《烽火通信》专题
-
防火墙背后的Apache背后的Tomcat:AJP忽略X-Forwarded-Proto
防火墙:终止https,添加“x-forwarded-proto:https”,通过http转发到Apache Apache:通过ajp转发到Tomcat Tomcat:通过ajp-connector接收请求 我们已经将RemoteIpValve添加到Tomcat的server.xml中: 如果我们跳过Apache,直接从防火墙转到使用常规HTTP连接器的Tomcat,它就可以工作。在这种情况下,
-
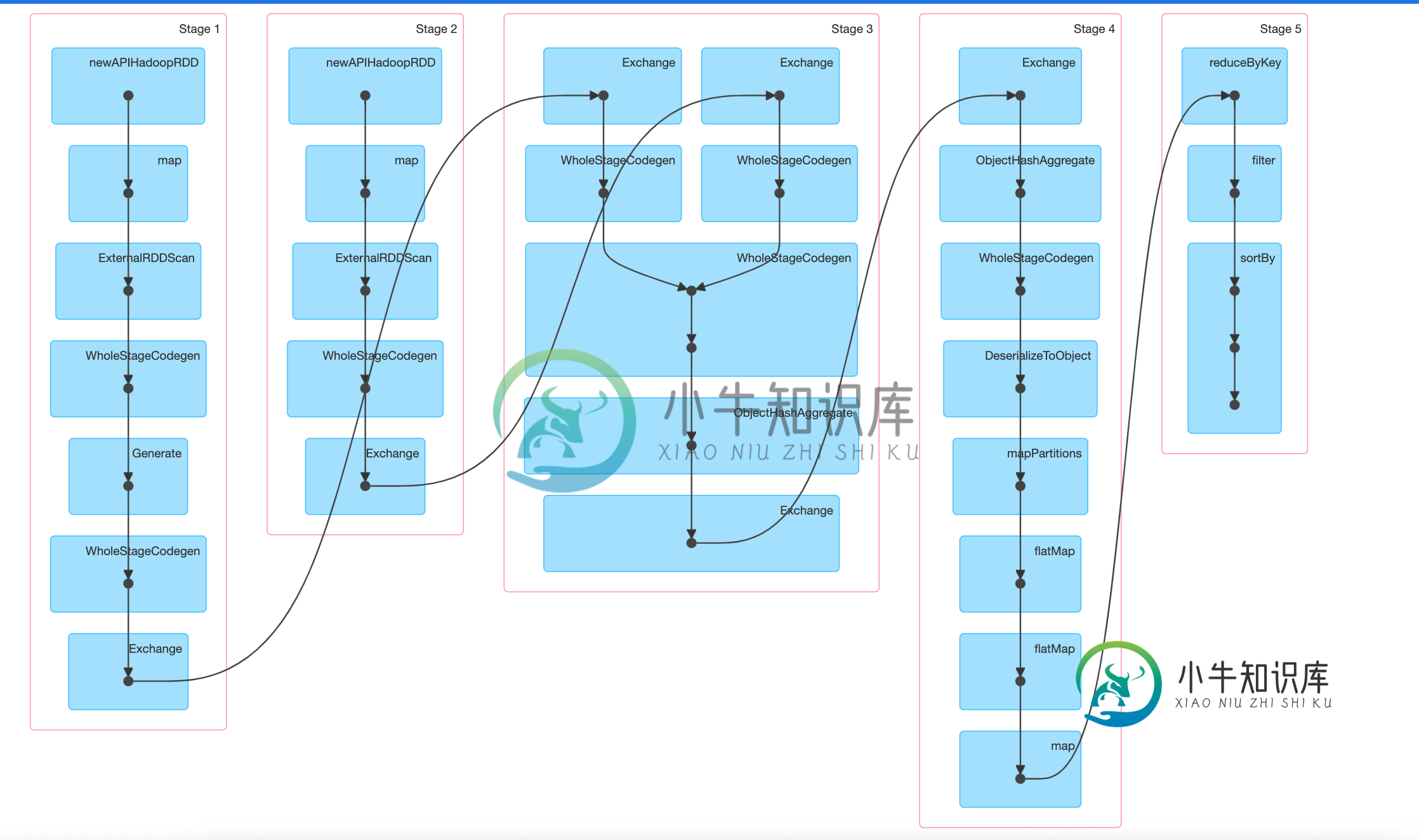 连接后在各阶段之间卡住的火花作业
连接后在各阶段之间卡住的火花作业我有一个spark作业,它连接2个数据集,执行一些转换,并减少数据以给出输出。现在的输入大小相当小(每个200MB数据集),但是在join之后,正如您在DAG中所看到的,作业会被卡住,并且不会继续进行第4阶段。我试着等了几个小时,它给了OOM并显示了第四阶段的失败任务。 为什么spark在stage-3(连接阶段)之后不显示stage-4(数据转换阶段)为活动的?它是不是在第3阶段和第4阶段之间徘
-
如果否,如何处理火花RDD分区。执行者数
我想了解火花流中的一个基本的东西。我有50个Kafka主题分区和5个执行者的数字,我正在使用DirectAPI所以没有。的RDD分区将为50个。这个分区将如何在5个执行器上处理?将在每个执行器上一次触发进程1个分区,或者如果执行器有足够的内存和内核,它将在每个执行器上并行处理超过1个分区。
-
火狐浏览器打开后一秒关闭,忽略场景
我的控制台: RG.OpenQA.Selenium.Remote.UnreachableBrowserException:无法启动新会话。可能的原因是远程服务器地址无效或浏览器启动失败。生成信息:版本:“3.4.0”,修订版:“Unknown”,时间:“Unknown”系统信息:主机:“WS00MU016”,IP:“”,OS.Name:“Windows 10”,OS.ARCH:“AMD64”,OS
-
 如何比较火库颤振应用中的两个集合?
