
如何比较火库颤振应用中的两个集合?

共有1个答案

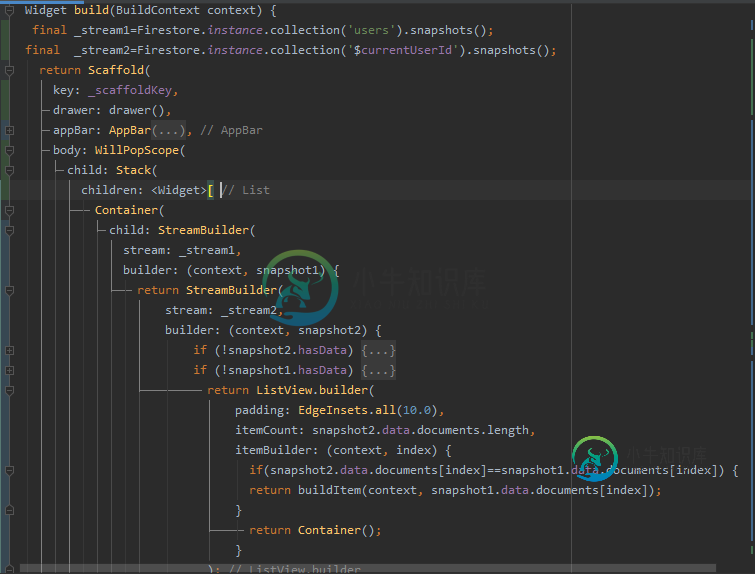
我不太确定您想用代码中的< code>==做什么(因为< code>DocumentReference在不同的集合中会有所不同),但是如果您想将这两个流连接在一起,可以看看RxDart的combineLatest2,它允许您用另外两个流的最新元素获得一个新的流。
另外,我不确定调用snapsnaps.data.documents是否保证按排序顺序为您提供文档;因此,在这种情况下,调用 [index] 可能不会执行您想要的操作。
我想注意的一件事:您构建数据的方式似乎相当奇怪——为什么不将所有用户数据放在用户集合下?
-
我只是实现了自己的插入排序,并试图验证功能,包括稳定性。 对于给定的未排序元素列表,我试图根据collections#sort(list)方法验证我的代码。 我找到了AbstractiterAbleAssert#ContainsExactlYelementsOf方法。 最后,我将方法跟踪到调用的位置。 方法是否覆盖稳定性? 或者,对于是否应该添加其他方法?
-
问题内容: 当给出两套时 s1 = {a,b,c,d} s2 = {b,c,d,a} (IE) 如何编写Sql查询以显示“ tableA和tableB中的元素相等”。[不使用SP或UDF] 输出 问题答案: 使用: 测试:
-
问题内容: 我有两个。每个大小为100000。我想比较它们并计算匹配的元素。 这是我的代码: 在这里比较过程要花费很多时间。 如何解决和优化此问题。 问题答案: 您应该使用:返回一个包含collection1中所有元素的集合,这些元素也处于collection2中。
-
我想比较两个jbyteArray如果在JNI中相等的话。有没有像“strcmp”这样的方法?
-
在调试模式下启动SM A105F上的lib\main.dart...正在运行分级任务“组装调试”...√build build\app\outputs\flutter-apk\app-debug.apk。正在安装build\app\outputs\flutter-apk\app.apk...错误:ADB退出,退出代码为1执行流式安装