
并发线程组和吞吐量成形计时器

我想为我正在开发的应用程序模拟100 rpm。我计划使用并发线程组和吞吐量成形计时器。我创建了一个示例来测试它是如何工作的。下面是我的剧本
我已将其添加为log4j2的下一行。xml文件:
<Logger name="kg.apc.jmeter.timers.VariableThroughputTimer" level="debug" />
jmeter.log有以下日志
2021-07-21 14:11:22,402 INFO c.b.j.c.VirtualUserController: Need to decrease concurrency, thread is done: bzm - Concurrency Thread Group-ThreadStarter 1-217
2021-07-21 14:11:22,402 INFO o.a.j.t.JMeterThread: Thread is done: bzm - Concurrency Thread Group-ThreadStarter 1-217
2021-07-21 14:11:22,402 INFO o.a.j.t.JMeterThread: Thread finished: bzm - Concurrency Thread Group-ThreadStarter 1-217
2021-07-21 14:11:22,407 DEBUG k.a.j.t.VariableThroughputTimer: Calculating 407 380.0 38
2021-07-21 14:11:22,427 INFO c.b.j.c.VirtualUserController: Need to decrease concurrency, thread is done: bzm - Concurrency Thread Group-ThreadStarter 1-218
2021-07-21 14:11:22,427 INFO o.a.j.t.JMeterThread: Thread is done: bzm - Concurrency Thread Group-ThreadStarter 1-218
2021-07-21 14:11:22,427 INFO o.a.j.t.JMeterThread: Thread finished: bzm - Concurrency Thread Group-ThreadStarter 1-218
........
........
2021-07-21 14:11:23,007 DEBUG k.a.j.t.VariableThroughputTimer: Second changed 60.0 , waiting: 0, samples sent 94, current rps: 100.0 rps
2021-07-21 14:11:23,007 WARN k.a.j.t.VariableThroughputTimer: No free threads available in current Thread Group bzm - Concurrency Thread Group, made 94 samples/s for expected rps 100.0 samples/s, increase your number of threads
2021-07-21 14:11:23,007 DEBUG k.a.j.t.VariableThroughputTimer: Calculating 7 0.0 0
我的问题是
问题1。我是否正确地配置了测试以模拟100 rpm的吞吐量,或者我遗漏了什么?
问题2。如何提前计算需要添加多少用户才能实现目标并发?如果我用公式
(rps * Maximum response time) / 1000
在这里,我是否需要将所有采样器的最大响应时间从1添加到6?或者如何?
第三季度。我们如何计算吞吐量?(参见第三张有汇总报告的图片),
是总吞吐量=将采样器1到6的吞吐量相加,即=(15.8 15.8 15.8 15.7 15.6 15.6) = 94.3rps。我的计算正确吗?
第四季度。在jmeter中。日志,它说“需要减少并发,线程完成了:bzm-并发线程组ThreadStarter 1-217”。
这是否意味着模拟100 rps所需的线程(用户)数量更多,因此jmetm需要减少线程(用户)?
然后在日志中,它说,“当前线程组bzm-并发线程组中没有可用的空闲线程,为预期的rps 100.0个样本/秒制作了94个样本/秒,增加线程数量”
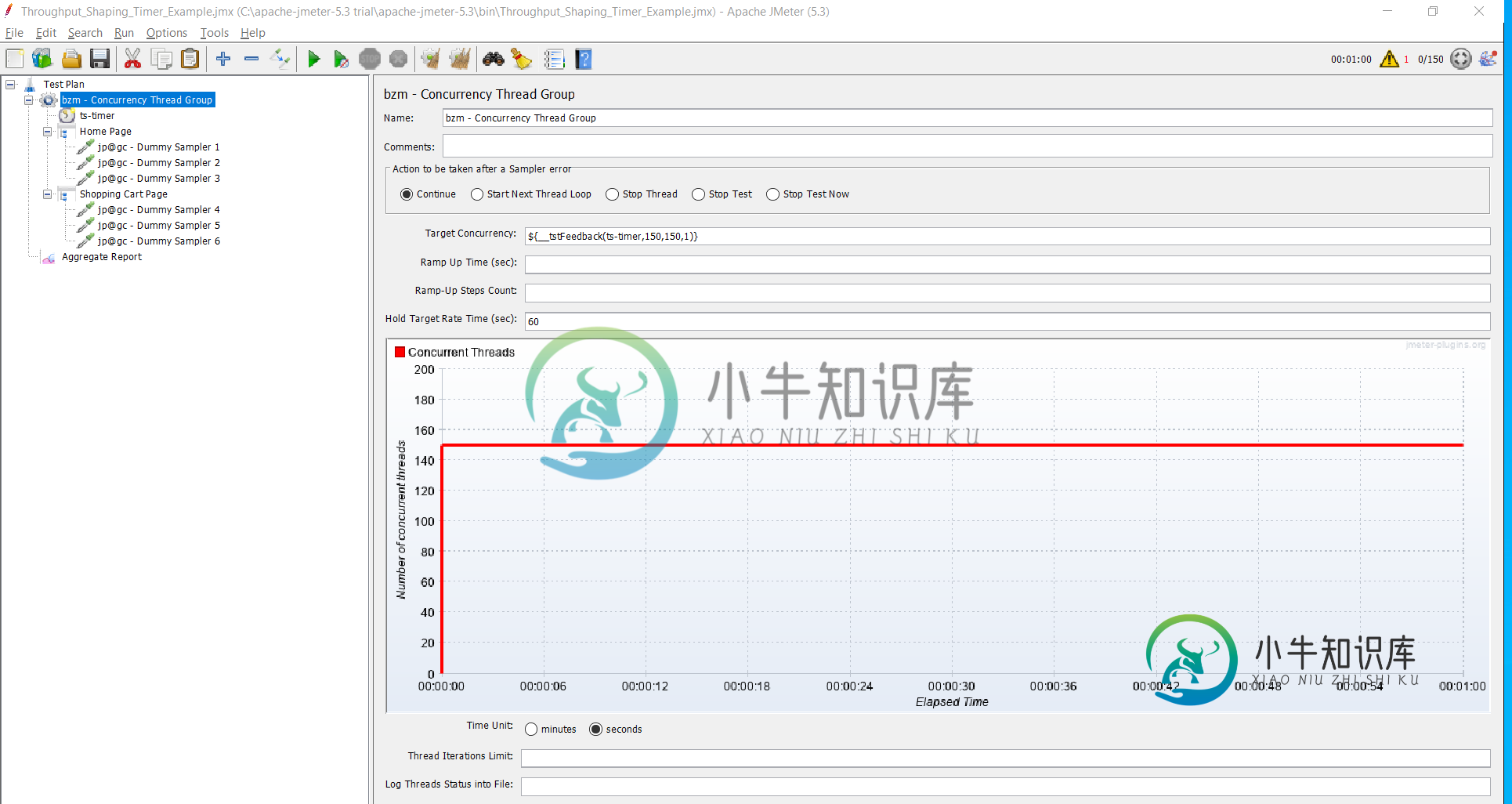
是要求我(用户)增加线程,还是只是jmeter在自言自语?Jmeter已经有150个线程可供使用。实际上,我从50开始,然后我收到消息增加线程数,然后我将线程数增加到100,我得到了相同的消息,最后我将其增加到150,并且仍然在日志中得到该消息?
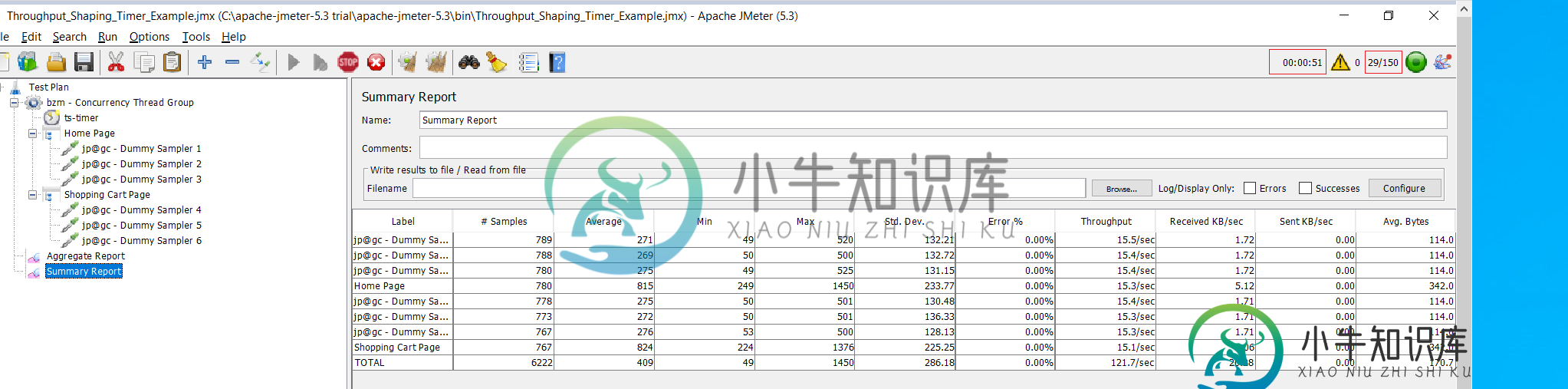
如上图所示,在第51秒,jmetm只使用了150个线程中的29个(用户)。这意味着它还有121个线程可以使用。此外,我观察到,当我启动脚本时,立即有150个线程在使用,但随后它们开始快速减少和增加。然而,他们从来没有在60秒的运行中达到150(150个线程只在开始时使用,只有几分之一秒,然后减少了!)
