《吐槽》专题
-
Kafka流聚合器-如何设置时间等待在聚合之前吐出消息?
, 我想知道如何控制聚合时间窗口,这样它就不会为每个传入的消息吐出一条消息,而是等待并聚合其中的一些消息。想象一下流应用程序使用这些消息: null 我的代码很简单 目前,它有时会批量聚合,但不确定如何调整它:
-
Windows上的Ant编码问题-UTF-8文件,但在变音符号上吐了垃圾
问题内容: 不知何故,我无法让UTF-8源代码与Ant一起玩得很好。 我收到很多“警告:编码ascii的不可映射字符”。我真的要疯了。数小时,数小时,数小时。顺便说一句,我注意到已经有5个人使用了该标签。:-) 是的,我已经阅读了this,this和其他内容。Google也(至少5个或4个不同搜索的前5个页面结果)。有javac选项。我试过了。还有一些预设或其他东西(对不起,凌晨3点)。也没用。
-
标准SQS与FIFO SQS中的吞吐量,每个消息都有一个唯一的groupId
我不太关心事件的顺序,但我希望消息只处理一次。侦听SQS消息的lambda将其存储在DynamoDB中,因此吞吐量非常重要,因为我有多个微服务(作为生产者)向该SQS写入消息,这些消息将由单个微服务读取。 关于只处理一次消息,这是FIFO队列支持的,但据说吞吐量不好。 如果每条消息都有唯一的groupId,FIFO队列的吞吐量是否与标准队列相同? 如果没有,我的下一个选择可能是在存储消息时在Dyn
-
在Cosmos DB中,物理分区在逻辑分区之间分割的吞吐量如何?
我试图理解Azure Cosmos DB中物理/逻辑分区和吞吐量可用性之间的关系,并有一个关于每个逻辑分区可用吞吐量的问题。 物理分区的可用吞吐量是在逻辑分区之间平均分配,还是在任何逻辑分区都可以使用物理分区可用吞吐量的0-100%的意义上随机分布? > 在这篇Cosmos DB Conf演示文稿-中,演示者提到物理分区可用的吞吐量均匀地分布在物理分区内的所有逻辑分区中(或者至少我是这样推断的)。
-
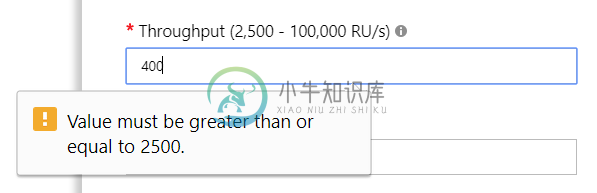 一个分区的CosmosDB/DocumentDB集合是否可以配置少于400 RU/s的吞吐量?
一个分区的CosmosDB/DocumentDB集合是否可以配置少于400 RU/s的吞吐量?更新:这个问题现在无效,因为我认为发生的事件并不像我认为的那样发生(详见下文)。我把这个问题保留原样,因为答案和评论可能对其他人有用。 我通过Azure门户创建了一个集合,最初配置为: 存储容量:无限 初始吞吐能力(Ru/s):2500 分区键: 更新:我想我已经搞清楚发生了什么。我手动创建了一个分区集合,然后忘记了我的代码(我正在使用的导入器/迁移工具)在启动时删除数据库并重新创建数据库和集合。
-
吐温马克斯。本地服务器(MAMP)上的js未正确初始化-抛出错误
我正在MacOS上运行本地服务器(MAMP)。当我打开门的时候。包含TweenMax的网页的php(html)文件http://localhost:8888/Index.php/ 页面加载很好,但tweens根本不起作用。浏览器控制台给出错误:“未捕获不能在空目标之间。” 当我在浏览器中运行完全相同的页面,但该页面托管在远程服务器上时:https://depicture.io/,tweenmax工
-
grpc客户端python:如何创建grpc客户端连接池以获得更好的吞吐量?
