka Consumer 对象,该对象侦听动态定义的多个集群。 例如:假设一个Spring启动应用程序S,其中包含kafkaconsumer的
-
关于在集群(AWS)上运行spark作业的说明
我有一个在AWS EC2机器上运行的HortonWorks集群,我想在上面运行一个使用spark streaming的spark工作,该工作将吞下tweet concernings《权力的游戏》。在尝试在集群上运行它之前,我确实在本地运行了它。代码正在工作,如下所示: 我的问题更确切地说是关于这段特定代码行: 17/07/24 11:53:42 INFO AppClient$ClientEndpo
-
未绑定到浮动IP的Spark群集主IP地址
null 当我尝试使用这些浮动IPs和标准公共IPs时,我遇到了问题。 在spark-master计算机上,主机名为spark-master,/etc/hosts类似于 对spark-env.sh所做的唯一更改是。如果我运行,我可以查看web UI。 您的主机名spark-master解析为环回地址:127.0.1.1;使用192.x.x.1代替(在接口eth0)16/05/12 15:05:33
-
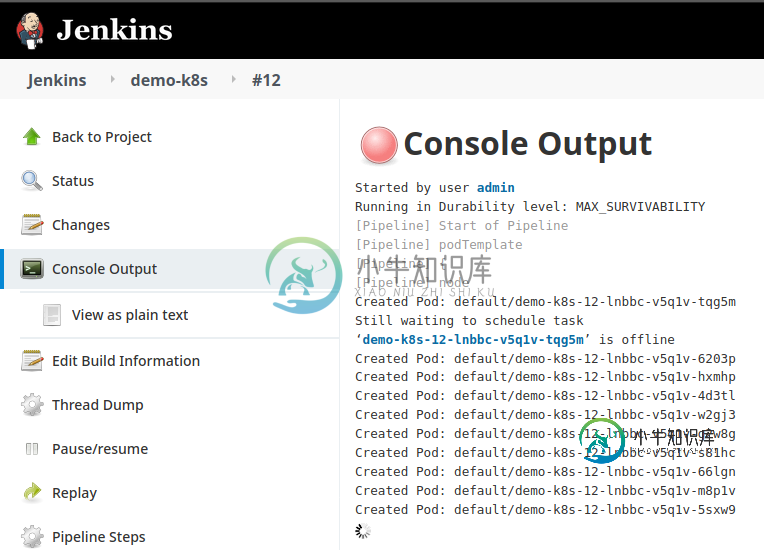 Jenkins管道作业继续在kubernetes集群内创建pod
Jenkins管道作业继续在kubernetes集群内创建pod最近我一直试图在詹金斯内部建立一个管道。目标是创建一个pod并执行kubernetes部署。 但是当我运行管道作业时,它会一个接一个地创建pod,它永远不会完成作业- 设置kubernetes集群-成功 安装jenkins-成功 连接jenkins到kubernetes集群-成功 这是管道脚本- 不-Pods创建成功,kubernetes部署也成功,但jenins管道从未停止。 我的jenkins
-
创建运行在多个docker容器上的HazelCast集群
有没有人知道,如果我们想在运行在多个docker容器上的Hazelcast实例之间形成Hazelcast集群,那么需要在Hazelcast.xml中进行哪些配置。我们应该提供127.0.0.1作为成员的地址还是应该提供docker主机的地址?Local.LocalAddress属性是否需要指向docker主机地址? 编辑:
-
Akka集群单例创业的正确道路是什么
null 我看到“singleton actor总是在具有指定角色的最老成员上运行。”在Akka集群中,单例Doc。但我不明白singleton是怎么开始的。也许所有的单例都必须在第一个种子节点中实现和启动?
-
跨不同openshift集群的应用程序吊舱部署
我在俄亥俄州的一个AWS地区安装了OpenShift3.9。我把詹金斯装在里面了。我有一个管道代码,它将从GitHub中获取Java代码,并将其与jboss绑定,并将其部署在同一个集群中的项目测试中。它工作得很好,我能够访问应用程序,因为pod正在创建,应用程序也与JBoss绑定。现在我想跨不同的集群部署这个应用程序,可以在同一区域内部署,也可以跨不同的区域部署。有没有办法做到这一点?
-
Flink-Query Kafka主题用于消费者群体的偏移?
我有一个用例,其中数据将从kafkaTopic1流入程序(我们称之为P1),经过处理,然后持久化到数据库。P1将在一个多节点集群上,因此每个节点将处理大量的kafka分区(假设本主题有5个节点和50个kafka分区)。如果其中一个节点由于任何原因完全失败,并且有数据正在处理,那么该数据将丢失。 例如,如果kafkaTopic1上有500条消息,node2拉出了10条消息(因此根据偏移量要拉出的下一
-
使用Kubeadm创建高可用性Kubernetes集群时出错
我正在使用kubeadm在VM中创建Kubernetes集群(我在VM中使用的映像是CentOS 7 CIS Hardened)。 我正在遵循这个用Kubeadm创建高可用性集群的官方文档 到目前为止我已经完成的步骤: 将这些值更改为1而不是0 回声 1 禁用交换:swapoff-a sed-e'/swapoff/s/^#*/#/' -i /etc/fstab挂载-a 这样做之后,我创建了一个名为
-
无法让跺脚接受器在野蝇群中运行
AMQ222203:类路径缺少协议STOMP的协议管理器,在acceptor TransportConfiguration(name=stomp-acceptor,factory=org-apache-activemq-artemis-core-remoting-impl-netty-nettyAcceptorFactory)上忽略了协议?port=61613&protocols=STOMP 我使
-
删除《动物园管理员》中的Kafka消费群体
我将Kafka2.9.2-0.8.1.1与zookeeper 3.4.6一起使用。 是否有一个实用程序可以自动从Zookeeper中删除一个消费者组?或者我可以删除zookeeper中/consumers/[group_id]下的所有内容吗?如果是后者,我还缺少什么吗&这可以用一个动态系统来完成吗? 更新:从kafka 2.3.0版本开始,有一个新的实用程序: 相关文档:http://kafka.
-
Apache Artemis:如何为静态集群创建持久订阅
这里是clustered-stability-subscription的示例,这里是clustered-static-discovery的示例,其中clustered-static-discovery只与一台服务器连接(使用集群配置,集群自动与另一台服务器连接)。根据文档 通常,持久订阅存在于单个节点上,并且在任何时候只能有一个订阅者,但是,使用ActiveMQ Artemis,可以在集群的不同节
-
在多节点群集中跨H2O节点分配资源
我有 2 个 docker 容器运行我的 Web 应用程序和机器学习应用程序,都使用 h2o。最初,我既调用 h2o.init() 又指向同一个 IP:PORT,因此初始化了一个具有一个节点的 h2o 集群。 考虑到我已经训练了一个模型,现在我正在训练第二个模型。在此训练过程中,如果web应用程序调用h2o集群(例如,从第一个模型请求预测),它将终止训练过程(错误消息如下),这是无意的。我尝试为每