
用火花窗函数计算移动平均时丢弃前几个值

我试图计算按名称分组的列的季度移动平均线,我定义了一个火花窗口函数规范为
val wSpec1 = Window.partitionBy("name").orderBy("date").rowsBetween(-2, 0)
我的数据frame如下所示:
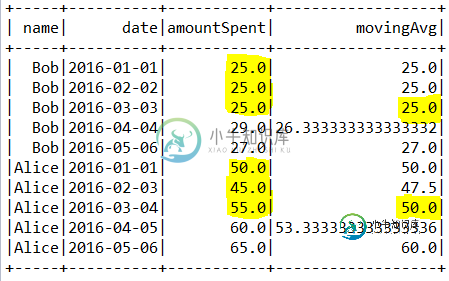
+-----+----------+-----------+------------------+
| name| date|amountSpent| movingAvg|
+-----+----------+-----------+------------------+
| Bob|2016-01-01| 25.0| 25.0|
| Bob|2016-02-02| 25.0| 25.0|
| Bob|2016-03-03| 25.0| 25.0|
| Bob|2016-04-04| 29.0|26.333333333333332|
| Bob|2016-05-06| 27.0| 27.0|
|Alice|2016-01-01| 50.0| 50.0|
|Alice|2016-02-03| 45.0| 47.5|
|Alice|2016-03-04| 55.0| 50.0|
|Alice|2016-04-05| 60.0|53.333333333333336|
|Alice|2016-05-06| 65.0| 60.0|
+-----+----------+-----------+------------------+
import com.datastax.spark.connector._
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.types.IntegerType
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
object Test {
def main(args: Array[String]) {
//val sparkSession = SparkSession.builder.master("local").appName("Test").config("spark.cassandra.connection.host", "localhost").config("spark.driver.host", "localhost").getOrCreate()
val sparkSession = SparkSession.builder.master("local").appName("Test").config("spark.cassandra.connection.host", "localhost").config("spark.driver.host", "localhost").getOrCreate()
val sc = sparkSession.sparkContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sparkSession.implicits._
val customers = sc.parallelize(List(("Alice", "2016-01-01", 50.00),
("Alice", "2016-02-03", 45.00),
("Alice", "2016-03-04", 55.00),
("Alice", "2016-04-05", 60.00),
("Alice", "2016-05-06", 65.00),
("Bob", "2016-01-01", 25.00),
("Bob", "2016-02-02", 25.00),
("Bob", "2016-03-03", 25.00),
("Bob", "2016-04-04", 29.00),
("Bob", "2016-05-06", 27.00))).toDF("name", "date", "amountSpent")
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
// Create a window spec.
val wSpec1 = Window.partitionBy("name").orderBy("date").rowsBetween(-2, 0)
val ls=customers.withColumn("movingAvg",avg(customers("amountSpent")).over(wSpec1))
ls.show()
}
}
共有1个答案

我建议只计算平均值,如果窗口包含精确的3行(即跨越整个范围-2到0)
val ls=customers
.withColumn("count",count(($"amountSpent")).over(wSpec1))
.withColumn("movingAvg",when($"count"===3,avg(customers("amountSpent")).over(wSpec1)))
ls.show()
+-----+----------+-----------+-----+------------------+
| name| date|amountSpent|count| movingAvg|
+-----+----------+-----------+-----+------------------+
| Bob|2016-01-01| 25.0| 1| null|
| Bob|2016-02-02| 25.0| 2| null|
| Bob|2016-03-03| 25.0| 3| 25.0|
| Bob|2016-04-04| 29.0| 3|26.333333333333332|
| Bob|2016-05-06| 27.0| 3| 27.0|
|Alice|2016-01-01| 50.0| 1| null|
|Alice|2016-02-03| 45.0| 2| null|
|Alice|2016-03-04| 55.0| 3| 50.0|
|Alice|2016-04-05| 60.0| 3|53.333333333333336|
|Alice|2016-05-06| 65.0| 3| 60.0|
+-----+----------+-----------+-----+------------------+
-
我也看过Pyspark中的加权移动平均线,但我需要一个Spark/Scala的方法,以及10天或30天的均线。 有什么想法吗?
-
问题内容: 美好的一天, 我正在使用以下代码来计算9天移动平均线。 但这是行不通的,因为它会在调用限制之前先计算所有返回的字段。换句话说,它将计算该日期之前或等于该日期的所有关闭时间,而不仅仅是最后9个。 因此,我需要从返回的选择中计算出SUM,而不是直接计算出来。 IE浏览器 从SELECT中选择SUM … 现在我将如何去做,这是非常昂贵的还是有更好的方法? 问题答案: 使用类似 内查询返回的所
-
公式链接:https://sciencing.com/calculate-exponential-moving-averages-8221813.html
-
我处理了像这样存储的双精度列表: 我想计算这个列表的平均值。根据文档,: MLlib的所有方法都使用Java友好类型,因此您可以像在Scala中一样导入和调用它们。唯一的警告是,这些方法采用Scala RDD对象,而Spark Java API使用单独的JavaRDD类。您可以通过对JavaRDD对象调用.RDD()将JavaRDD转换为Scala RDD。 在同一页面上,我看到以下代码: 根据我
-
问题内容: 我的数据集如下: 仅使用MySQL窗口函数可以做到这一点吗? 环境详细信息: 服务器版本:8.0.12 MySQL Community Server-GPL 问题答案: 您可以将Window Functions与Frames一起使用 : DB小提琴演示 细节: 表示当前行上方的两行(当前行除外)。我们在上明确定义了升序。因此,这意味着两个最接近的日期,低于当前行的日期 表示当前行。 使