《吐槽》专题
-
UWP吐司自定义声音不播放
我有这个祝酒词要出现,一切都很好,除了音频。我试图将toast.mp3放在不同的位置,如项目主文件夹、资产等,甚至使用了d:/myprojectpath/Assets/toast.mp3这样的路径,但通知仍然是静默的。我是个初学者,所以也许我错过了什么...当然,我也在寻找解决方案,但没有任何帮助。下面是我的代码:
-
如何增加pgbouncher的连接吞吐量?
我在交易模式下使用pgbouncer 当前设置:[“n”个客户端--- 我注意到,当我使用pgbouncer而不是直接连接到postgres时,我的交易/秒(tps)显著减少。 对于相同的set to事务(通过pgbench) > pgbouncer连接= pgbouncer中是否有任何配置需要调整以实现更好的性能? 我知道pgbouncer是一个单线程应用程序,但我希望将其调整到最佳状态。以下是
-
吞吐量和响应时间的关系
我对193个示例运行了一个JMeter测试,平均响应时间为5915ms,Throghput为1.19832。 我只想知道它们到底有什么关系
-
 8.27 360笔试吐槽,赛码的输入太坑了QwQ!
8.27 360笔试吐槽,赛码的输入太坑了QwQ!不得不说,赛码的输入是真的坑……用python的 input() 读输入,第一题死活只过9%(只能过9%的,估计都是因为没处理行尾的换行符)。搞了半天,发现改成 input().strip() 马上就能AC了。 第一题DNA替换 记下 a = 第一个是A,第二个是T的数目;t = 第二个是A,第一个是T的数目。输出较大的即可 第二题快速排序 根据快排的性质,分割点一定在正确的位置上,而每两个分割点
-
 没想到面试的吐槽环节能来到字节
没想到面试的吐槽环节能来到字节背景:10月底我接了个字节打来的电话,想约面试(我之前面过字节,二面挂),当时想的没什么事,闲来无聊面一次也无妨,然后就答应了下来,约在了11.6面试。岗位是:生活服务-客户端开发 面试过程: 1. 自我介绍环节:我说到“经常打竞赛,CF/Leetcode,特别是Leetcode竞赛分数全国700,周赛基本稳定前200+...”,然后面试官打断了我,问了一些有关竞赛的事宜(这个倒也没什么,打断说话
-
从微信、微博、人人网,中选一款来进行吐槽,简单介绍吐槽的功能并提出你的改进方案。
本文向大家介绍从微信、微博、人人网,中选一款来进行吐槽,简单介绍吐槽的功能并提出你的改进方案。相关面试题,主要包含被问及从微信、微博、人人网,中选一款来进行吐槽,简单介绍吐槽的功能并提出你的改进方案。时的应答技巧和注意事项,需要的朋友参考一下 微信为嘛不搞个一键已读所有服务号消息。enn,可能怕点了导致关键的消息被忽略了。 可是。。。关注了那么多服务号,一个月没点,我还要一个个点开把红点消除嘛?
-
Redis如何实现高吞吐量和性能?
问题内容: 我知道这是一个非常笼统的问题。但是,我想了解使Redis(或诸如MemCached,Cassandra之类的缓存)在惊人的性能极限下工作的主要架构决策是什么。 如何维护连接? 连接是TCP还是HTTP? 我知道它完全用C编写。如何管理内存? 尽管存在竞争的读/写,但用于实现高吞吐量的同步技术有哪些? 基本上,具有内存高速缓存的计算机和可以响应命令的服务器的普通香草实现和Redis框之间
-
 redis通过pipeline提升吞吐量的方法
redis通过pipeline提升吞吐量的方法本文向大家介绍redis通过pipeline提升吞吐量的方法,包括了redis通过pipeline提升吞吐量的方法的使用技巧和注意事项,需要的朋友参考一下 案例目标 简单介绍 redis pipeline 的机制,结合一段实例说明pipeline 在提升吞吐量方面发生的效用。 案例背景 应用系统在数据推送或事件处理过程中,往往出现数据流经过多个网元; 然而在某些服务中,数据操作对redis 是强依
-
响应时间减少,吞吐量也减少
我运行jmeter脚本将近一周,今天观察到一件有趣的事情。以下是场景: 概述:我正在逐渐增加应用程序的负载。在上一次测试中,我给应用程序加载了100个用户,今天我将加载增加到150个用户。 150名用户测试结果: > 与上次测试相比,请求的响应时间减少了。(这是个好兆头) 吞吐量急剧下降到上一次测试的一半,负载更少。 我的问题是: > 当我的许多请求失败时,我得到了好的响应时间吗? 注:直到100
-
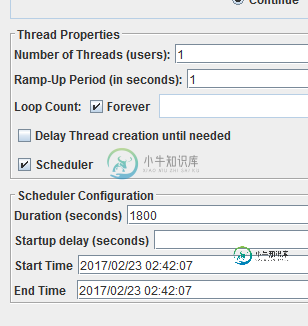 无法增加jmeter中的平均吞吐量
无法增加jmeter中的平均吞吐量我已经将线程数和上升时间设置为1/1,我正在从data.csv迭代我的1000条记录1800秒。现在给出数字,我已经设置了CTT,恒定时间吞吐量为每分钟2000,我预计平均吞吐量2000/60 = 33.3 /sec,但我得到18.7/秒,当我将吞吐量提高到4000/60时,我仍然得到18或19/秒。
-
Android-自定义吐司触摸外部活动
我正在尝试使用自定义toast和和。当我触摸任何地方(点击按钮,触摸布局……)时,我希望我的吐司消失,但它没有。 我读取了文件,并尝试在调用新Toast之前使用方法,但这并没有解决任何问题。有人能给我一个解决办法吗?
-
ReadLock=Changed时的Camel文件组件吞吐量
面对网络延迟,如何在不牺牲完整性的情况下提高吞吐量?
-
GCP/Dataproc上Kafka、Spark、Elasticsearch堆栈的吞吐量
我正在做一个研究项目,我在谷歌云平台上安装了一个完整的数据分析管道。我们使用Spark上的HyperLogLog实时估计每个URL的唯一访问者。我使用Dataproc来设置Spark集群。这项工作的一个目标是根据集群大小来度量体系结构的吞吐量。Spark集群有三个节点(最小配置) 使用Java编写的数据生成器模拟数据流,其中我使用了kafka producer API。体系结构如下所示: 我用一个
-
 吐血整理超全面积分享-6(jvm)
吐血整理超全面积分享-6(jvm)面经分享第六篇,会持续分享哦 面试时候整理的面积哦,大家记得点赞关注我哦!主页有内推链接哦。 问题 运行时数据区域 程序计数器 Java 虚拟机栈 扩展:那么方法/函数如何调用? 本地方法栈 堆 方法区 方法区和永久代的关系 为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?++ 运行时常量池 直接内存 HotSpot 虚拟机对象探秘 对象的创建 Step1:类加载检
-
 腾讯云 CSIG - 后台开发 - 实习三面面经 & 吐槽
腾讯云 CSIG - 后台开发 - 实习三面面经 & 吐槽三月底投的TEG,17号晚上被CSIG HR捞了起来,准备参加远程面试。 用的腾讯会议,算法题用的内置IDE(面呗) 凭借回忆整理了一下面试中的问题……不保证完整性。 04/19 - 一面 - 50mins 自我介绍 算法题:数组中出现两次的元素。 给一个长度为n的数组,数组元素大小 1 <= ai <= n,其中有些元素出现两次有些出现一次,问如何能经过 一次遍历 后 原地 找到出现两次的数据。