《烽火通信》专题
-
司机命令停车后,火花工人停了下来
-
如何设置默认的火花日志记录级别?
我将pyspark应用程序从我自己的工作站上的pycharm启动到一个8节点集群。这个群集还有编码在spark-defaults.conf和spark-env.sh中的设置 显示未来的信息消息,但到那时已经太晚了。 如何设置spark开始时的默认日志记录级别?
-
火花:IllegalArgumentException:“不受支持的类文件主版本55”
运行时遇到错误,我尝试了Pyspark error-Unsupported class file major version 55和Pyspark.topandas():'Unsupported class file major version 55'中提到的解决方案,但没有成功。 完整错误日志:
-
在Scala火花数据帧DSL API中使用Scal-sql UDF
如何在火花scala数据帧(非文本)api中访问geomesas UDF?即如何转换 如何使sql UDF在scala数据帧DSL中的文本spark sql API中可用?即如何启用而不是此表达式 类似于 如何注册Geomesa UDF,使其不仅适用于sql文本模式<代码>SQLTypes。init(spark.sqlContext)fromhttps://github.com/locationt
-
如何使用orderby()与降序在火花窗口函数?
我需要一个窗口函数,该函数按一些键(=列名)进行分区,按另一个列名排序,并返回排名前x的行。 这适用于升序: 但当我试图在第4行中将其更改为或时,我得到了一个语法错误。这里的正确语法是什么?
-
火花SQL:选择与算术列值和类型转换?
我将Spark SQL用于数据帧。有没有一种方法可以像在SQL中一样,使用一些算术来执行select语句? 例如,我有以下表格: 现在,我想用SELECT语句创建一个新列,并对现有列执行一些算术运算。例如,我想计算比率。我需要先把价值(或年数)转换成双倍。我试过这句话,但无法解析: 我在“如何在Spark SQL的DataFrame中更改列类型?”中看到了类似的问题,但这不是我想要的。
-
火花SQL:如何使用JAVA从DataFrame操作调用UDF
我想知道如何使用JAVA从SparkSQL中的领域特定语言(DSL)函数调用UDF函数。 我有UDF函数(仅举例): 我已经注册到sqlContext了 当我运行下面的查询时,我的UDF被调用,我得到一个结果。 我将使用Spark SQL中特定于域的语言的函数转换此查询,但我不确定如何进行转换。 我发现存在调用 UDF() 函数,其中其参数之一是函数 fnctn 而不是 UDF2。如何使用 UDF
-
如何使用 JAVA 在火花数据帧上调用 UDF?
类似的问题,但没有足够的观点来评论。 根据最新的Spark文档,< code>udf有两种不同的用法,一种用于SQL,另一种用于DataFrame。我找到了许多关于如何在sql中使用< code>udf的例子,但是还没有找到任何关于如何在数据帧中直接使用< code>udf的例子。 o.p.针对上述问题提供的解决方案使用,这是,将根据Spark Java API文档在Spark 2.0中删除。在那
-
如何限制火库存储图像的数量?[重复]
我创建这段代码是为了限制存储在那里的项目数量,但是我仍然可以添加任意多的新图像。
-
 硒/火狐:命令“.click()”不适用于找到的元素
硒/火狐:命令“.click()”不适用于找到的元素我试图找到解决这个问题的方法,我花了很多时间,但这对我来说几乎是不可能的。 问题:我在Firefox中使用Selenium和Java。我需要找到一个元素(列表框)并点击它。因此,代码找到元素,但单击操作不起作用。它在Google Chrome中每次都能很好地工作,只是有时在Firefox中(使用相同的Java代码有时工作,有时不工作)。 当程序进入页面时,有一部分代码包含元素: 还有一部分代码在单
-
如何允许NFC意图在某些活动上开火?
在我的应用程序中,我只有一个具有NFC意图的活动,但它仍然在所有其他活动中触发。有没有办法限制这种情况? 我想模仿NFC TagInfo处理其NFC意图的方式。他们只允许NFC读取他们的“扫描标签…”活动,并在所有其他活动中被阻止。
-
错误没有找到值火花导入spark.implicits._导入spark.sql
我使用hadoop 2.7.2,hbase 1.4.9,火花2.2.0,scala 2.11.8和java 1.8的hadoop集群是由一个主和两个从。 当我在启动集群后运行spark shell时,它工作正常。我正试图通过以下教程使用scala连接到hbase:[https://www.youtube.com/watch?v=gGwB0kCcdu0][1] . 但当我试图像他那样通过添加那些类似
-
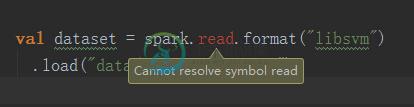 value read不是组织的成员。阿帕奇。火花SparkContext
value read不是组织的成员。阿帕奇。火花SparkContextscala的版本是2.11.8;jdk为1.8;spark是2.0.2 我试图在spark apache的官方网站上运行一个LDA模型的示例,我从以下句子中得到了错误消息: 错误按摩是: 错误:(49,25)读取的值不是组织的成员。阿帕奇。火花SparkContext val dataset=spark。阅读格式(“libsvm”)^ 我不知道怎么解决。
-
App Engine Flex的默认VPC防火墙规则是什么
null
-
云火库合并 true 在节点JS中不起作用
在firestore文档中,它说如果我们想合并数据,就需要,但它不起作用 这是我的代码,与示例非常相似,它总是用新值替换旧的存储值 我真的需要它,如果你有一个解决方案请