《烽火星空》专题
-
火花流调优每个批处理大小不工作的记录数?
创建了具有3个分区的主题 创建StreamingContext时将批处理持续时间设置为10秒 以纱线模式运行,有2个执行程序(3个分区共4个内核) 现在我如何测试它是否起作用。 我有一个制作人,一次发送60000条消息到这个主题。当我检查spark UI时,我得到以下信息:
-
是否存在火花默认值。与pip一起安装pyspark时的conf
我用pip安装了pyspark。我在jupyter笔记本中编码。一切正常,但我在导出大型。同样在spark文档中,它说 注意:在客户端模式下,不能直接在应用程序中通过SparkConf设置此配置,因为此时驱动程序JVM已经启动。请通过--driver memory命令行选项或在默认属性文件中设置此配置 但是用安装时恐怕没有这样的文件。我对吗?我该如何解决这个问题? 谢啦!
-
Symfony2安全不同的防火墙不能正确重定向到登录
我根据用户类型配置了3个安全区域:管理员、教师和学生。当我访问 /admin时,我被正确地重定向到 /admin/login.但是当我访问 /teacher或 /student重定向失败,尽管我被重定向到 /teacher/login或 /student/login我得到这个错误: 页面重定向不正确Firefox检测到服务器正在以一种永远无法完成的方式重定向对此地址的请求。 这是我的安全。yml:
-
从Spark到HBase:org写作。阿帕奇。火花SparkException:任务不可序列化
我在我大学的热图项目中,我们必须从txt文件(坐标、高度)中获取一些数据(212Go),然后将其放入HBase以在带有Express的Web客户端上检索它。 我练习使用144Mo文件,这是工作: 但是我现在使用212Go文件,我有一些内存错误,我猜收集方法会收集内存中的所有数据,所以212Go太多了。 所以现在我在尝试这个: 我得到了“org.apache.spark.SparkException
-
如何使用包含字符串的数组获取文档?云火库
所以我在网上找遍了所有地方,但我似乎不知道如何让它发挥作用。 我试图实现的是找到所有在其设备下拥有相同设备的用户。这是Firest数据库的结构:数据库映像 因此,Firebase最近发布了其Javascript库的5.3.0版,在其发行说明中指出: 添加了“array contains”查询运算符以用于。where()查找数组字段包含特定元素的文档。 Firebase Javascript发行说明
-
我的防火墙阻止了docker容器与外界的网络连接
对我来说,这是一个非常标准的设置,我有一台运行docker和ufw的ubuntu机器作为我的防火墙。 如果我的防火墙处于启用状态,则 Docker 实例无法连接到外部 下面是 ufw 日志,显示来自 docker 容器的已阻止连接。 我尝试使用ip添加规则。 而且毫无变化依然受阻。 如何使用 ufw 规则允许从容器到外部的所有连接?
-
允许应用程序引擎防火墙规则中的云功能ip
我们已经创建了一个应用引擎实例作为后端,另一个来自云函数。现在云函数需要在同一个谷歌项目中从应用引擎访问api。如果应用引擎的防火墙允许每个人访问,这很好。但是在我们的例子中,我们需要限制来自云函数的访问。 我是GCP的新手,非常感谢您的建议。提前谢谢。
-
用于火灾和遗忘模型的Spring Cloud网关过滤器工厂
我正在探索Spring Cloud网关过滤器工厂,它可以接受请求并将SUCCESS超文本传输协议状态返回给调用者。之后,根据过滤器出厂配置将其转发到目的地。 我在Spring doc中没有找到任何解决方案。有没有现有的过滤器工厂来实现这种模式?如果没有,那么有什么建议如何解决这个问题? 注意:我们想要中断Spring Cloud Gateway通信的原因是目标服务器响应时间非常高,呼叫者不能等待那
-
无法连接谷歌存储文件使用GSC连接器从火花
我写了一个火花作业在我的本地机器,从谷歌云存储读取文件使用谷歌hadoop连接器,如gs://storage.googleapis.com/https://cloud.google.com/dataproc/docs/connectors/cloud-storage 我已经设置了具有计算引擎和存储权限的服务号。我的火花配置和代码是 我已经设置了环境变量也称为GOOGLE_APPLICATION_C
-
 基于火力的电话身份验证上的应用验证错误
基于火力的电话身份验证上的应用验证错误我已经制作了我的应用程序,并将其发布到谷歌游戏商店。我使用Firebase Phone Authentication验证成员,在我将其发布到play商店之前,它运行良好,但当我从google play下载它时,它抛出一个错误: (此应用程序未被授权使用Firebase Authentification。请验证Firebase控制台中配置了正确的包名和SHA-1。[应用程序验证失败]) 我还在goo
-
火花是否支持镶木地板格式的多个输出文件
业务案例是,我们希望通过一个列作为分区,将一个大的拼花文件分割成多个小文件。我们已经使用data frame . partition(“XXX”)进行了测试。写(...).用了大约1个小时,记录了10万个条目。因此,我们将使用map reduce在不同的文件夹中生成不同的拼花文件。示例代码: 上面的例子只是生成一个文本文件,如何用multipleoutputformat生成一个parquet文件?
-
数据存储在火库实时数据库中的错误字段中
< code >在此输入代码我在android应用程序中有一个注册表,用户可以在其中输入他们的详细信息。我尝试将数据存储到firebase中,数据正在存储,但问题是电话号码、年龄和姓名都将被存储。如何解决这个问题?请帮帮忙! 助手类 公共类UserHelperClass { } 数据存储到Firebase代码 从其他活动获取数据 将数据传递给另一个活动 公共类注册活动扩展了应用程序兼容性活动 {
-
火花在本地运行,但在纱线运行时找不到文件
我一直试图提交一个简单的python脚本,以便在一个带有Yarn的集群中运行它。当我在本地执行作业时,没有问题,一切都很好,但当我在集群中运行它时,它就失败了。 诊断:文件不存在:hdfs://myserver:8020/user/josholsan/.sparkstaging/application_1510046813642_0010/test.py 我不知道为什么它找不到test.py,我也
-
使用火花 udf 在斯卡拉的范围内进行模式匹配
我有一个包含字符串的Spark数据帧,我使用Likert量表将这些字符串与数字分数进行匹配。不同的问题id对应不同的分数。我尝试在Apache Spark udf中的Scala范围内进行模式匹配,使用这个问题作为指导: 如何在Scala的一个范围内进行模式匹配? 但是当我使用范围而不是简单的OR语句时,我遇到了编译错误,即 <code>31|32| 33|;34 无法编译。任何想法,我在语法上出错
-
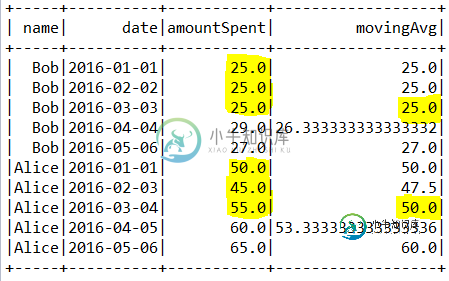 用火花窗函数计算移动平均时丢弃前几个值
用火花窗函数计算移动平均时丢弃前几个值我试图计算按名称分组的列的季度移动平均线,我定义了一个火花窗口函数规范为 我的数据frame如下所示: