《吐槽》专题
-
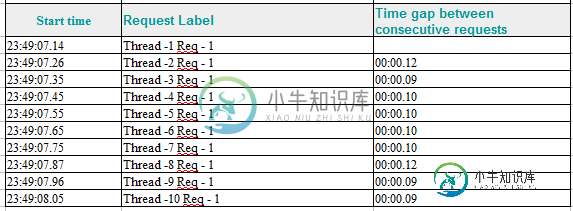 Jmeter中的恒定吞吐量计时器是如何工作的?
Jmeter中的恒定吞吐量计时器是如何工作的?如何计算请求之间的延迟。我有一个简单的Jmeter脚本,包含以下4个组件: > 线程组-线程数设置为10,重置其他字段有缺省值。 Http采样器-名为Thread-${uuuuThreadNum}Req-${uuuuu计数器(TRUE)}点击URL-google。公司 恒定吞吐量计时器:目标吞吐量-60,计算所有活动线程的吞吐量。 在表侦听器中查看结果。 请解释如何计算请求之间的延迟和要创建的请求
-
仅用于一个线程组的吞吐量成形计时器
我有一个JMeter测试计划,其中包含具有不同工作负载和吞吐量的多个线程组。我想使用吞吐量成形计时器,但只对一个线程组应用成形。如果我在线程组中有计时器,它似乎仍然作用于整个测试计划。 例如,如果我将其设置为每秒6个请求,并运行测试10分钟,则在“查看结果”树中会得到3600个条目(这是预期的)。不幸的是,这3600个条目包括来自其他线程组的请求。我希望只从这个线程组中获得3600个条目,然后从其
-
 【面试】Spring事务面试考点吐血整理(建议珍藏)
【面试】Spring事务面试考点吐血整理(建议珍藏)本文向大家介绍【面试】Spring事务面试考点吐血整理(建议珍藏),包括了【面试】Spring事务面试考点吐血整理(建议珍藏)的使用技巧和注意事项,需要的朋友参考一下 Starting from a joke 问:把大象放冰箱里,分几步? 答:三步啊,第一、把冰箱门打开,第二、把大象放进去,第三、把冰箱门带上。 问:实现Spring事务,分几步? 答:三步啊,第一、找出需要事务的方法,第二、把事务
-
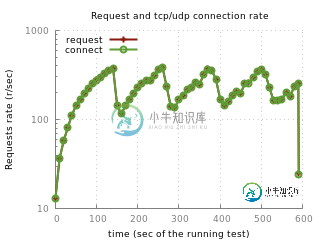 nginx反向代理吞吐量周期性下降,会是什么?
nginx反向代理吞吐量周期性下降,会是什么?这是使用的nginx配置。所有被评论的东西都被尝试过,没有任何影响。我还使用了worker_connections的值和相关的东西。这种周期性下降是由什么引发的?
-
用于更改cosmosDB吞吐量的Powershell脚本给出401错误
我试图使用powershell来改变cosmosDB的吞吐量 当我运行下面的脚本时,它给我这个错误,但之后它工作正常 获取令牌请求返回超文本传输协议错误: 401和服务器响应:{"错误":"invalid_client","error_description":"AADSTS50012:提供了无效的客户端机密。\r\n跟踪ID: GUID\r\n相关ID: GUID\r\n时间戳: 2019-01
-
响应时间好/低,但吞吐量也显示低Jmeter结果
用户:100 平均Res:2.4秒 吞吐量:10/分钟 错误%:0 通过关闭所有监听器,在非GUI模式下运行测试。Jmeter实例和应用服务器的CPU、内存利用率良好。不超过30%的使用率。
-
Libgdx V1.3.1飞溅屏幕吐温错误:线程中的异常"LWJGL应用程序"java.lang.运行时异常:没有找到目标的吐温访问器
在我的android、桌面和html libgdx项目中,我很难实现Universal Tween引擎(请注意,这是使用gradle的libgdx版本1.3.1的一个问题)。我按照github wiki上的说明,使用了下面链接中显示的fileTree方法。https://github.com/libgdx/libgdx/wiki/Universal-Tween-Engine 我设法将核心和ANDR
-
Jmetm:每五分钟更改一次恒定吞吐量定时器值
在JMETER中: http://jmeter.apache.org/usermanual/component_reference.html#Constant_Throughput_Timer 它提到,可以使用
-
吞吐量值是否与JMeter中请求的响应时间有关?