我们的用例是提出大量请求。每个请求返回1MB的数据。现在,在客户端,我们创建一个GRPC通道,并在循环中运行以下函数 我的问题是在python中如何创建grpc客户端连接池以获得更好的吞吐量? 在golang我看到了这个https://godoc.org/google.golang.org/api/option#WithGRPCConnectionPool但是我很难在python中找到文档。 py
-
对于必须按顺序发生的操作,处理器的延迟界限和吞吐量界限
我的教科书(计算机系统:程序员的观点)指出,当一系列操作必须严格按顺序执行时,会遇到延迟界限,而吞吐量界限则表征处理器功能单元的原始计算能力。 教科书的问题5.5和5.6介绍了多项式计算的这两种可能的循环结构 和 假设在微体系结构上使用以下执行单元执行循环: 一个浮点加法器。它的延迟为3个周期,并且是完全流水线的 两个浮点乘法器。每个周期的延迟为5个周期,并且都是完全流水线的 四个整数ALU,每个
-
在不影响性能或吞吐量的情况下,对所有线程具有完全原子性
我有一个主机名列表,我应该通过使用正确的URL来打电话。假设我在链表中有四个主机名(hostA,hostB,hostC,hostD)- 执行hostA url,如果hostA启动,则获取数据并返回响应 此外,我的应用程序中运行了一个后台线程,其中包含阻止主机名列表(来自我的另一个服务),我们不应该调用该列表,但它每10分钟运行一次,因此阻止主机名列表只会在10分钟后更新,因此如果存在任何阻止主机名
-
高吞吐量(3GB / s)文件系统可用时,如何使用Java中的多个线程读取文件
问题内容: 我了解对于普通的主轴驱动器系统,使用多个线程读取文件效率很低。 这是另一种情况,我有一个高吞吐量的文件系统可供使用,它具有196个CPU内核和2TB RAM的读取速度高达3GB / s。 单线程Java程序以最大85-100 MB /s的速度读取文件,因此我有可能变得比单线程更好。我必须读取最大1TB的文件,并且有足够的RAM来加载它。 当前,我使用以下内容或类似内容,但需要使用多线程
-
如何使用恒定吞吐量计时器指定一小时内每秒最多4个并发用户
我需要创建一个负载测试,其中每秒最多有4个并发用户。然后我需要重复这个一个小时。有什么方法可以在JMeter中实现这一点吗? 我已尝试使用此配置: 线程数:4 上升周期:1 循环计数:永远 持续时间:3600 为了确保运行一小时,我还使用了一个运行时控制器,该控制器的运行时值为“3600”。 但这会每秒产生比我需要的更多的并发用户,此外,也不太可能有那么多并发用户,因为用户在做某事之前通常需要花这
