《B站》专题
-
我的网站运行在Docker容器中,如何实现虚拟主机?
问题内容: 我在vps中分别在两个docker容器中运行两个网站。例如www.myblog.com和www.mybusiness.com 如何在vps中实现virtualhost,以便两个网站都可以使用端口80。 我在其他地方问了这个问题,建议您看看:https : //github.com/hipache/hipache和https://www.tutum.co/ 他们看起来有些弯曲。我试图找到
-
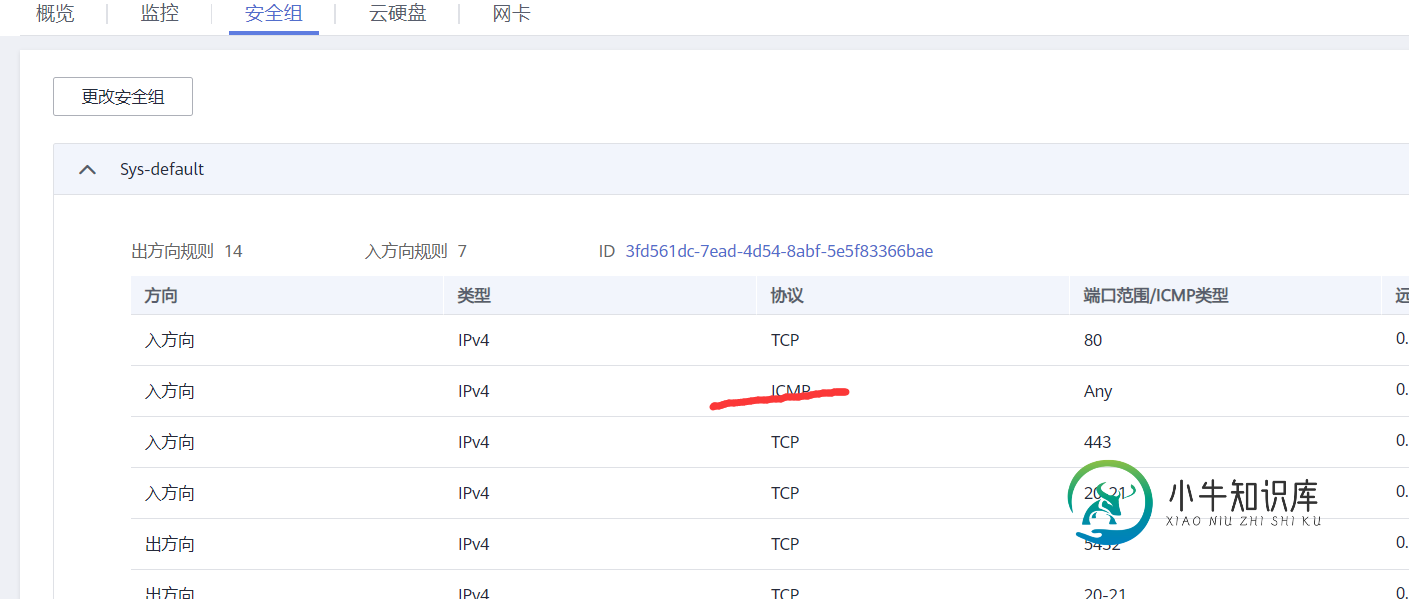 docker容器中布置静态网站的实现
docker容器中布置静态网站的实现本文向大家介绍docker容器中布置静态网站的实现,包括了docker容器中布置静态网站的实现的使用技巧和注意事项,需要的朋友参考一下 服务器布置 这里推荐使用云服务器(阿里云、华为云、腾讯云)可以免费使用几天。在我们买了服务器后会遇到如下问题: 本地电脑ping服务器主机发现ping不通,请求超时 我们需要在管理服务器的界面找到安全组那一栏,然后在安全组出入都要加入icmp这个,建议直接一键添加
-
基于JavaScript实现 网页切出 网站title变化代码
本文向大家介绍基于JavaScript实现 网页切出 网站title变化代码,包括了基于JavaScript实现 网页切出 网站title变化代码的使用技巧和注意事项,需要的朋友参考一下 废话不多说了,直接给大家贴代码了,具体代码如下所示: 以上代码就是JavaScript实现 网页切出 网站title变化代码,希望对大家有所帮助!