那么为什么日志中的消息会增加用户?事实上,jmeter可以使用哪些用户?
共有1个答案

你只忘了问“Q5”:生命、宇宙和一切的终极问题
>
Q2.根据JMeter线程模型,实现有史以来最大的响应时间,每个线程在开始下一个请求之前等待上一个请求完成,因此6个采样器的整个序列将以最慢的速度运行。
第三季度。吞吐量成形计时器尝试达到并保持其范围内所有采样器的定义吞吐量,因此,如果范围内有6个请求,则单个请求的吞吐量将为100/6
第四季度<代码>需要降低并发性-计时器正在“自言自语”,告知它运行得太快,因此需要关闭两个线程以降低请求速率增加线程数适合您,但我认为它不适用于您的情况,如果您运行真正的测试,并在日志中看到大量这样的消息,则表明当前数量不足以达到目标吞吐量
不要在GUI模式下运行测试,它仅用于测试开发和调试,当涉及到执行时,您必须使用命令行非GUI模式
根据JMeter最佳实践,您应该始终使用JMeter的最新版本,因此请考虑升级到JMeter 5.4.1或JMeter下载页面上提供的最新稳定版本
-
我正在尝试构建一个JMeter测试,包括一个并发线程组和一个吞吐量成形计时器,如这里和这里所述。计时器配置为运行10个斜坡和阶段,RPS从1到333。我想将并发线程组设置为使用调度反馈函数,并在目标并发字段中添加了公式(我已将示例从tst名称更新为实际计时器名称)。如果吞吐量是由计时器管理的,则我假设属性没有那么重要,因此我将爬升时间和步长设置为1;保持目标速率时间为8000,比计时器中添加的步长
-
我有一个JMeter测试计划,其中包含具有不同工作负载和吞吐量的多个线程组。我想使用吞吐量成形计时器,但只对一个线程组应用成形。如果我在线程组中有计时器,它似乎仍然作用于整个测试计划。 例如,如果我将其设置为每秒6个请求,并运行测试10分钟,则在“查看结果”树中会得到3600个条目(这是预期的)。不幸的是,这3600个条目包括来自其他线程组的请求。我希望只从这个线程组中获得3600个条目,然后从其
-
我想制作一个测试用例来使用Jmetm发送50,000个具有400 RPS的请求。有人建议我在此用例中使用并发线程组和吞吐量整形计时器的组合,我尝试了以下链接:https://www.blazemeter.com/blog/using-jmeters-throughput-shaping-timer-plugin. 这里的问题是,我在csv中只记录了约28K个响应,而不是50K个响应 无论前一秒发送
-
我有一个带有七个线程组的巨大脚本。我使用了Conccurency线程组和吞吐量整形计时器。我有两个问题: 我是否可以将吞吐量成形计时器中的值与点一起使用,例如,开始RPS:0.01,结束RPS:0.3 如何在CTG中多次使用吞吐量成形计时器?例如:我有10个步骤。前5步的RPS应为0.5到2(阶梯式),第6步和第7步的RPS应为0.3到0.8,最后一步的RPS应为0.1到0.4。我想使用比例-我的
-
我已经使用作为jmeter插件提供的吞吐量整形仪创建了一个最大峰值负载为5000 rpm的概要文件。 当我添加“每秒事务数”作为侦听器以分析每秒请求时。它没有显示5000rpm的峰值负载。 每秒事务侦听器是否显示吞吐量成形仪生成请求的图,或针对任何目标服务器生成的请求的实际执行图。 如何确认请求的生成达到5000 rpm的最大峰值负载?目前,我正在使用http采样器生成请求。
-
在JMeter 5.4.1中,我在测试计划中使用了2个并发线程组,每个线程组都有如下配置: 每个线程组下面都有一个HTTP采样器,每个HTTP采样器都有一个贯穿成型计时器 我的意图是能够在最初的X秒内在每个采样器上实现1个RPS,但显然,它正在两个采样器之间拆分1RPS并试图总共实现1个RPS,即使每个并发线程组都有自己独立的整个整形定时器。 我的预期是,采样器将产生约1个RPS负载,总计约2个。