我得到了以下结果,吞吐量没有变化,即使我增加了线程数。 场景#1: 线程数:10 加速期:60 吞吐量:5.8/s 平均值:4025 场景#2: 线程数:20 加速期:60 吞吐量:7.8/s 平均值:5098 场景#3: 线程数:40 加速期:60 吞吐量:6.8/s 平均: 4098 我的JMeter文件包含一个单一的ThreadGroup,其中包含一个GET。 当我执行对响应时间更快(小于3
-
如何计算大型no.of线程的响应时间和吞吐量
给出了jmeter为10个线程生成的摘要报告(并发请求)。 我们能否从我们为10个用户获得的报告中计算并找到50个线程的响应时间和吞吐量。我必须运行负载测试的Restapi触发电子邮件和短信通知。我想知道他们是否有办法找到大约50个线程的响应时间和吞吐量,如果我们有10个线程的报告。
-
Jmeter和吞吐量成形计时器-在一个脚本中多次
我有一个带有七个线程组的巨大脚本。我使用了Conccurency线程组和吞吐量整形计时器。我有两个问题: 我是否可以将吞吐量成形计时器中的值与点一起使用,例如,开始RPS:0.01,结束RPS:0.3 如何在CTG中多次使用吞吐量成形计时器?例如:我有10个步骤。前5步的RPS应为0.5到2(阶梯式),第6步和第7步的RPS应为0.3到0.8,最后一步的RPS应为0.1到0.4。我想使用比例-我的
-
让JMeter使用吞吐量整形计时器和并发线程组
我正在尝试构建一个JMeter测试,包括一个并发线程组和一个吞吐量成形计时器,如这里和这里所述。计时器配置为运行10个斜坡和阶段,RPS从1到333。我想将并发线程组设置为使用调度反馈函数,并在目标并发字段中添加了公式(我已将示例从tst名称更新为实际计时器名称)。如果吞吐量是由计时器管理的,则我假设属性没有那么重要,因此我将爬升时间和步长设置为1;保持目标速率时间为8000,比计时器中添加的步长
-
是min.insync。副本配置会影响Kafka生产商的吞吐量吗?
来自Kafka文献 当制作人将ACK设置为“all”(或“-1”)时,此min.insync。副本配置指定必须确认写入才能被视为成功写入的最小副本数。 它表示当同步副本的最小数量确认时,写入成功,但当我使用为1和3(对于5个代理设置中的分区=1和R.F=5的主题),带有的kafka producer的性能是相同的。 所以,每主题配置会影响Kafka producer的吞吐量(独立运行)和?
-
如何使用Mongo API在共享吞吐量cosmosdb中创建集合
因此,我想操作问题可以归结为:是否有任何方法可以通过MongoDb API将所需的partitionKey传递给CosmosDb,从而成功创建集合?
-
如何在Jmeter中使用吞吐量控制器和多个采样器
我有一个如下的计划: Thread组 取样器B 采样器C(用于注册) 采样器D(用于https(已登录)页面视图1) 采样器E(用于https(已登录)页面视图2) 让我们假设登录页面视图1和2必须在注册后立即发生。由于第三个吞吐量控制器中有多个采样器,因此不可能实现40%(对于整个组)。 对于10个线程,1个循环,我希望看到以下计数: 取样器A: 4 采样器B: 2 采样器C D E: 4 但事