《烽火星空》专题
-
木星测试期间未找到科特林test注释处理器生成的类
我正在为静态编程语言开发一个KSP注释处理器。代码在编译期间正确生成,我可以在输出目录中看到生成的类。现在我想通过JUnit和“com.github.tschuchortdev.KotlinCompilation”测试我的注释处理器。如果我调用编译方法,代码将被生成,我可以在Temp-Directory中看到生成的类,但如果我尝试加载类,那么我会得到一个“java.lang.ClassNotFou
-
Webview在android 11(三星设备)的app dual上运行时不调用任何回调
我的应用程序在android 11(三星设备)中作为应用程序dual运行时,webview出现问题。 当我加载如下url时: 我必须设置一个WebViewClient并覆盖一些方法,例如:onPageStarted、onPageFinished、onReceivedError……但没有调用回调。 注意:我的主应用程序工作正常,但它的双应用程序没有,它只在android 11中运行。 我有谷歌,但我
-
 三星半导体(西安)研究院 -- 算法工程师(计算机视觉方向)
三星半导体(西安)研究院 -- 算法工程师(计算机视觉方向)8.8 一面 英文自我介绍 项目介绍 单阶段目标检测和双阶段目标检测的区别 数据增强方法 Python如何实现二维数组 Python中的魔法方法 __new__()和__init__()的区别 装饰器和迭代器的区别 Python中的with语句 贪心算法和动态规划的区别 C++中main函数的参数的意义 C++的内联函数 Pytorch实现卷积 优先级队列的实现 mAP的计算原理 8.11 测评
-
 面经刺客 | 字节抖音星图达人营销产品 日常实习面经
面经刺客 | 字节抖音星图达人营销产品 日常实习面经上午结束最后一场期末作业答辩。下午四点,躺在床上,还没睡醒就接到了六点半的面试邀约。迷迷糊糊中接完,才突然想起接了面试邀约意味着我的流程就被锁了,会影响深圳这边的投递。感谢面试官最后没选我(bushi 遇到的面试官态度非常好,甚至跟我介绍了字节,解释了面试流程,明确表示有横向比较环节并给出反馈时间。就是可惜挂了哈哈。 个人背景 深圳大学23届计算机本科+网络与新媒体双学位,准备留学申is/cs/d
-
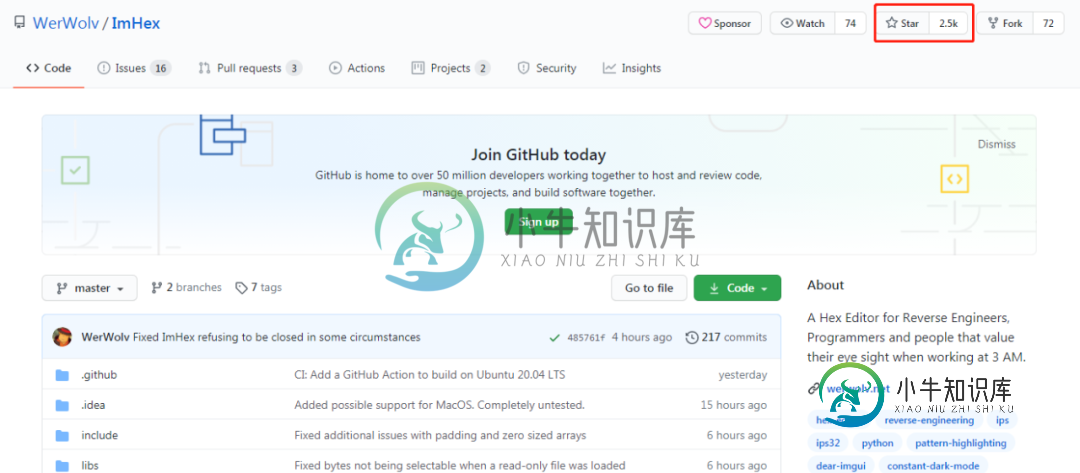 21 岁理工男开源的这个编辑器火遍全球附面试资源
21 岁理工男开源的这个编辑器火遍全球附面试资源本文向大家介绍21 岁理工男开源的这个编辑器火遍全球附面试资源,包括了21 岁理工男开源的这个编辑器火遍全球附面试资源的使用技巧和注意事项,需要的朋友参考一下 来自:机器之心 最近在 GitHub 上最火的项目是一个对视力友好的十六进制编辑器,它上线仅 5 天就收获了 2500 star,最近 24 小时涨了 1600 star 量。 十六进制编辑器是用于编辑单个字节数据的软件应用程序,主要由程序
-
火花:如何使用映射分区和创建/关闭每个分区的连接
所以,我想对我的spark数据帧执行某些操作,将它们写入DB,并在最后创建另一个数据帧。看起来是这样的: 这给我一个错误,因为map分区期望返回的类型,但这里是。我知道这在forEach分区中是可能的,但我也想做映射。单独做会有开销(额外的火花工作)。该怎么办? 谢谢
-
使用Livy提交Spark作业时出错:用户未初始化火花上下文
我对Spark非常陌生,我正在遵循此文档通过Livy提交Spark jobshttps://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-livy-rest-interface 这是我的命令: 文件test4sparkhaha.jar是一个超级简单的Java应用程序,它只包含一个类,只有一个打印“哈哈哈”的主方法,没有别的.
