《差旅壹号》专题
-
spark shell和spark sql有什么区别?有什么性能差异吗?
Spark shell:它基本上打开了scala spark sql:它似乎直接连接到hive元存储,我们可以用类似于hive的方式编写查询。并查询配置单元中的现有数据 我想知道这两者的区别。。在spark sql中处理任何查询是否与在spark shell中相同?我的意思是,我们可以在spark sql中利用spark的性能优势吗? Spark 1.5.2在这里。
-
为什么JIT在清除绑定支票方面做得这么差?
我正在测试热点JIT数组绑定检查消除能力。下面是相同heapsort实现的两个版本,一个使用普通数组索引,另一个API,没有绑定检查: 在Intel SB和AMD K10 CPU上,不安全版本的速度始终保持在13%以上。 我查看了生成的程序集: 消除所有索引操作的下界检查(1-8) 仅对操作5消除上限检查,合并2和3的检查 是,对于每次迭代的操作4(),检查 我认为这绝对是JIT的工作优化绑定检查
-
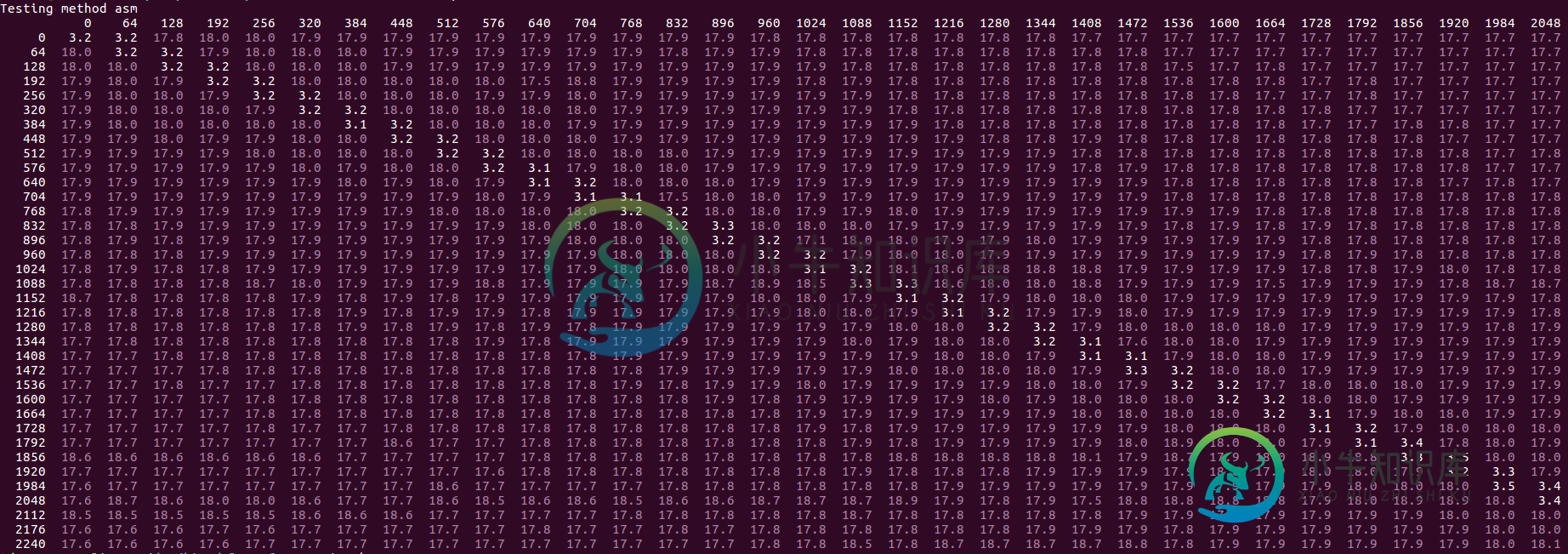 Intel Skylake上存储循环的双峰性能出乎意料的差
Intel Skylake上存储循环的双峰性能出乎意料的差我看到一个简单的存储循环的性能出乎意料的差,它有两个存储:一个是16字节的前进步幅,另一个总是在同一个位置1,如下所示: 在程序集中,此循环3可能如下所示: 当访问的内存区域在L2中时,我希望它在每次迭代中运行少于3个周期。第二个商店只是不断击中相同的位置,应该增加大约一个循环。第一个存储意味着从L2引入一行,因此每4次迭代也会逐出一行。我不确定如何评估L2成本,但即使保守地估计L1每个周期只能执
-
请问如何使用git diff 对比两个文件的差异呢?
请问如何使用git diff 对比两个文件的差异呢? 我从1.txt 复制内容到2.txt 并修改了内容信息, 我想要使用git diff 它们,输出差异的位置信息。 但是我执行如下的命令: 没有得到任何响应内容。
-
python - django中存储到数据库的时间,差好几个小时?
模型存储时间用的是: 使用auto_now_add存储到数据之后和当前(我用的windows)时间差了8个小时,setting.py配置文件如下: 网上查询的资料中说关闭USE_TZ可以,但是发现并不行,关闭USE_TZ=False之后,时差变成了14个小时。
-
为什么这个代码输出零而不是最大的差异(这是7,因为它是后续值之间的最大差异,而不是所有值)?
