
如何使用并发线程组和吞吐量成形计时器组合保持400个RPS的恒定负载

我想制作一个测试用例来使用Jmetm发送50,000个具有400 RPS的请求。有人建议我在此用例中使用并发线程组和吞吐量整形计时器的组合,我尝试了以下链接:https://www.blazemeter.com/blog/using-jmeters-throughput-shaping-timer-plugin.
- 这里的问题是,我在csv中只记录了约28K个响应,而不是50K个响应
- 无论前一秒发送的请求如何,我都需要进行400次RPS
- 我还需要每400行有大约1秒的时差,以便我可以确认每秒发送400个请求
实现同样结果的任何其他建议也可以。
考虑到400*125=50000,我使用400作为起始和结束rps,持续时间为125秒
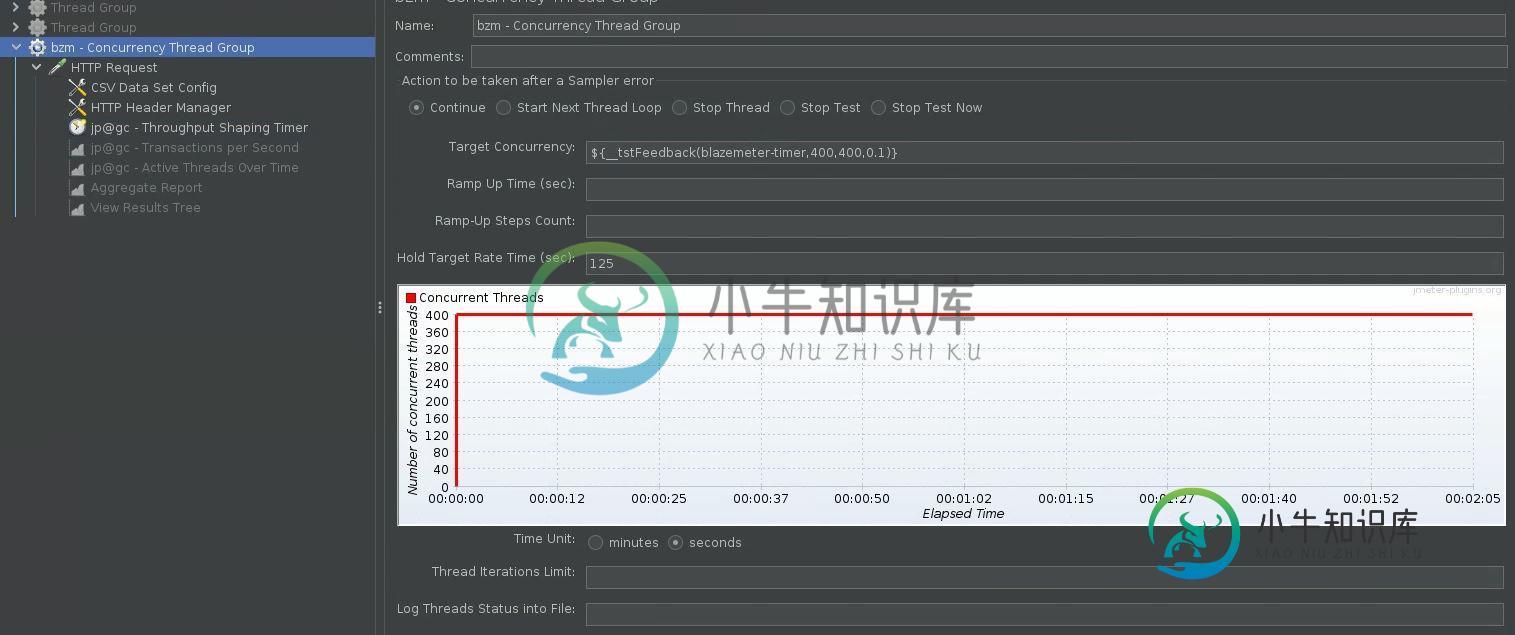
共有1个答案

为了能够用400个线程发送400个RPS,您的应用程序必须在1秒或更短的时间内做出响应,因为JMeter在启动下一个采样器之前会等待来自上一个采样器的响应。如果您的应用程序响应时间为2秒-您将获得200转/秒,4秒-100转/秒,等等。
如果应用程序响应时间更长,则需要按比例增加线程数,40个备用线程可能不够。
此外,JMeter需要能够足够快地发送请求,因此请确保遵循JMeter最佳实践,并在需要时进行分布式测试
如果您的被测应用程序无法处理400个RPS,那么您在JMeter方面无能为力,您只能识别瓶颈,并在重新运行测试之前报告它或自己修复它
-
我想为我正在开发的应用程序模拟100 rpm。我计划使用并发线程组和吞吐量成形计时器。我创建了一个示例来测试它是如何工作的。下面是我的剧本 我已将其添加为log4j2的下一行。xml文件: jmeter.log有以下日志 我的问题是 问题1。我是否正确地配置了测试以模拟100 rpm的吞吐量,或者我遗漏了什么? 问题2。如何提前计算需要添加多少用户才能实现目标并发?如果我用公式 在这里,我是否需要
-
我正在尝试构建一个JMeter测试,包括一个并发线程组和一个吞吐量成形计时器,如这里和这里所述。计时器配置为运行10个斜坡和阶段,RPS从1到333。我想将并发线程组设置为使用调度反馈函数,并在目标并发字段中添加了公式(我已将示例从tst名称更新为实际计时器名称)。如果吞吐量是由计时器管理的,则我假设属性没有那么重要,因此我将爬升时间和步长设置为1;保持目标速率时间为8000,比计时器中添加的步长
-
我有一个JMeter测试计划,其中包含具有不同工作负载和吞吐量的多个线程组。我想使用吞吐量成形计时器,但只对一个线程组应用成形。如果我在线程组中有计时器,它似乎仍然作用于整个测试计划。 例如,如果我将其设置为每秒6个请求,并运行测试10分钟,则在“查看结果”树中会得到3600个条目(这是预期的)。不幸的是,这3600个条目包括来自其他线程组的请求。我希望只从这个线程组中获得3600个条目,然后从其
-
在JMeter 5.4.1中,我在测试计划中使用了2个并发线程组,每个线程组都有如下配置: 每个线程组下面都有一个HTTP采样器,每个HTTP采样器都有一个贯穿成型计时器 我的意图是能够在最初的X秒内在每个采样器上实现1个RPS,但显然,它正在两个采样器之间拆分1RPS并试图总共实现1个RPS,即使每个并发线程组都有自己独立的整个整形定时器。 我的预期是,采样器将产生约1个RPS负载,总计约2个。
-
我正在根据以下要求开发JMeter脚本 Http请求总数-24,Http请求总数/分钟-12,测试持续时间2min,每分钟请求之间的等待时间:60min/12req=5秒。 在我的场景中总共发生了3笔交易 添加文档(占总请求的20%) 添加文档(占总请求的80%) 更新文档(占总请求的100%) 下面是我使用过的线程组和控制器 > 终极线程组终极线程组 (2) 吞吐量控制器分配负载的百分比[24个
-
我需要创建一个负载测试,其中每秒最多有4个并发用户。然后我需要重复这个一个小时。有什么方法可以在JMeter中实现这一点吗? 我已尝试使用此配置: 线程数:4 上升周期:1 循环计数:永远 持续时间:3600 为了确保运行一小时,我还使用了一个运行时控制器,该控制器的运行时值为“3600”。 但这会每秒产生比我需要的更多的并发用户,此外,也不太可能有那么多并发用户,因为用户在做某事之前通常需要花这