-
在Django网站中将HTML渲染为PDF
问题内容: 对于我的django网站,我正在寻找一种将动态html页面转换为pdf的简单解决方案。 页面包含HTML和来自Google可视化API的图表(该图表基于javascript,但必须包含这些图表)。 问题答案: 尝试从Reportlab解决方案。 下载并像往常一样使用python setup.py install安装 你还需要安装以下模块:具有easy_install的xhtml2pdf
-
如何在Django网站上记录服务器错误
问题内容: 因此,在进行开发时,我可以设置为,如果发生错误,我可以看到格式正确,并具有良好的堆栈跟踪和请求信息。 但是在某种生产站点上,我更愿意使用并向访问者展示一些标准错误500页,其中包含我目前正在修复此bug的信息;) 同时,我想以某种方式记录所有错误这些信息(堆栈跟踪和请求信息)存储到服务器上的文件中-因此我可以将其输出到控制台并观看错误滚动,每小时将日志发送给我或类似的东西。 你会为dj
-
如何在Django模板中获取网站的域名?
问题内容: 如何从Django模板中获取当前站点的域名?我试着寻找标签和过滤器,但那里什么也没有。 问题答案: 我认为你要访问的是请求上下文,请参阅RequestContext。
-
C#导出网站功能实例代码讲解
本文向大家介绍C#导出网站功能实例代码讲解,包括了C#导出网站功能实例代码讲解的使用技巧和注意事项,需要的朋友参考一下 这个导出网站功能指通过前台javascript触发进入ashx函数中,实现将服务器中某个文件夹(包含其子文件夹和文件)通通复制到服务器中另一处位置,当然该文件夹本身就是一个网站。所以导出网站最重要的两个功能,除了javascript的触发,就是C#ashx文件复制文件夹的操作。
-
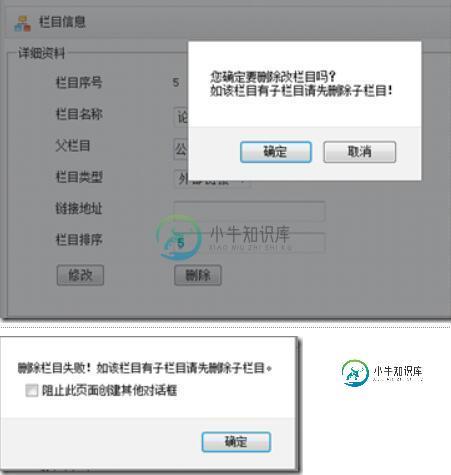 MVC4制作网站教程第四章 删除栏目4.4
MVC4制作网站教程第四章 删除栏目4.4本文向大家介绍MVC4制作网站教程第四章 删除栏目4.4,包括了MVC4制作网站教程第四章 删除栏目4.4的使用技巧和注意事项,需要的朋友参考一下 三、栏目 3.1添加栏目 3.2浏览栏目 3.3更新栏目 3.4删除栏目 先打开【CategoryController】,添加删除栏目ManageDeleteJson(int id),在action先看一下是否有子栏目,如有子栏目则不能删除,没有子栏目
-
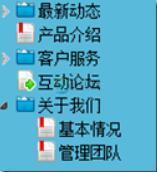 MVC4制作网站教程第四章 前台栏目浏览4.5
MVC4制作网站教程第四章 前台栏目浏览4.5本文向大家介绍MVC4制作网站教程第四章 前台栏目浏览4.5,包括了MVC4制作网站教程第四章 前台栏目浏览4.5的使用技巧和注意事项,需要的朋友参考一下 三、栏目 3.4前台栏目浏览 网站的前台页面,顶部要能显示根栏目,点击栏目名称进入栏目中要子栏目导航,栏目页中还必须有当前路径。先做这三部分 1)、根栏目 打开【CategoryController】,添加[PartialRoot]Act
-
 Java爬虫实战抓取一个网站上的全部链接