如何比较火库颤振应用中的两个集合? -
日食火星太慢了。总是忙于扫描类路径
我正在使用eclipse mars 4.5。问题是,它总是忙于扫描类路径,这实际上使eclipse的工作速度太慢。我正在处理多模块OSGI项目,因此工作区中大约有30个项目,eclipse每次都开始扫描所有项目的类路径。
-
验证后角度火灾库电子邮件验证错误
我正在用电子邮件和密码设置授权功能。一切正常,但当我创建一个新用户时,应用程序会发送一封带有验证链接的电子邮件。在我验证电子邮件地址后,我想登录,因此我返回登录表单。在我硬重新加载页面后,emial_。有人能帮我吗?
-
石英下次点火时间还是上次触发时间?
我正在使用Quartz和Spring来安排工作。我有一份按计划每小时运行的工作。问题是,当计划的作业耗时超过一小时时,该作业的“下一次启动时间”仍然是旧时间,不会启动(因为启动时间已经过去)。 我的问题是,如果工作时间超过预定时间,我们如何更改“下一次点火时间”?
-
阿拉莫火挑战委托和逃避关闭的问题
我正在使用AF并使用它的委托来捕获我的服务器返回的身份验证质询。 我的问题: > 如果我按原样使用上面的代码,我会 错误:“将非转义参数'completionHander'传递给需要@escaping闭包的函数” 如果我使函数handleAuthenticationSession的参数不转义,我会得到: 错误:“使用非转义参数“completion”可能会使其转义” 此外,AuthHandler类
-
Google Cloud Dataproc最后阶段作业失败引发的火花
我在Dataproc上使用Spark集群,但我的作业在处理结束时失败了。 我的数据源是Google Cloud Storage上csv格式的文本日志文件(总量为3.5TB,5000个文件)。 处理逻辑如下: 将文件读到DataFrame(模式[“timestamp”,“message”]); 将所有邮件分组到1秒的窗口中; 对每个分组消息应用管道[tokenizer->HashingTF]以提取单
-
Flutter-错误后包括云火力恢复依赖。[已解决]
我想要一个帮助来解决这个问题。在pubspec中插入cloudfirestore依赖项后,我无法构建flutter应用程序。亚马尔 错误说明: 失败:构建失败,有一个异常。 错误:无法确定任务“:app:compiledBugJavaWithJavaC”的依赖项。无法解析配置“:app:debugCompileClasspath”的所有任务依赖项。无法解析io。grpc:grpc核心:[1.21.
-
数组代码点火器从数据库中提取结果
我有一个食物表,在那里我存储分类ID作为coma分开,如下面的图像食物表 我在模型中做了一个方法,它以数组(类别ID)为参数,从参数中获取与数组ID匹配的食物项。 我做了以下查询 下面是上面查询的结果 我得到了重复的结果,我认为这也可能导致性能问题。 以下是当我只有一个类别的食物给我期望的结果时的查询。 请帮帮忙。
-
火花驱动器和执行器在同一台机器上
在EMR集群或任何集群中,YARN有可能在同一个EC2实例中分配驱动程序和执行器吗?我想知道驱动程序是否可以利用1个EC2实例的存储和处理能力,或者该实例的某个部分将用于服务集群中运行的其他spark作业。这可能会导致我的驱动程序内存不足。 我认为资源管理器是根据集群资源的可用性来决定的?
-
火花聚结与执行器和核心数量的关系
我提出了一个关于Spark的非常愚蠢的问题,因为我想澄清我的困惑。我对Spark非常陌生,仍在努力理解它在内部是如何工作的。 比方说,如果我有一个输入文件列表(假设1000),我想在某个地方处理或写入,并且我想使用coalesce将我的分区数减少到100。 现在我用12个执行器运行这个作业,每个执行器有5个内核,这意味着它运行时有60个任务。这是否意味着,每个任务将在一个单独的分区上独立工作? 回
-
阿帕奇火花-卡桑德拉番石榴不亲和性
我正在用SparkMaster api 7077执行JettyRun和ClusterMode。我将cassandra驱动程序和spark-cassandra连接器的jar传递给spark conf(setjar) 有些时候,如果我重新启动,它是有效的,但有几次,我不得不尝试和尝试,从来没有工作。 我尝试了一些答案,比如将Spark番石榴罐子重命名为19版本,但总是遇到同样的问题。 怎么回事?