这是我的代码,当它应该输出7时,它输出0。非常感谢您在这里提供的任何帮助(我必须使用continue和for语句,不允许使用while语句作为必需品)。
-
某旅游产品目前存在这样一个问题:去马尔代夫旅行的订单,常常发现带儿童客人忘了选儿童需要的早餐附加费,导致到了酒店需要额外补比较多的差价。现在需要就此问题进行改进并且评估上线结果。如果你是后台产品经理,你会如何执行此项任务?说明你的步骤。
本文向大家介绍某旅游产品目前存在这样一个问题:去马尔代夫旅行的订单,常常发现带儿童客人忘了选儿童需要的早餐附加费,导致到了酒店需要额外补比较多的差价。现在需要就此问题进行改进并且评估上线结果。如果你是后台产品经理,你会如何执行此项任务?说明你的步骤。相关面试题,主要包含被问及某旅游产品目前存在这样一个问题:去马尔代夫旅行的订单,常常发现带儿童客人忘了选儿童需要的早餐附加费,导致到了酒店需要额外补比
-
CSS网格布局中的百分比和fr单位之间的差异
问题内容: 我在玩CSS网格布局,遇到一个我找不到答案的问题。 考虑以下示例: 如您所见,由于使用设置了百分比宽度,因此列超出了屏幕宽度。 但是,如果我使用单位,则效果很好: 如果有人能解释为什么百分比宽度会产生如此大的影响,那将是很好的。 问题答案: 本机仅在容器的可用空间内工作。 因此,在您的代码中: …容器中的自由空间在12列之间平均分配。 由于列仅处理 自由空间 ,因此不是一个因素。在确定
-
2个日期与Joda时间之间的差值天数计算错误?
问题内容: 早上好, 我开发了一个android应用程序,我疯了!由于几天,我试图得到2个日期之间的差异天。 我在乔达时间就意识到了-这似乎行得通。 我将长sqlDate保存在数据库中。这是日期选择器的日期(以毫秒为单位)。 现在,我想通过查询请求此日期,并计算以毫秒为单位的日期与现在的日期之间的日期差。 我试试这个: 记录结果: 但这是错误的。例如: 这是SqlDate的结果-现在= 25919
-
通配符导入和必需的类导入之间的性能差异
问题内容: 两者之间的性能复杂度是多少 和 PS。 我知道第一个文件将包含每个文件,第二个文件将仅包含选定的类文件。 问题答案: 在运行时0。 两者都生成相同的字节码
-
Java用简单的语言解释协方差,不变性和相反性?
问题内容: 今天,我读了一些有关Java中协方差,协方差(和不变性)的文章。我阅读了英文和德文的Wikipedia文章,以及其他来自IBM的博客文章和文章。 但是我对这些到底是什么还是有些困惑?有人说这与类型和子类型之间的关系有关,有人说与类型转换有关,有人说它用于确定方法是被重写还是被重载。 因此,我正在寻找一个简单的英语解释,它向初学者展示了协方差和逆方差(以及不变性)。加号是一个简单的例子。
-
java for循环和for-each循环之间是否存在性能差异?
问题内容: 以下两个循环之间的性能差异(如果有)是什么? 和 问题答案: 版本1.5中引入的for-each循环通过完全隐藏迭代器或index变量,消除了混乱和出错的机会。结果成语同样适用于集合和数组: 当你看到冒号(:)时,将其读为“ in”。因此,上面的循环读为“对于元素中的每个元素e”。请注意,即使对于数组,使用for-each循环也不会降低性能。实际上,在某些情况下,它可能只比普通的for
-
Hibernate / JPA中注释字段或获取方法之间的性能差异
问题内容: 我很好奇是否有人在使用私有字段而不是公共获取方法注释实体之间的性能差异方面有任何困难的数字。我听说人们说字段变慢了,因为它们被称为“通过反射”,但是getter方法也是,不是吗?Hibernate需要它试图读它,我可以看到有一些前场的无障碍设置为true 轻微的 开销。但是,这不是在Session范围内的类级别上完成,还是在读取Configuration并构建SessionFactor
-
两个日期之间的平均差异(按第三个字段分组)?
问题内容: 假设我们有3个领域, 用户启动和停止多个记录,例如下面的bob已启动和停止了两个记录。 我需要知道每个用户(即按用户分组,而不仅是每一行)的平均时间(即开始和结束之间的时间差),以小时为单位。 我不太了解如何进行差异,平均和分组?有什么帮助吗? 问题答案: 您没有为差异指定所需的粒度。这可以在几天内完成: 如果要以秒为单位,请使用: datediff可以通过更改第一个参数(ss,mi,
-
如何在Javascript中以mm-dd-hh格式获取两个日期的差
问题内容: 我可以使用moment.js或纯js获得两个日期之间的差异。 在moment.js中 一个月返回一个月,多个天返回以天为单位的差异。但是我想要答案 MM-DD-hh格式例如2个月12天5小时。我不能直接转换日期,因为还有leap年等其他问题。还有什么其他办法可以全力以赴并计算一切吗?我在angular js中这样做,如果有帮助 问题答案: 要获得两个日期之间的精确差并不容易,因为年,月