
一个分区的CosmosDB/DocumentDB集合是否可以配置少于400 RU/s的吞吐量?

更新:这个问题现在无效,因为我认为发生的事件并不像我认为的那样发生(详见下文)。我把这个问题保留原样,因为答案和评论可能对其他人有用。
我通过Azure门户创建了一个集合,最初配置为:
- 存储容量:无限
- 初始吞吐能力(Ru/s):2500
- 分区键:
/partitionkey
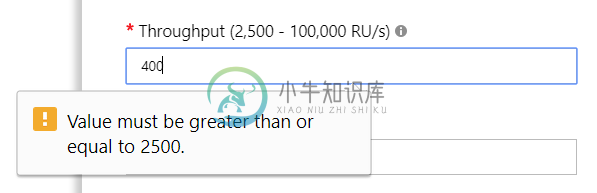
更新:我想我已经搞清楚发生了什么。我手动创建了一个分区集合,然后忘记了我的代码(我正在使用的导入器/迁移工具)在启动时删除数据库并重新创建数据库和集合。当它这样做时,它被创建为一个非分区集合。现在我已经纠正了这个错误,我得到的错误是“offer的有效吞吐量值应该在2500到100000之间,包括100的增量。”如果我试着重现我以前想要做的事情。
共有1个答案

你没看到虫子。您试图在分区集合上设置RU范围。
单分区集合(10GB)允许400-10000 RU。
您在问题中显示的是一个分区集合,规模从2500 ru开始。
-
在幕后,Azure Cosmos DB提供了服务T请求/S所需的分区。如果T高于每个分区的最大吞吐量T,那么Azure Cosmos DB提供N=T/T分区。
-
无论从什么角度来看,它都不是。 假设我有两个消费者,它们以每秒“10”条消息的速度从给定主题中消耗数据。现在,不管它们是从单个分区还是从两个不同的分区进行消耗;我的吞吐量将保持不变,每秒20条消息。 我觉得我一定漏了一些内部工作的细节,你能帮我解释一下kafka分区(多个)是如何帮助提高固定用户数量的吞吐量的,而不是单个kafka分区。
-
我正在写一个jar,打算与Spring和Ehcache一起使用。Spring要求为每个元素定义一个缓存,所以我计划为jar定义一个Ehcache,最好是作为jar中的一个资源,可以导入应用程序的主要Ehcache配置。然而,我对示例Ehcache配置文件的阅读和我的谷歌搜索并没有找到任何导入子Ehcache配置文件的方法。 有没有办法导入一个子Ehache配置文件,或者有没有其他方法来解决这个问题
-
我正在开发一个具有以下特性的实时应用程序: 数百个客户端将同时插入行/文档,每个客户端每隔几秒钟插入一行。 大部分仅追加;几乎所有的行/文档,一旦插入,永远不会改变。 只有当数据被刷新到磁盘时,客户端才会看到成功,此后读写一致性应该保持不变。 客户端愿意等待几秒钟的确认时间足够多的磁盘查找和写入发生。 RAM中的数据太多(排除像Redis这样的选项)。但是写很久以前的行很少被访问,所以在内存中没有
-
因此,我想操作问题可以归结为:是否有任何方法可以通过MongoDb API将所需的partitionKey传递给CosmosDb,从而成功创建集合?
-
我试图使用powershell来改变cosmosDB的吞吐量 当我运行下面的脚本时,它给我这个错误,但之后它工作正常 获取令牌请求返回超文本传输协议错误: 401和服务器响应:{"错误":"invalid_client","error_description":"AADSTS50012:提供了无效的客户端机密。\r\n跟踪ID: GUID\r\n相关ID: GUID\r\n时间戳: 2019-01