Java爬虫实战抓取一个网站上的全部链接本文向大家介绍Java爬虫实战抓取一个网站上的全部链接,包括了Java爬虫实战抓取一个网站上的全部链接的使用技巧和注意事项,需要的朋友参考一下 前言:写这篇文章之前,主要是我看了几篇类似的爬虫写法,有的是用的队列来写,感觉不是很直观,还有的只有一个请求然后进行页面解析,根本就没有自动爬起来这也叫爬虫?因此我结合自己的思路写了一下简单的爬虫。 一 算法简介 程序在思路上采用了广度优先算法,对未遍历过
-
 Java爬虫抓取视频网站下载链接
Java爬虫抓取视频网站下载链接本文向大家介绍Java爬虫抓取视频网站下载链接,包括了Java爬虫抓取视频网站下载链接的使用技巧和注意事项,需要的朋友参考一下 本篇文章抓取目标网站的链接的基础上,进一步提高难度,抓取目标页面上我们所需要的内容并保存在数据库中。这里的测试案例选用了一个我常用的电影下载网站(http://www.80s.la/)。本来是想抓取网站上的所有电影的下载链接,后来感觉需要的时间太长,因此改成了抓取2015
-
5个对远程站点的请求后,node.js http.get挂起
问题内容: 我正在编写一个简单的api端点,以确定我的服务器是否可以访问互联网。它工作得很好,但是在5个请求(每次恰好5个)之后,请求挂起。当我将Google切换到Hotmail.com时,也会发生同样的事情,这使我认为这是对我不利的事情。我是否需要关闭http.get请求?我给人的印象是该功能会自动关闭请求。 问题答案: 这是 “恰好5” 的原因:https : //nodejs.org/doc
-
利用.Htaccess阻止IP恶意攻击网站,禁止指定域名访问,禁止机器爬虫,禁止盗链
本文向大家介绍利用.Htaccess阻止IP恶意攻击网站,禁止指定域名访问,禁止机器爬虫,禁止盗链,包括了利用.Htaccess阻止IP恶意攻击网站,禁止指定域名访问,禁止机器爬虫,禁止盗链的使用技巧和注意事项,需要的朋友参考一下 前几天发现我的网站被一些IP发起了大量恶意的、有针对性的扫描,企图通过暴力探测方式获取网站中一些内部配置文件和信息。我是用.Htaccess来化解攻击的,就是在.Hta
-
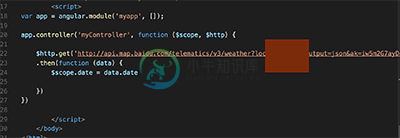 使用AngularJS 跨站请求如何解决jsonp请求问题
使用AngularJS 跨站请求如何解决jsonp请求问题本文向大家介绍使用AngularJS 跨站请求如何解决jsonp请求问题,包括了使用AngularJS 跨站请求如何解决jsonp请求问题的使用技巧和注意事项,需要的朋友参考一下 今天写东西的时候遇到了 一种情况 ,因为用的不是自己公司人员写的接口 ,而我要写的东西是抓别的网页上的接口 所以出现了 一下这种情况 用 get请求出现拦截跨站请求资源 以下是解决办法, 这是我的请求: 我在浏览器模板
-
域内禁止上某个网站的方法(wpkg.org)
本文向大家介绍域内禁止上某个网站的方法(wpkg.org),包括了域内禁止上某个网站的方法(wpkg.org)的使用技巧和注意事项,需要的朋友参考一下 最近访问国外有些网站会自动跳转到wpkg.org,解决办法是在hosts文件里添加127.0.0.1 wpkg.org,但用户太多,动手能力又不敢恭维,怎么办呢? 方法1:在网络设备上做域名跳转,这种方法是最推荐的,省时省力 方法2:用域策略下发修