-
2017年直播答题非常火爆,你能分析一下原因和目的吗
本文向大家介绍2017年直播答题非常火爆,你能分析一下原因和目的吗相关面试题,主要包含被问及2017年直播答题非常火爆,你能分析一下原因和目的吗时的应答技巧和注意事项,需要的朋友参考一下 1.低门槛高奖金、强调用户互动参与。 2.直播行业亟待新的变现模式。用户留存度低、活跃度下降、盈利模式单一的直播行业急需注入新的血液,而“直播答题”的出现就成为直播行业新的转折点。 3.增强营销实效,精准定位消费
-
 我无法确定AWS IAM中缺少允许编辑防火墙规则的权限
我无法确定AWS IAM中缺少允许编辑防火墙规则的权限我正在尝试创建一个策略,无论我尝试哪种变体,它都不起作用。 我只是希望用户能够在安全组中编辑入站/出站规则。我最终放弃了指定资源的尝试,只是为了排除这一原因。 我可以确认用户已正确添加到策略中,因为作为测试,我为用户提供了对所有内容的所有权限,并且它运行良好并显示了入站规则。 我甚至尝试了AWS文档,它告诉我一些权限甚至不存在:https://docs.aws.amazon.com/AWSEC2/
-
我得到一个java.lang.NoClassDefFoundError当我试图运行单词计数的例子在火花
我正在尝试运行Spark网站上的单词计数示例(http://spark.apache.org/docs/latest/quick-start.html)在Scala Spark中,但是当我尝试Spark提交时,我得到了一个例外:java。lang.NoClassDefFoundError:scala/runtime/LambdaDeserialize Spark版本为2.0。1,Scala版本是2
-
在运行火花作业时,根据公平的份额,纱线不抢占资源
我在重新平衡YARN Fair计划队列上的Apache Spark jobs资源时遇到了一个问题。 在测试中,我配置了Hadoop2.6(也尝试了2.7)在macOS上使用本地HDFS以伪分布式模式运行。对于工作提交使用“预构建Spark1.4用于Hadoop2.6和更高版本”(尝试1.5也)从Spark的网站分发。 在Hadoop MapReduce作业上使用基本配置进行测试时,Fair Sch
-
云火如何找到包含特定文档ID的子集合的所有文档?
我试图实现一种在Firestore中保持一致性的方法,但我需要一种找到重复数据存在的所有位置的方法。firestore中是否有方法查找其子集合包含具有特定文档ID的文档的所有文档?例如对于以下结构 我将使用什么查询来查找其“朋友”列表包含文档 ID 为 5678 的文档的所有用户 ID?例如,当用户 5678 决定更改他/她的姓名时?
-
为什么火花提交失败的'spark.yarn.stagingDir'与主纱线和部署模式集群
我在提供spark.yarn时遇到了一个场景。stagingDir(stagingDir)到spark submit(spark提交)开始失败,它没有给出任何关于根本原因的线索,我花了很长时间才弄清楚这是因为spark.yarn(spark.yarn)。stagingDir参数。为什么spark submit在supply此参数? 在此处查看相关问题以获取更多详细信息 失败的命令: 当我移除火花线
-
对存储在卡桑德拉数据库上的 JSON 对象进行查询火花
我在cassandra DB上构建了结构来存储操作系统数据的时间序列数据,如服务、进程和其他信息。为了理解如何使用Cassandra来存储JSON数据并通过条件的CQL查询检索数据,我倾向于简化模型。因为在整个模型数据库中,我将拥有比report_object更复杂的类型,如hashMap数组的hashMap,例如:Type
-
与Azureendpoint建立的网络连接是否被防火墙或其他东西终止?
我在Windows Azure中开发了一个驻留在Windows Server 2012机器上的应用程序。应用程序充当许多并发网络连接的服务器,但流量非常低且稀少(客户机每隔几个小时才发送一次信息,但它们确实需要时刻连接,以便接收服务推送的更新)。 在没有流量的情况下几分钟后,客户机/服务器通信似乎被冻结,客户机和服务器之间没有流量流动。实际上,30-60秒后,客户端尝试发送一些东西,他们显示连接已