《比特大陆》专题
-
MySQL计算百分比
我有一个包含4个项的MySQL数据库:(数值)、、和。 在我的中,我需要根据“surveys”中的数字来计算接受调查的“employees”的百分比。 这就是我现在的说法: 下面是表格的原样: 我想根据中的数字计算参加调查的的百分比。即,如上面的数据所示,将为0%,将为95%。
-
finish()与startActivity()的比较
根据Android文档,finish()的功能与“后退”按钮的功能完全相同。基本上,当我调用finish()时,会调用onStop()。 我试图重写onStateSaveInstance()以保存当前状态,但从未调用它。但是,如果通过创建新的Intent并使用startActivity()转到上一个活动,则会调用onStateSaveInstance()方法。这有什么原因吗?
-
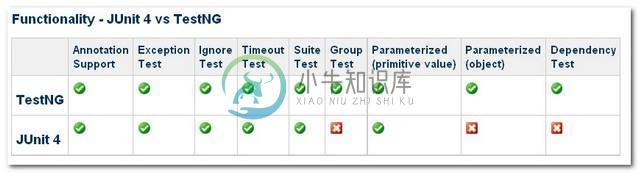 JUnit 4 Vs TestNG比较
JUnit 4 Vs TestNG比较主要内容:1. 注释支持,2. 异常测试,3. 忽略测试,4. 时间测试,5. 套件测试,6. 参数化测试,7.依赖性测试,结论JUnit 4和TestNG都是Java中非常受欢迎的单元测试框架。两种框架在功能上看起来非常相似。 哪一个更好? 在Java项目中应该使用哪个单元测试框架? 下面表中概括了JUnit 4和TestNG之间的功能比较。如下图所示 - 1. 注释支持 注释/注解支持在JUnit 4和TestNG中是非常类似的。 特点 JUnit 4 TestNG 测试注释 @Test @
-
Tableau与Power BI比较
主要内容:Tableau,Power BITableau和Power BI都是最近的优秀可视化工具。Tableau已成为数据分析和BI工具的市场领导者。 Power BI是Tableau最接近的竞争对手。两种可视化工具都有自己的优势和特色,每种都可以根据需求用于业务。 Tableau提供了一种可视化工具,可以让公司任何级别的所有用户都能轻松理解数据。 Power BI服务于小型企业,并提供了一种使用界面的简便方法,可以创建功能强大的仪表板
-
同时做和比较
问题内容: 同时执行: 我目前正在学习do-while vs while,并且想用while重写上面的java片段(已经声明和初始化)。以下重写的代码是否正确: 而: 干杯 问题答案: 之间的区别和是 当 比较完成。使用,您将在最后进行比较,因此至少要进行一次迭代。 您的示例的等效代码 等效于: 一般理解 甲环是一个 出口控制的循环 ,这意味着它离开末。甲环是一个 条目控制的循环 ,这意味着该条件
-
休眠与iBATIS对比
问题内容: 为了重新设计新产品,我们正在从Java中选择最佳框架。由于考虑使用模型的数据库不可知方法,因此我们正在研究iBATIS或Hibernate在Struts +Spring之间的选项。请提出建议,因为两者都可以提供持久性。 问题答案: Ibatis和Hibernate是完全不同的野兽。 我倾向于这样看待它:如果您的视图以 对象为中心, 则Hibernate会更好地工作。但是,如果您认为以
-
2.2 选择与比较
2.2 选择与比较 vim 在执行脚本时,一般是按顺序逐条语句执行的。但如果只能像流水帐地顺序执行,未 免太无趣了,功能也弱爆了。本节介绍顺序结构之外的最普遍的选择分支结构,它可以根 据某种条件有选择地执行或不执行语句块(一条或多条语句)。 在 VimL 中通过 :if 命令来表示条件选择,其基本语法结构是: : if {expr} : " todo : endif 如果满足表达式 {e
-
802.16与802.11的比较
本文向大家介绍802.16与802.11的比较,包括了802.16与802.11的比较的使用技巧和注意事项,需要的朋友参考一下 IEEE 802.16是定义微波访问无线互操作性(WiMAX)的标准,该技术是将网络服务提供到宽带访问的最后一英里的无线技术。 IEEE 802.11标准制定了在有限区域内连接无线设备的无线局域网(WLAN)或Wi-Fi的规范。 下表比较了802.16和802.11- 特
-
python difflib比较文件
问题内容: 我正在尝试使用difflib为包含推文的两个文本文件生成diff。这是代码: 这是文本文件: 这是文本文件: 这是我从程序中得到的差异: 正如你可以快速地比较两个源文件(PTITVProgs和new_tweets)它们之间的区别是看到 了3个鸣叫是4月7日 和 4月3日3个鸣叫 。 我只希望其中的行不出现在差异中。 但这会抛出一堆我不想看到的文本。我不知道是什么,并在差异中输出立场…?
-
AngularJS + Jasmine:比较对象
问题内容: 我刚刚开始为AngularJS应用编写测试,并且正在Jasmine中进行测试。 以下是相关的代码段 ClientController: ClientControllerSpec: 测试失败: 有谁知道为什么会发生这种情况吗? 另外..由于我不熟悉AngularJS测试,因此欢迎对我的测试设置错误还是可以改进提出任何意见。 更新: 包括ClientService: 另外,我通过比较id解
-
比较Pyspark中的列
问题内容: 我正在与n列的PySpark DataFrame。我有一组m列(m <n),我的任务是选择其中包含最大值的列。 例如: 输入:PySpark DataFrame包含: Ouput: 在PySpark中有什么方法可以执行此操作,还是应该将PySpark df转换为Pandas df,然后执行操作? 问题答案: 您可以减少在列列表中使用SQL表达式: Spark 1.5+还提供, 如果要保
-
比较真假混淆
问题内容: 我对分配给False,True的测试值感到困惑 要检查真实值,我们只需 假怎么样? 问题答案: 从Python样式指南中: 对于序列(字符串,列表,元组),请使用空序列为假的事实。 [..] 不要使用==将布尔值与True或False进行比较。
-
是org.junit.assert.assertThat比org.hamcrest.matcherassert.assertThat好吗?
我是JUnit和Hamcrest的新手,希望得到最佳实践建议,以便决定首先学习哪些文档。 对于初学者,这些方法中哪一个更好? org.junit.assert.assertThat(来自junit-4.11.jar) org.hamcrest.matcherassert.assertThat(来自hamcrest-core-1.3.jar)
-
加密比较散列
我有一个简单的密码加密程序,当用户注册时,它会给我一个散列/盐析密码,以存储在我的数据库中。代码: 当用户登录时,我想我不能简单地通过此代码将输入的密码放回并进行比较,因为这会给我一个不同的结果。如何简单地将存储的密码与输入的登录密码进行比较?
-
pbkdf2和哈希比较
我使用mitsuhiko的pbkdf2实现进行密码哈希: 此函数返回二进制摘要,然后将其编码在bas64中并保存到数据库中。此外,当用户登录时,Base64字符串被设置为cookie。 此函数用于密码哈希比较: 我想知道在安全性方面,二进制哈希和Base64字符串的比较是否有任何不同?例如,当用户登录时,我会计算提交密码的二进制摘要,从数据库中解码Base64字符串,然后比较两个二进制哈希,但是如