-
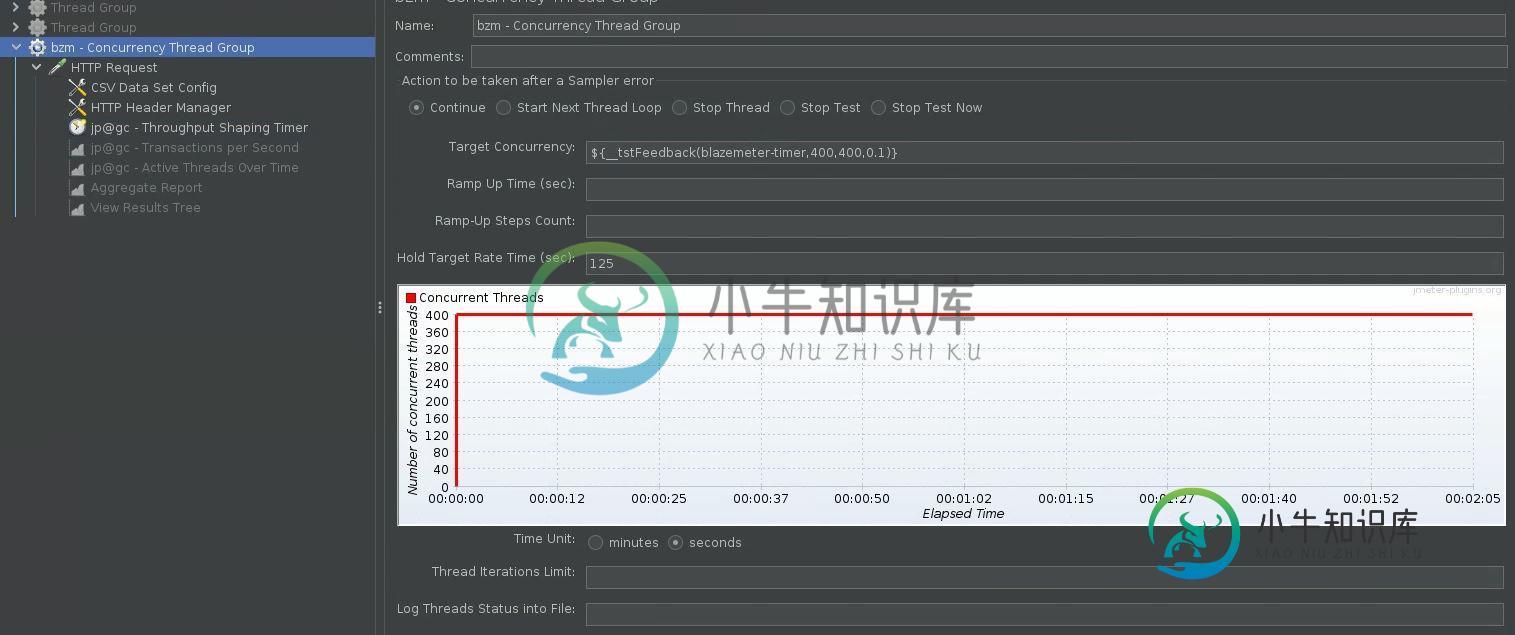 如何使用并发线程组和吞吐量成形计时器组合保持400个RPS的恒定负载
如何使用并发线程组和吞吐量成形计时器组合保持400个RPS的恒定负载我想制作一个测试用例来使用Jmetm发送50,000个具有400 RPS的请求。有人建议我在此用例中使用并发线程组和吞吐量整形计时器的组合,我尝试了以下链接:https://www.blazemeter.com/blog/using-jmeters-throughput-shaping-timer-plugin. 这里的问题是,我在csv中只记录了约28K个响应,而不是50K个响应 无论前一秒发送
-
吞吐量对于所有API都是恒定的,即使响应时间在设置的持续时间内变化很大
我在Jmeter中执行了一个1小时的负载测试。下面是结果 请求A1:样本-130983平均-488毫秒吞吐量-34.11 请求B1:样本-130948平均-170毫秒吞吐量-34.10 请求C1:样本-130940平均-151 ms吞吐量-34.11 请求D1:样本-130860平均-79.98 ms吞吐量-34.09 请求E1:样本-130925平均-1757毫秒吞吐量-33.93 吞吐量和响应
-
是否有可能获得高吞吐量(4-5 TPS)的IO密集型服务在Java与可完成的未来或NodeJs是更好的选择
我们要求开发一种能够处理大容量(约5TPS)的服务。我们必须做3-4个并行的下游Rest呼叫(下面提到的是有2个Rest呼叫的POC)- 我试图使用Completable future to do async rest调用和join方法来实现它,以聚合如下响应:{ResponseWrapper response=null; } 所以,我们需要帮助理解,当我们使用completable future
-
使用线程池和连接池测试postgres数据库的吞吐量。但是为什么我每秒只有300次插入,而它应该是6000次?
我想测试与postgresql数据库有连接的系统的吞吐量。我的系统由两个主要组件组成:一个ThreadPoolExector作为newFixedThreadPool,最多10个线程,一个PGPoolingDataSource,最多10个与数据库的连接。我在postgres数据库中调用存储过程,存储过程执行简单的插入,如果插入失败则返回错误消息。执行此存储过程的单个调用大约需要20-30毫秒。 系统